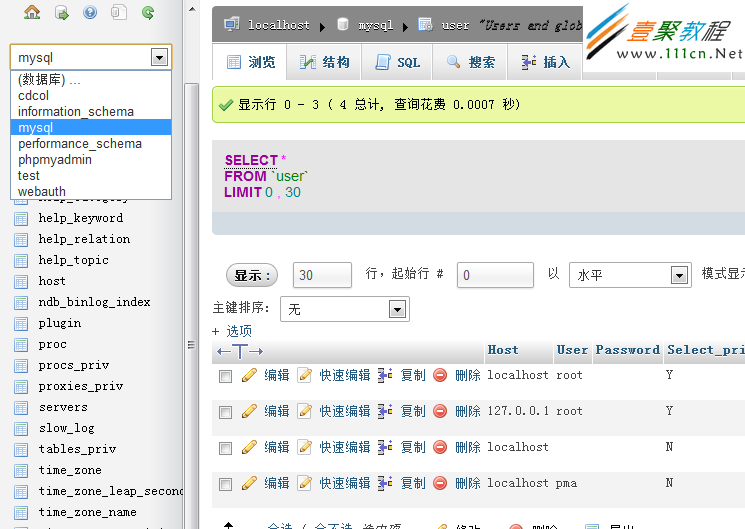
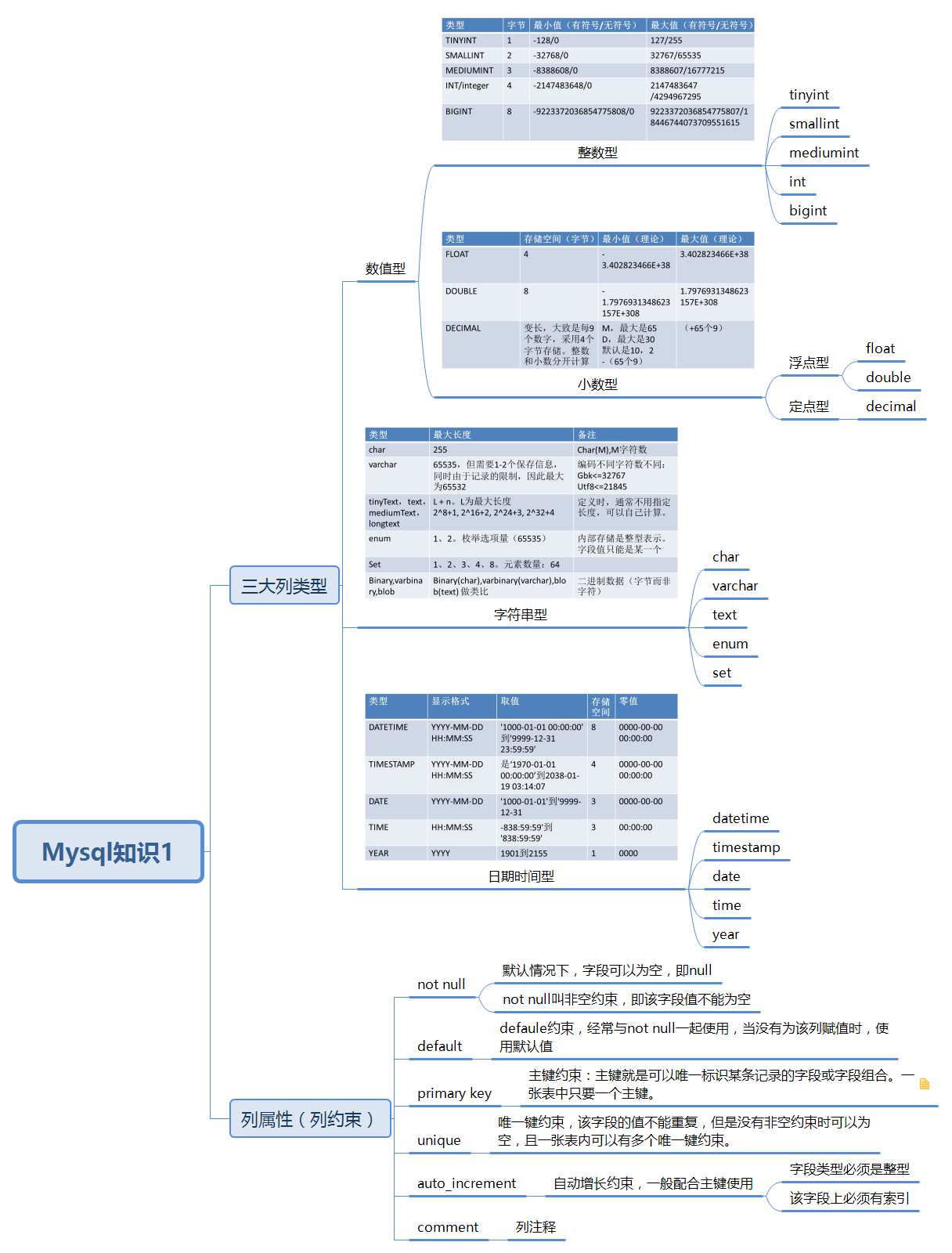
圖片和資料來源於MYSQL大牛姜承堯老師(MYSQL技術內幕作者)
姜承堯: 網易杭州研究院 技術經理 主導INNOSQL的開發
數據庫的可靠指的是數據可靠
數據庫可用指的是數據庫服務可用
可靠的是數據:例如工商銀行,數據不能丟失
可用的是服務:服務器不能宕機
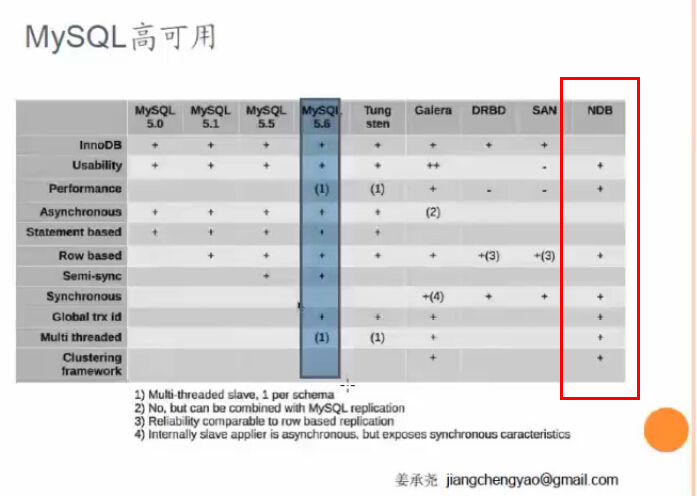
靈活運用MYSQL的各種高可用技術來達到下面各種級別的高可用要求
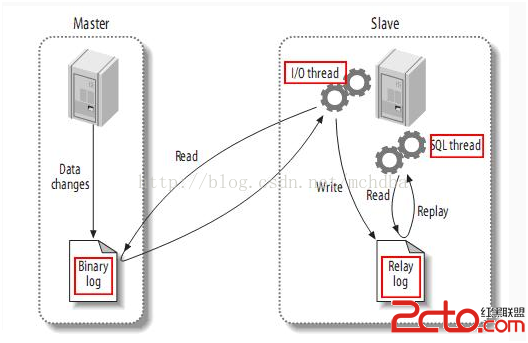
要達到99.9%:使用MYSQL復制技術
要達到99.99%:使用MYSQL NDB 集群和虛擬化技術
要達到99.999%:使用shared-nothing架構的GEO-REPLICATION和NDB集群技術
Gluster Geo-replication是什麼?
Gluster Geo-replication(簡稱geo-replication)是一種異地災備技術,
