在MySQL數據庫中,用戶可能多次執行相同的查詢語句。為了提高查詢效率,數據庫會在內存在劃分一個專門的區域,用來存放用戶最近執行的查詢,這塊區域就是緩存。因為內存的運行速度要比硬盤快的多。為此通過緩存機制,就可以提高查詢的效率。當用戶下一次再執行相同查詢時,就可以直接從緩存中獲取數據,而不用到硬盤中的數據文件中去讀取數據,也可以省去相關解析的工作。
一、數據緩存的應用環境
並不是在任何情況下數據緩存都能夠起到應有的效果。如果企業有一個不經常改變的表並且服務器受到這個表的大量的相同查詢時,數據緩存才能夠起到不錯的效果。通常情況下,針對Web的應用,效果會比較明顯。如現在在數據庫中有一張產品信息表。企業的用戶需要通過網頁來查詢產品的信息。如果在系統設計時,默認查詢的結果是顯示最近一個月交易過的產品信息。那麼每次用戶按默認情況查詢產品信息時,將都會從緩存中獲取信息(如果相關的信息沒有被更新過)。此時系統查詢的速度就會比較快。
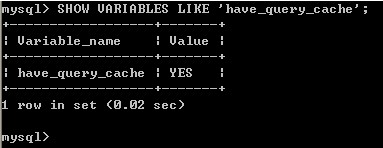
如果企業有一個不經常改變的表並且服務器受到這個表的大量的相同查詢時,筆者就建議大家啟用數據緩存機制。在啟動之前,可以先使用命名(如上圖所示)來查詢現在系統緩存是否開啟。如上圖所示,如果查詢的結果是YES的話,那麼就說明系統中已經開啟了數據緩存機制。
二、數據緩存使用的限制
並不是在任何情況下,數據緩存都會起到改善查詢的效果。根據筆者的項目經驗,認為在一下幾種情況,數據緩存機制的效果並不會很大。
一是查詢所涉及到的表會經常更改。如在一個進銷存管理系統中,可能會有產品與銷售記錄兩張表格。產品表一般不怎麼會更新,而銷售記錄表就可能每分鐘都會發生變化。此時對於銷售記錄表來說,采用緩存機制就不會起到多大的效果。因為根據緩存的工作原理,當某個表被更改後,其對應的數據緩存的相關條目就會被清空。
二是查詢緩存不使用與服務器方便些的語句。根據B/S或者C/S架構,可以將相關應用分為服務器斷和客戶端兩類。在使用數據緩存時,數據庫管理員要考慮到,在MySQL數據庫中,查詢緩存並不適用於服務器方所編寫的查詢語句。當數據庫管理員正在使用服務器方編寫的語句時,要注意到這些語句並不會應用緩存技術。
三是查詢時使用緩存的兩個基本條件:所采用的查詢語句完全一樣以及相關數據表妹歐發生更改。對於後面一條,上面已經談到過。這裡筆者要說的是,什麼叫做查詢語句瓦圈一樣?簡單的說,就是前後使用的兩條查詢語句(不一定要連在一起)完全一致。不僅包括查詢的字段,也包括查詢的條件。在這裡要認識到一個誤區。如果在5分鐘之前用戶查詢一個產品信息表,其沒有用到任何查詢條件,查詢全部的產品信息記錄。5分鐘之後又有一個用戶查詢產品信息表,此時其使用了查詢條件,如只查詢最近一個月新建的產品信息。顯然此時後面一個查詢的結果是前面一個查詢結果的子集(不考慮產品基本表在這個時間間隔中是否做了更改)。照理來說應該可以使用數據緩存。但是這裡需要注意,此時前後兩條查詢語句,其是不相同的(其查詢條件不同)。即使結果是相同的,或者具有包含關系,數據庫仍然會先重新解析SQL語句,然後從硬盤上的數據文件中去獲取數據。
另外需要注意的是如果用戶在查詢語句中,使用了自定義函數、自定義變量或者因引用了系統數據庫中的表,那麼緩存機制也會失效。
三、提高緩存的使用效果
通過數據庫的合理設計,可以提高緩存的使用效果,擴大緩存的使用領域。具體的說,數據庫管理員可以從如下幾個方面出發。
1、 根據數據變化的頻率來分解表
