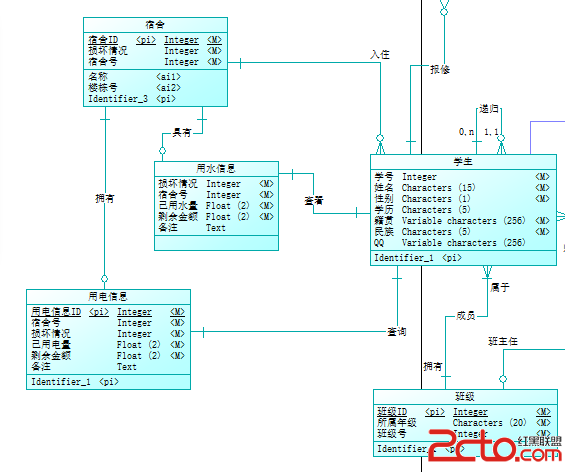
場景:
主庫DB:utf8字符集
備庫DB:gbk字符集
需求:
校驗主備數據是否一致,並且修復
校驗過程:
設置主庫連接為utf8,設置備庫連接為gbk,分別進行查詢,將返回的的結果集按記錄逐字段比較。
顯示結果:
原本相同的漢字字符,數據校驗認為不一致。
原因分析:
對於主庫而已,由於建立連接的字符集為UTF8,則返回的漢字字符編碼為UTF8格式;對於備庫而言則是GBK格式,而程序中通過字符串比較函數strcasecmp進行比較,顯然不同的字符集編碼,相同的字符有不同的二進制,因此結果肯定不會相等。
進一步分析:
那麼對於這種情況,建立連接應該采用哪種字符集呢?GBK or UTF8。其實選擇任何一種字符集都是OK的,只要是訪問主庫和備庫的字符集保持一致即可,唯一的區別在於,若選擇的字符集與客戶端的字符集不一致,可能導致無法正常顯示字符,即字符顯示為亂碼。
我們以客戶端的字符集為例,詳細說說三種情況:【這裡的客戶端可以認為是SecureCRT】
備注:綠色框代表DB字符集,黃色框代表連接字符集,橙色框代表客戶端
第一種情況:
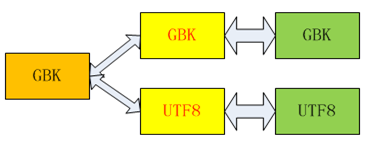
就是上述的情況,主庫返回字符的GBK編碼,備庫返回字符的UTF8編碼,因此進行字段比對,則會出現誤差。
第二種情況:
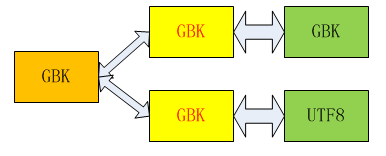
訪問主庫的連接不變,備庫連接由UTF8變為GBK,因此進行返回時,數據庫會將DB的字符集轉為GBK返回給客戶端,那麼對於客戶端而已,相同字符都是通過GBK編碼表示,因此二進制相等,校驗結果正確。
第三種情況:
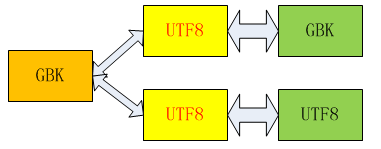
訪問主庫和備庫的連接都是UTF8,因此對於主庫而已,返回給客戶端的字符編碼由GBK轉為UTF8,此時主庫和備庫都是UTF8編碼,校驗結果正確。但由於客戶端實質是GBK編碼方式顯示,因此返回的漢字字符都是亂碼,但不影響校驗結果的正確性。
修復:
既然選擇與主備庫任一一個相同的字符集去訪問,都不會影響校驗結果的正確性,那麼影響修復呢?由於UTF8的編碼范圍比GBK編碼范圍要大,因此若采用GBK連接訪問UTF8編碼DB,有可能出現部分字符GBK不能表示的情況。
我們拿第二種情況說明,此時主庫為GBK,備庫為UTF8,使用GBK訪問UTF8。假設存在UTF8轉為GBK過程中部分字符丟失,這時候主備庫肯定是不一致的,因為存在部分字符GBK無法表示。 假設修復語句如下:
Update t set c1=master_value where c1=slave_value and id=?
其中t表示表名,id是主鍵表示某一行,master_value為主庫c1列的值,slave_value為備庫c1列的值。此時,slave_value由於UTF8轉為GBK已經丟失,因此語句執行最終影響0行記錄,無法修復。
結論:
客戶端訪問兩個不同字符集庫進行數據校驗時,連接采用表示范圍更大的字符集。比如我們常用的字符集表示范圍如下:
Latin<gb2312<gbk<utf8
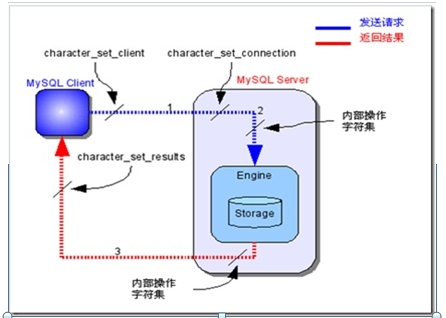
附:mysql客戶端與服務器通信時字符集編碼轉換流程
相關參數:
– character_set_client:客戶端來源數據使用的字符集
– character_set_connection:連接層字符集
– character_set_results:查詢結果字符集
– character_set_database:當前選中數據庫的默認字符集
– character_set_system:系統元數據(字段名等)字符集
1.客戶端請求服務器
1)將client的字符集轉為connection字符集
2)將connection字符集轉為DB內部的字符集
2.服務器返回結果給客戶端
1)將DB內部字符集轉為connection字符集
2)將connection字符集轉為character_set_results字符集
3.設置字符集命令:set names 字符編碼
指定客戶端與服務器通信的字符集,包括請求與返回。
SET NAMES 'x' 等價於:
SET character_set_client = x;
SET character_set_results = x;
SET character_set_connection = x;
附圖: