數據庫索引就好比是一本書的目錄部分,便於大家查找數據庫中數據,方便快捷,給數據庫管理員的工作帶來了很多的便利。在MySQL數據庫中,對於索引的使用並是一直都采用正確的決定。
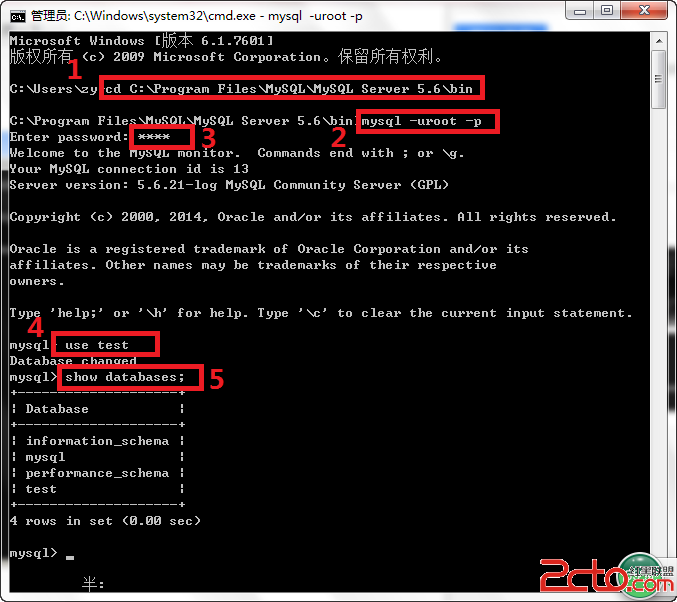
簡單表的示例:
CREATE TABLE `r2` (
ID` int(11) DEFAULT NULL,
ID1` int(11) DEFAULT NULL,
CNAME` varchar(32) DEFAULT NULL,
KEY `ID1` (`ID1`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
SELECT COUNT(*) FROM r2;
250001 (V1)
SELECT COUNT(*) FROM r2 WHERE ID1=1;
83036 (V2)
(execution time = 110 ms)
(ID1=1)條件查詢索引的選擇性是 V2/V1 = 0.3321 或 33.21%
一般來說(例如書 “SQL Tuning“),如果選擇性超過 20% 那麼全表掃描比使用索引性能更優。
我知道Oracle一直是在選擇性超過25%時會選擇全表掃描。
而MySQL呢:
mysql> EXPLAIN SELECT COUNT(SUBNAME) FROM r2 WHERE ID1=1;
+----+-------------+-------+------+---------------+-----
| id | select_type | TABLE | type | possible_keys | KEY | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-----
| 1 | SIMPLE | t2 | ref | ID1 | ID1 | 5 | const | 81371 | USING WHERE |
+----+-------------+-------+------+---------------+-----
這就是MySQL將會使用索引來完成這個查詢。
讓我們來對比索引查詢和全表掃描的執行時間:
SELECT COUNT(SUBNAME) FROM t2 WHERE ID1=1 - 410 ms
SELECT COUNT(SUBNAME) FROM t2 IGNORE INDEX (ID1) WHERE ID1=1 - 200 ms
如你所看到全表掃描要快2倍。
參考更特殊的例子:選擇性 ~95%:
SELECT cnt2 / cnt1 FROM (SELECT count(*) cnt1 FROM r2) d1, (SELECT count(*) cnt2 FROM r2 WHERE ID1=1) d2;
0.9492 = 94.92%;
說明MySQL將會用索引來完成查詢。
執行時間:
SELECT COUNT(SUBNAME) FROM t2 WHERE ID1=1 - 1200 ms
SELECT COUNT(SUBNAME) FROM t2 IGNORE INDEX (ID1) WHERE ID1=1 - 260 ms
這次全表掃描要快4.6倍。
為什麼MySQL選擇索引訪問查詢?
MySQL沒有計算索引的選擇性,只是預測邏輯IO操作的數量,並且我們的例子中間的邏輯IO數量,索引訪問要少於全表掃描。
最後我們得出結論,對於索引要小心使用,因為它們並不能幫助所有的查詢。所以大家在使用數據庫索引時還是需要根據具體的情況作出決定。