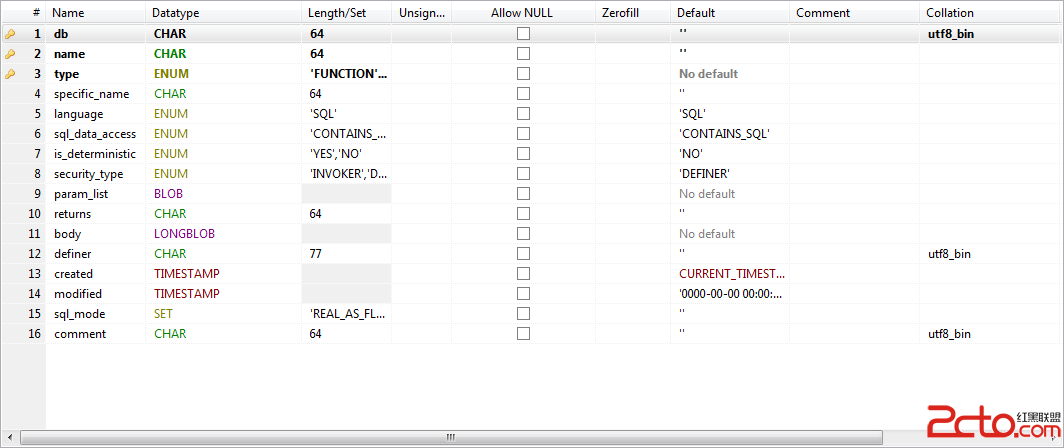
explain
select t.order_sn, t.cust_code, ti.tms_order_other_info_id, sp.province_name, sc.city_name, sr.region_name, st.town_name, t.buyer_address
from tms_order t inner join tms_order_other_info ti on t.tms_order_id=ti.tms_order_id
inner join crm_cust c on t.cust_code=c.cust_code
left join sb_province sp on t.buyer_state=sp.province_code
inner join sb_city sc on t.buyer_city=sc.city_code
inner join sb_region sr on t.buyer_area_id=sr.region_code
left join sb_town st on t.buy_town = st.town_code
where t.created_office = 'VIP_NH' and c.created_office='VIP_NH'
#and (t.cust_code='NHLDP053' or 'NHLDP053' = '' )
and t.is_autopicked in (1, 3)
and t.order_sub_type = 11
and t.order_status in (1,2)
and t.cust_code is not null
and t.add_time > date_sub(now(),interval 10 day)
and c.is_showpoint = 1 and ifnull(ti.has_matchpoint, 0) = 0
order by t.cust_code, t.created_dtm_loc limit 500

上面的tms_order等表,是千萬級數量數據.
上面的執行效率正常,執行計劃也正常,
而把left join sb_province sp 換成 inner join sb_province sp 後:: 效率就直線下降
explain
select t.order_sn, t.cust_code, ti.tms_order_other_info_id, sp.province_name, sc.city_name, sr.region_name, st.town_name, t.buyer_address
from tms_order t inner join tms_order_other_info ti on t.tms_order_id=ti.tms_order_id
inner join crm_cust c on t.cust_code=c.cust_code
inner join sb_province sp on t.buyer_state=sp.province_code
inner join sb_city sc on t.buyer_city=sc.city_code
inner join sb_region sr on t.buyer_area_id=sr.region_code
left join sb_town st on t.buy_town = st.town_code
where t.created_office = 'VIP_NH' and c.created_office='VIP_NH'
#and (t.cust_code='NHLDP053' or 'NHLDP053' = '' )
and t.is_autopicked in (1, 3)
and t.order_sub_type = 11
and t.order_status in (1,2)
and t.cust_code is not null
and t.add_time > date_sub(now(),interval 10 day)
and c.is_showpoint = 1 and ifnull(ti.has_matchpoint, 0) = 0
order by t.cust_code, t.created_dtm_loc limit 500
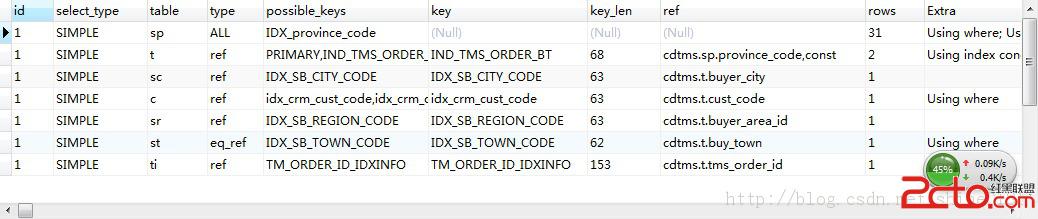
sp表的type就變成ALL了,並且執行效率直線下降,why?????
是因為inner join的方式 ,優化會執行的過程是這樣的:
另外:
發現除了st表使用eq_ref索引,其他的表卻使用ref索引, 就是說,st表的掃描比其他表的快...why???
是因為,sp表所引用的索引,它是一個uniqe key,
(eq_ref:從該表中會有一行記錄被讀取出來以和從前一個表中讀取出來的記錄做聯合。)
(ref: 該表中所有符合檢索值的記錄都會被取出來和從上一個表中取出來的記錄作聯合。)
(ref_or_null: 這種連接類型類似 ref,不同的是mysql會在檢索的時候額外的搜索包含null 值的記錄。這種連接類型的優化是從mysql4.1.1開始的,它經常用於子查詢。)
效率 eq_ref > ref > ref_or_null