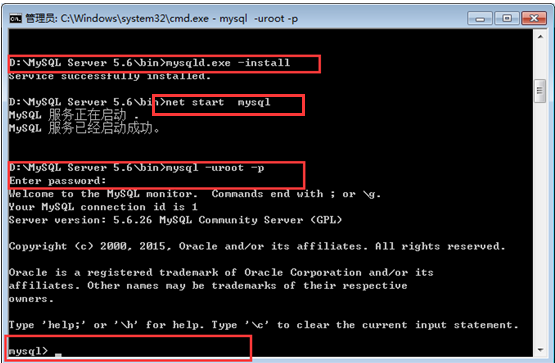
以下的文章主要討論的是MySQL Replication 優化,我們大家都知道MySQL Replication的實際討論還是占為大多數的,很多內容的實用性還是很強的,於是就總結了一下,希望會給你帶來一些幫助在此方面。
本人英文水平水平有限,難免有翻譯的不對的地方,有疑問歡迎討論:)
MySQL Replication延時的類型
1. 固定性的延時
Slave的數據持續性的落後於Master並且一直無法與Master的數據保持一致。
Slave的數據經常在白天落後於Master,而在晚上可以趕上並與Master的記錄保持一致。
這種類型的延時通常是由於Slave服務器的負載已經到達了上限或在白天訪問量大的時候到達上限造成的。
2. 非固定性的延時
Slave的數據只是短暫的落後於Master,可在短時間內恢復
這類型的延時通常與批量任務和報表有關,效率差的查詢也會導致這類延時
MySQL Replication的限制
MySQL的Replication是單線程的,意味著只能有效的使用一個CPU內核和一個磁盤,一條復雜的查詢或者事務都導致進程被阻塞,不過現在針對5.1版本的多線程Replication補丁,還是pre版,有很多限制,感興趣的可以去看看。
Replication的容量
1. 理解什麼是Replication的容量
可以將Replication暫停一個小時,重新啟動Replication後,觀察Slave的數據多久可以與Master一致。從Replication重新啟動到和Master數據一致所花費的時間與Replication暫停的時間的比值就是Replication的容量。
2. 建議保持Replication的容量在3倍以上,即延遲一個小時的數據,Slave只需要20分鐘就能與Master的數據一致。
MySQL Replication的優化
1. 5.0的MySQL中避免類似以下的更新語句
- INSERT … SELECT <complex query>
- UPDATE .... WHERE <complex clause>
復雜的查詢會導致Replication線程阻塞。如果是insert或update與select結合的語句,可以講select單獨執行並保存在臨時表中,然後再執行insert或者update。
如果使用的是5.1的MySQL,新功能中的行級ReplicationRBR)可以解決這個問題。RBR可以將在Master上通過復雜查詢後更新的結果直接傳給Slave,Slave可以直接將結果更新到數據庫中。
2. 避免大的事務
太大的事務會造成Replication長時間阻塞,數據會嚴重滯後於Master。
Slave服務器的硬件選擇
更快的CPU內核,對於單線程的Replication多核CPU是沒有任何優勢的。
更高速的硬盤,包括更高的轉速和更好的高速緩存命中率,如果有錢的話上SSD吧
主從結構的擴展性問題
1. 如何降低寫操作的頻率
Master的寫操作會擴散到所有的Slave上,所以高頻率的寫操作會降低Slave的讀操作效率。
至少保持一台Slave做全庫同步,其他的Slave可以只做部分表的同步。當然,這需要web應用程序的配合來分配哪些查詢讀哪些Slave。
將一些更新操作放到memcached中,例如session和計數器。
Slave使用myisam引擎
將一些寫入量很大的更新操作直接在slave上執行,而不通過Replication。
2. 如何更有效的利用Slave的硬件資源
使用分區
有選擇的對表進行同步
在Slave上對數據進行歸檔。
Session的持久化
為不同的應用服務器分配不同的Slave進行讀操作。
或者根據查詢類型的不同來分配不同的Slave。
3. 如何使你的程序最大化的利用Slave
將對數據更新不敏感的查詢放到Slave上,而需要實時數據的查詢則放到Master。
通過session的持久化,讓做了修改的用戶首先看到修改的內容,其他的用戶可以等待Slave更新後再查看新內容。
對於某些數據,可以用memcached來存放數據的版本號,讀Slave的程序可以先對比Slave的數據和memcached數據的版本,如果不一致則去讀master。用戶和博客類的信息可以用這種方法。
在查詢前可以通過SHOW SLAVE STATUS檢測Slave的狀態,然後根據返回的結果進行服務器的選擇。 以上的相關內容就是對MySQL Replication的介紹,望你能有所收獲。