select 選項子句 [ all | distinct ]
這個參數主要影響查詢結果是否包含重復記錄
All:代表保留所有的記錄,這個默認選項,可以省略不寫
Distinct:代表去除重復的記錄
格式:select all|distinct 字段表達式 from...;
from子句
格式:from 數據表
FROM子句用於指定要查詢使用的數據源
數據表可以有多個,中間用逗號分開,數據表也可以起別名
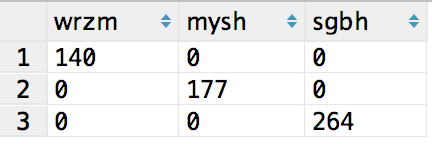
如果數據源是兩個表時,結果會是一個交叉連接的方式,記錄數相當於笛卡爾積
兩個表的數據總和=表1的記錄數*表2的記錄數
寫*時,字段名總數是兩個表的字段數量的和
數據表也可以起別名,還可以加條件
WHERE子句
功能是進行數據的篩選過濾。
格式:where 條件表達式
條件表達式使用關系運算符和邏輯運算符
關系運算符
> 大於
< 小於
>= 大於等於
<= 小於等於
!= 不等於
<> 不等於
= 等於
邏輯運算符
&& and 與
|| or 或
! not 非
Xor 異或
運算符存在優先級的問題
在where子句中不能使用字段的別名
GROUP BY子句
主要用於分組。通常在字段表達式中使用分組函數。
格式:group by 字段1 [asc|desc], 字段2 [asc|desc], ……
排序不寫默認是asc正序
使用count(*)和count(字段名)時,注意字段的值為null的問題
count(字段名)統計時,會把值為null的記錄忽略掉!
HAVING子句
它用於對查詢出來的結果進行再次的過濾。
比較顯著的就是如對分組查詢出來的結果再次使用條件。
省略where和group by子句時,不等於having就是where
不能把where放到having的位置
主要用於對數據進行排序。
格式:order by 字段1 [asc|desc], 字段2 [asc|desc], ……
Asc代表正序,它是默認選項,不寫就是asc
Desc代表倒序
當用一個字段做排序時,如果出現針對排序字段相同的記錄時,會隱含去使用主鍵進行第二排序
這個子句是做分頁的。
格式:limit 起始記錄位置, 記錄數
注意:如果省略起始記錄位置,只給出記錄數,表示從第一條數據開始取內容
Limit 10 相當於 limit 0, 10
提示:記錄的位置是從0開始計算的