它主要應用於把集群中的一個存儲,近乎即時地(near real-time)透過公網(wan)備份到遠端的機房
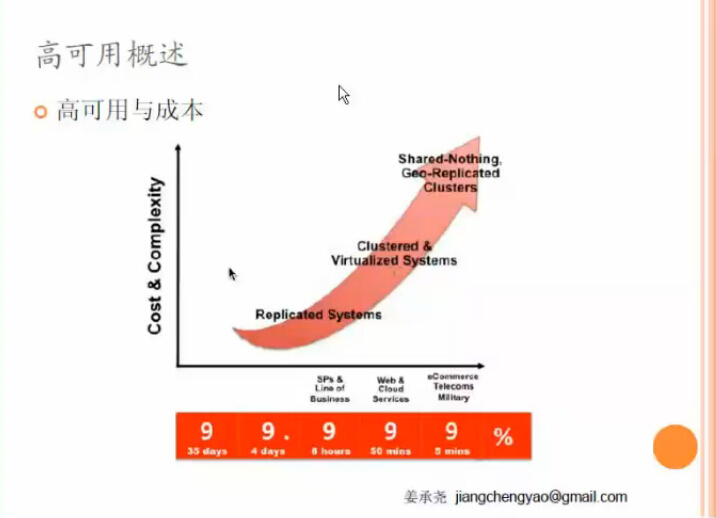
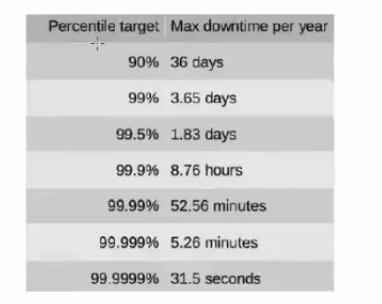
各種高可用級別允許的宕機時間
DRBD:網絡磁盤的RAID1

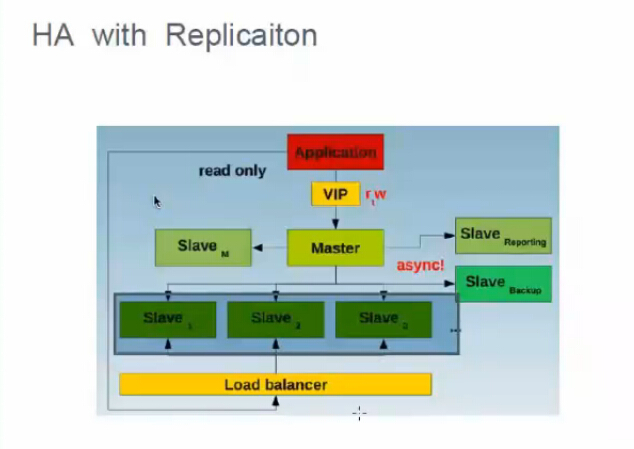
方案一:MYSQL主從復制(單活)
投票選舉機制,較復雜
MySQL本身沒有提供replication failover的解決方案,自動切換需要依賴MHA腳本
可以有多台從庫,從庫可以做報表和備份

方案二:雙主(單活),failover比單主簡單
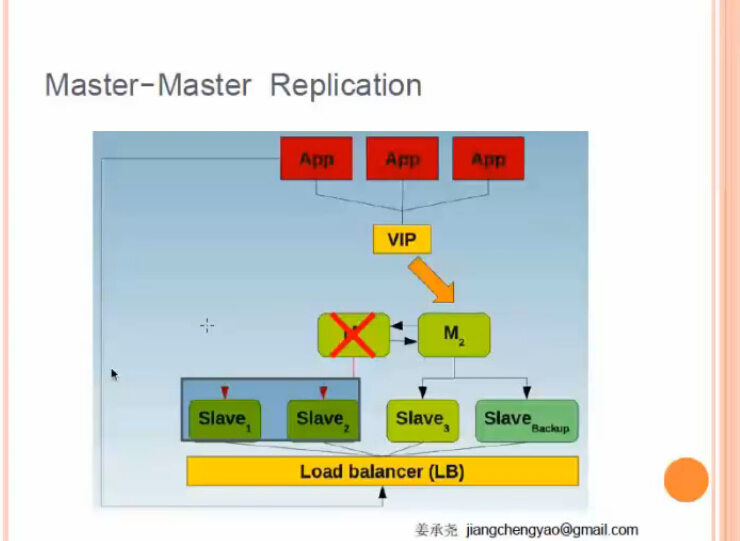
同樣,自動切換需要MMM腳本
缺點是某個主掛掉了,他下面的slave同樣掛掉

方案三:雙主配SAN存儲(單活)
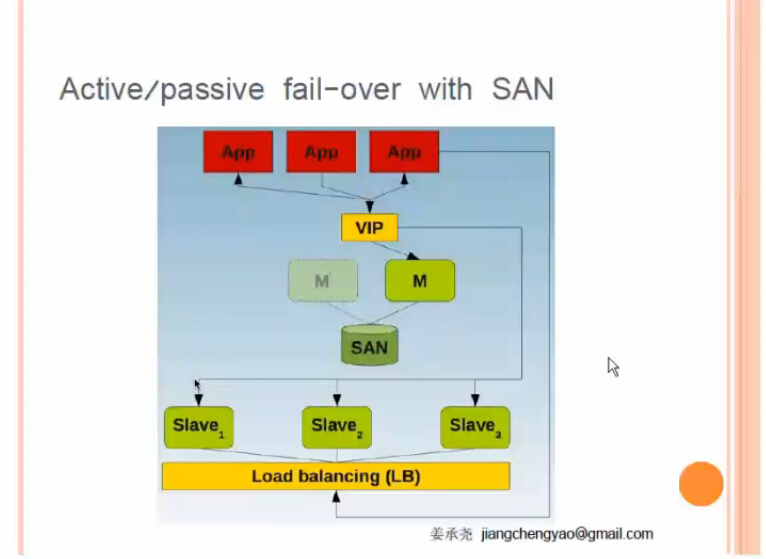
這個架構跟方案二是一樣的,只不過兩個master之間不需要同步數據,因為他們用的是共享磁盤
