常用的字符集包括ASCII ,GB2312 , GBK , UTF-8 ,Unicode
首先要知道

ASCII編碼:
用一個字節來標識0-9的數字、大小寫字母、及一些標點和不可見字符。1個字節8位,可以有256種組合。標准的ASCII編碼只利用一個字節的後7位(128種組合),最高位用作奇偶校驗。
范圍為0000 0000 - 0111 1111 即 0-127
因為ASCII最多只有256種組合,中國漢字成千上萬,所以需要更多的字節來表示一個漢字,常見中文編碼的有GB2312和GBK。
GB2312編碼:
是中國計算機的本地編碼方式,用兩個字節來表示一個漢字。為了兼容ASCII編碼,這兩個字節的取值范圍都不在0-127,而是在128-255之間。則GB2312理論上最多有128*128=16384種組合。足夠表示常用的漢字。
現有以下幾個數,每個數表示一個字節,問哪些是GB2312編碼,哪些是用ASCII編碼?數字只是隨便舉的
128 200 65 189 178 23 213 186
128 200 因為兩個字節都在128-255之間,所以是用GB2312編碼的漢字
65 一個字節在0-127之間,所以是用ASCII編碼的,實際表示的是小寫字母‘a’。
189 178 同理是用GB2312編碼的漢字
213 186 也是用GB2312編碼的漢字
GBK編碼:
是GB2312的升級版,收容了更多的漢字。它也是用兩個字節表示漢字,第一個字節的理論范圍依舊是128-255之間,但第二個字節范圍變為0-255。理論上最多能表示128*256種組合。同樣能兼容ASCII編碼。
比如
128 65 65 189 178 23 213 186
因為128不在0-127之間,所以從128開始的2個字節表示的是一個漢字
65在0-127,所以用一個字節表示小寫字母‘a’。
189 178 同理189不在0-127之間,表示的是一個漢字
213 186 同理213 不在0-127之間,表示的是一個漢字
Unicode字符集:
Unicode其實只是相當於一張表,用4個字節給去全世界的文字進行了編號。
UTF-8編碼:
UTF-8和Unicode的關系,相當於壓縮文件與源文件的關系,UTF-8用來壓縮Unicode。UTF-8是變長編碼,理論上用1到6字節來表示一個字符。

最高位是0的,用1個字節來表示一個字符
最高位有n個連續的1,則用個n個字節表示一個字符。
MySql亂碼問題:
亂碼問題有兩種可能:1、解碼與對應的編碼不匹配。2、數據損壞。
第一種是可以解決的,第二種數據已損壞無法還原。
對於第一種情況,要先了解MySql的各個環節
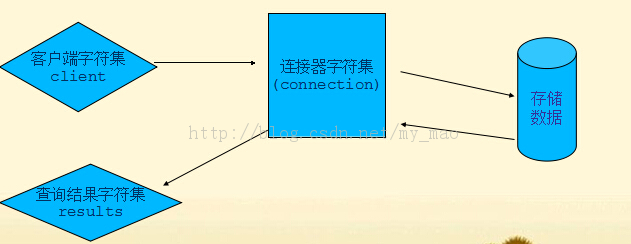 數據庫存儲數據的編碼方式不一致,則接著轉換成數據庫存儲數據的編碼方式。同理,當返回結果時,數據庫數據比對連接器編碼,不一致則轉成連接器編碼,再比對連接器編碼與結果集編碼,不一致則轉換成結果及編碼。
數據庫存儲數據的編碼方式不一致,則接著轉換成數據庫存儲數據的編碼方式。同理,當返回結果時,數據庫數據比對連接器編碼,不一致則轉成連接器編碼,再比對連接器編碼與結果集編碼,不一致則轉換成結果及編碼。
總而言之,只要客戶端、連接器、結果集編碼保持一致,大部分情況是不會出現亂碼的。
可以通過
set character_set_client = 編碼方式;設置客戶端編碼
set character_set_connection=編碼方式; 設置連接器編碼
set character_set_results=編碼方式; 設置接結果集編碼
這三句話也可以簡化為一句:set names 編碼方式