如現在有產品基本資料與產品最新庫存兩部分內容。在不考慮緩存的情況下,可以將產品基本資料與產品庫存放在同一個表中,然後通過其他作業來更新這個庫存數量。如此的話,在前台界面中,就可以直觀的反映出產品的庫存數量。但是從緩存的設計角度來看,這麼操作並不是很合理。因為產品信息相對來說不怎麼會變化,而庫存數量卻經常在發生變化。如果將他們放在同一張表上,由於庫存數量的不斷更新,數據緩存中的內容就會不斷被清空(與產品信息表相關的數據緩存)。此時如果很多用戶要查詢產品的描述、規格(他們可能並不關注產品的庫存),那麼他們就無法使用數據緩存。因為緩存中沒有相關的數據(由於庫存數量不斷變化而被清空)。
遇到這種情況時,數據庫管理員就可以將庫存數量與產品基本信息存放在兩張不同的表上,然後通過關鍵字來進行關聯。這麼做的好處就是庫存數量更新並不會影響到產品基本信息表所對應的數據緩存(他們是兩張表)。從而提高產品信息查詢時的緩存命中率。
2、 采用默認條件的查詢來提高緩存命中率
在上面的分析中筆者談到,要兩條完全相同的SQL語句才能夠使用緩存。條件不同或者使用的字段不同,數據庫系統都不會使用緩存來進行查詢優化。另外MySQL數據庫與其他數據庫不一樣,對於SQL語句解析來說,其大小寫實敏感的。也就是說同一條查詢語句,如果其關鍵字的大小寫不同,那麼也會被認為是用了不同的SQL語句。這一點是比較讓人頭疼的。針對這種情況,在客戶端應用程序設計時,最好注意以下幾點。
一是要習慣采用默認條件的查詢來提高緩存命中率。如在設計產品信息查詢這個功能,可以考慮默認查詢全部信息或者指定某個固定的條件。如此就可以提高緩存的命中率。而不要在不同的用戶界面設置不同的默認值。某些應用系統,為了提高界面的友好性,會給用戶提供一些個性化設置的參數,以保存用戶的個性化內容。此時雖然可以提高界面的人性化,但是顯然會降低數據緩存的命中率。遇到這種情況時,數據庫管理員就需要在人性化設計與系統的查詢性能之間進行均衡。
不同的應用針對同一個表格的相同查詢,其查詢語句最好相同。如現在對於產品信息,即可以通過產品信息窗口進行查詢,也可以根據報表來查詢。此時其對應的後台表格是相同的。只要其執行的查詢語句相同、並且在這段時間之內數據庫表格沒有發生變化,那麼系統就可以從緩存中獲取數據。在實際工作中,窗體與報表往往是有不同的人設計與開發的。如果現在這兩個人SQL語句的書寫習慣不同,一個人喜歡用大寫,而另外一個人喜歡用小寫。在系統中,對於SQL查詢語句解析時區分大小寫。如果大小寫不同,則會被認為不同的SQL語句,此時系統也就無法使用緩存了。為此在遇到這種情況時,不同的用戶之間要統一SQL語句的書寫規范,如要麼全部使用大寫,要麼全部使用小寫。項目管理員要根據實際情況來制定相關的規則。
3、 提高緩存空間大小來提高數據庫的緩存命中率
當數據緩存滿時,新的數據會覆蓋舊的數據。如現在用戶查詢了一筆產品信息。1個小時後其在利用相同的語句查詢了這個產品信息(假設在這個過程中產品信息表沒有發生變化)。查詢語句是否會采用緩存呢?答案是不一定。如果企業服務器的緩存空間足夠的大,舊的緩存信息沒有被新的查詢內容所覆蓋,那麼就會采用緩存中的信息。相反,如果緩存比較小,此時系統舊的緩存信息就會被新的查詢內容所覆蓋掉。在這種情況下,即使查詢的語句相同、表格也沒有發生變化,數據庫系統仍然要從硬盤上的數據文件中去獲取數據。
為此為了提高查詢的效率,提高緩存的命中率,最好能夠增加服務器上緩存的空間。現在內存價格比較便宜,這筆投資應該不會太大。特別是當在一台服務器上實現不同的應用時,提高內存的容量還是蠻有必要的。
關於MySQL數據庫中緩存管理的解析就為大家介紹這麼多,希望大家都能夠從中有所收獲,以後如果在工作中遇到類似問題,就可以輕松解決了。