這個方案是有錢人方案,無論哪個主掛掉都不會引起其他的slave掛掉,但是SAN存儲死貴。。
像通信行業中國聯通這些公司有用到
某個主掛掉了,下面的slave不會掛掉
注意:failover之後不會預熱,數據沒有預先加載到內存中,切換之後一段時間內存儲會有一定的性能影響

方案四:DRBD 雙主配DRBD (單活)
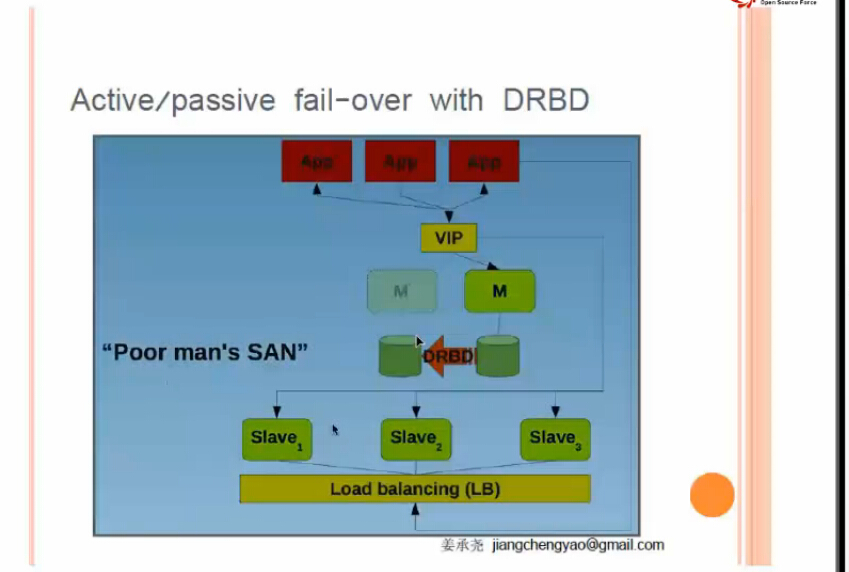
結構跟方案三一樣,唯一不同的是沒有使用SAN網絡存儲 ,而是使用local disk
由於是實時復制磁盤數據,性能會有影響
人們把DRBD稱為“屌絲的SAN”
POOR MAN'S SAN:窮人的SAN

方案五:NDB CLUSTER
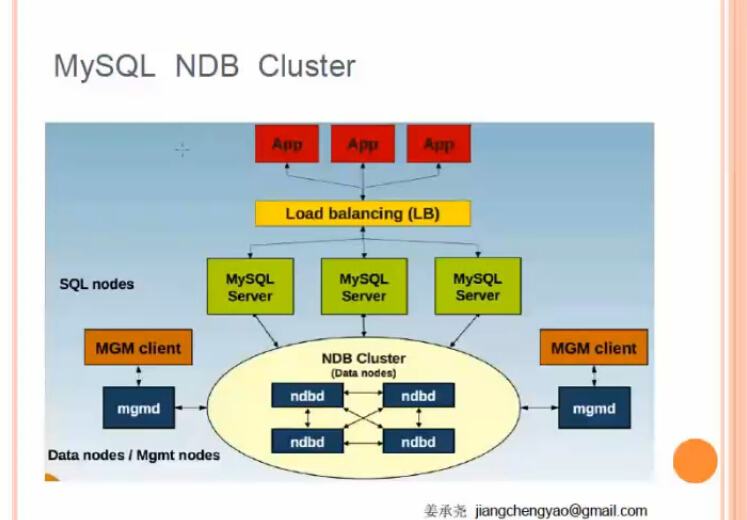
國內用NDB集群的公司非常少,貌似有些銀行有用
NDB集群不需要依賴第三方組件,全部都使用官方組件,能保證數據的一致性
某個數據節點掛掉,其他數據節點依然可以提供服務
管理節點需要做冗余以防掛掉
缺點是:管理和配置都很復雜,而且某些SQL語句例如join語句需要避免


