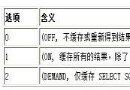
問題sql背景:項目有6個表的要根據pid字段要寫入對應的brand_id字段。但是這個其中有兩個表是千萬級別的。我的worker運行之後,線上的mysql主從同步立刻延遲了!運行了一個多小時之後,居然延遲到了40分鐘,而且只更新了十幾萬行數據。問題sql如下:
<!-- 根據商品id更新品牌id --> <update id="updateBrandIdByPid" parameterClass="com.jd.chat.worker.domain.param.UpdateBrandIdParam"> UPDATE $tableName$ SET brand_id = #newBrandId# WHERE pid = #pid# AND brand_id = 0 </update>項目組的mysql專家幫我分析了下,因為pid字段沒有索引,mysql引擎要逐行掃描出與傳入的pid值相等的列,然後更新數據,也就是要掃描完1000W+行磁盤數據才能執行完這個sql。更嚴重的是,這個千萬級的表裡面有多少個不同的pid,我就要執行多少個這樣的sql。
同事給我的建議的根據id字段進行sql代碼層次的縱向分表。每次更新1000行的數據,這樣mysql引擎就不用每次在掃全表了,數據庫壓力是之前的萬分之一。而且id作為主鍵,是有索引的有索引,有索引能大大優化查詢性能,優化後的sql如下:
<!-- 根據商品id更新品牌id -->
<update id="updateBrandIdByPid" parameterClass="com.jd.chat.worker.domain.param.UpdateBrandIdParam">
UPDATE $tableName$
SET brand_id = #newBrandId#
WHERE pid = #pid#
AND brand_id = 0
AND id BETWEEN #startNum# AND #endNum#
</update> 僅僅用了id限區間的語句,將一個千萬級的大表代碼層次上進行縱向切割。重新上線worker後,mysql主從沒有任何延遲!而且經過監視,短短10分鐘就更新了十幾萬數據,效率是之前的6倍!更重要的是數據庫負載均衡,應用健康運行。