方案六:第三方的Tungsten軟件
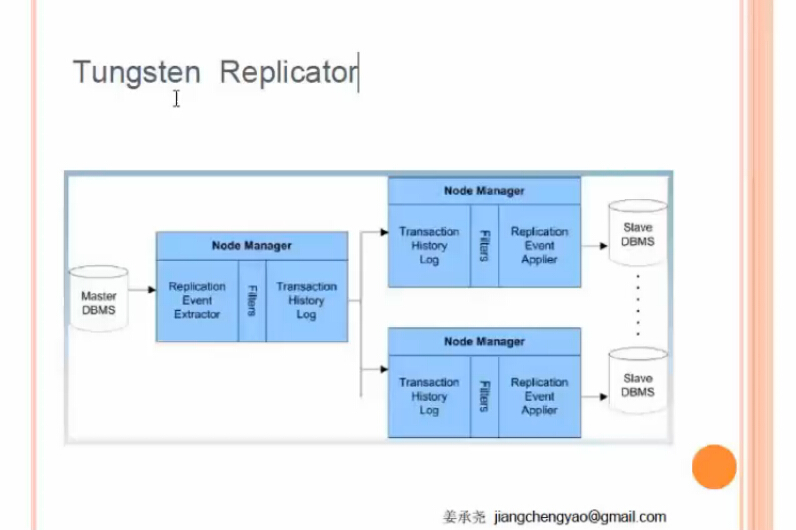
使用java編寫,不是MYSQL內置的
同樣是MYSQL數據庫復制,不過他不是用MYSQL內置的組件來做的
不但支持MYSQL數據庫復制也支持異構數據庫的復制,而且對異構數據庫復制支持較好,例如MYSQL復制到ORACLE
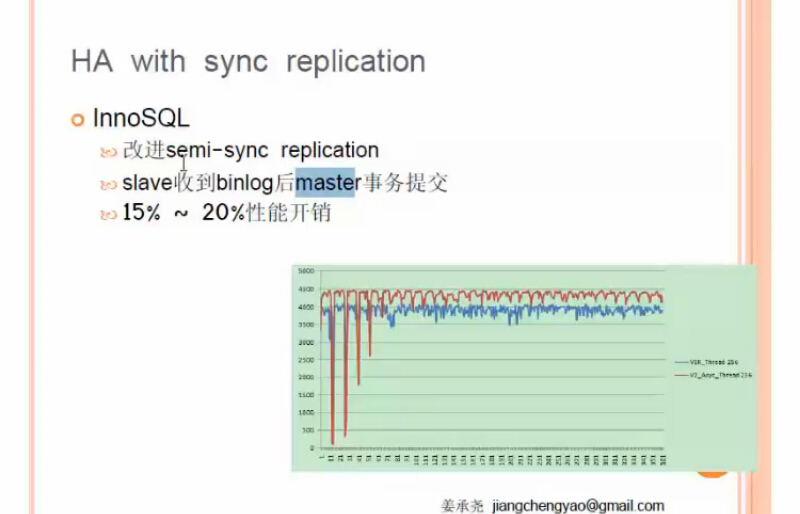
方案七:網易的INNOSQL
類似於SQLSERVER的鏡像高安全模式
High Safety 模式 (也就是同步模式)沒有 witness服務器
數據庫在Principle的事務,需要馬上得到mirror的確認,才能完成。這種情況下,Mirror和Principle的數據是同步的。
但是因為所有的事務需要mirror的確認,所以性能可能會有所影響。
區別:innosql的slave可以讀,鏡像的slave(從庫)不可讀
保證數據不會丟失,數據的高可靠性
mysql5.7開始支持這種模式
總結
每種方案都有不同的特點,配置和應用場景也各有不同
有些偏向於成本低的,有些偏向於成本高的,有些偏向於數據的可靠性,有些則偏向於數據庫的可用性
反正各個方案都各有優缺點,DBA要結合自己公司的業務情況進行選擇合適自己業務情況的高可用方案
更多參考資料:
讀寫分離:Amoeba
Ubuntu10下MySQL搭建Amoeba系列(文章索引)
集群技術:數據庫集群技術漫談
Gluster Geo-replication工作原理
如有不對的地方,歡迎大家拍磚o(∩_∩)o
像MS SQL Server和DB2和Oracal和Access一樣是你在建設動態網站時所用到的數據庫,他是免費的
只列id的話:
select char_id from 表名 goup by char_id having sum(money)=20
把那些條數據都顯示出來的話
select * from 表名 where char_id in (
select char_id from 表名 goup by char_id having sum(money)=20
)
----------補充--------
你寫的跟我不一樣啊,
我group by char_id了,你是要查=20的還是大於等於20的?