通過一個實際生產環境中的數據存取需求,分析如何設計此存儲結構,如何操縱存儲的數據,以及如何使操作的成本或代價更低,系統開銷最小。同時,讓更多初學者明白數據存儲的表上索引是如何一個思路組織起來的,希望起到一個參考模板的價值作用。
1.測試用例描述
測試用例為B2C領域,一張用於存儲用戶選購物品而生成的產品訂單信息表,不過去掉一些其他字段,以便用於測試,其表中的數據項也不特別描述,字段意思見表:
- USE `test`;
- DROP TABLE IF EXISTS `test`.`goods_order`;
- CREATE TABLE `goods_order`(
- `order_id` INT UNSIGNED NOT NULL COMMENT '訂單單號',
- `goods_id` INT UNSIGNED NOT NULL DEFAULT '0' COMMENT '商品款號',
- `order_type` TINYINT UNSIGNED NOT NULL DEFAULT '0' COMMENT '訂單類型',
- `order_status` TINYINT UNSIGNED NOT NULL DEFAULT '0' COMMENT '訂單狀態',
- `color_id` SMALLINT UNSIGNED NOT NULL DEFAULT '0' COMMENT '顏色id',
- `size_id` SMALLINT UNSIGNED NOT NULL DEFAULT '0' COMMENT '尺寸id',
- `goods_number` MEDIUMINT UNSIGNED NOT NULL DEFAULT '0' COMMENT '數量',
- `depot_id` INT UNSIGNED NOT NULL DEFAULT '0' COMMENT '倉庫id',
- `packet_id` INT UNSIGNED NOT NULL DEFAULT '0' COMMENT '儲位code',
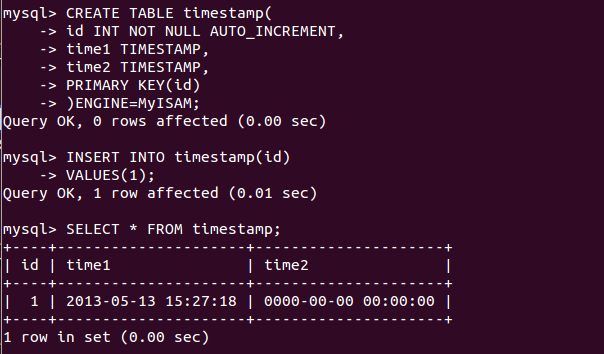
- `gmt_create` TIMESTAMP NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '添加時間',
- `gmt_modify` TIMESTAMP NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '更新時間',
- PRIMARY KEY(order_id,`goods_id`)
- )ENGINE=InnoDB AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
其中,主鍵信息:PRIMARY KEY(order_id,`goods_id`),為何主鍵索引索引字段的順序為:order_id,`goods_id`,而不是: `goods_id`, order_id呢?原因很簡單,goods_id在訂單信息表中的重復率會比order_id高,也即order_id的篩選率更高,可以減少掃描索引記錄個數,從而達到更高的效率,同時,下面即將會列出的SQL也告訴我們,有部分SQL語句的WHERE字句中只出現order_id字段,為此更加堅定我們必須把字段:order_id作為聯合主鍵索引的頭部,`goods_id`為聯合主鍵索引的尾部。
數據存儲表設計的小結:
設計用於存儲數據的表結構,首先要知道有哪些數據項,也即行內常說的數據流,以及各個數據項的屬性,比如存儲的數據類型、值域范圍及長度、數據完整性等要求,從而確定數據項的屬性定義。存儲的數據項信息確定之後,至少進行如下三步分析:
● 首先,確定哪些數據項或組合,可以作為記錄的唯一性標志;
● 其次,要確定對數據記錄有哪些操作,每個操作的頻率如何,對網站等類型應用,還需要區分前台操作和後台操作,也即分外部用戶的操作,還是內部用戶的操作;
● 最後,對作為數據記錄操作的條件部分的數據項,分析其數據項的篩選率如何,也即數據項不同值占總數據記錄數的比例關心,比例越接近1則是篩選率越好,以及各個值得分布率;
綜上所述,再讓數據修改性操作優先級別高於只讀性操作,就可以創建一個滿足要求且性能較好的索引組織結構。
數據的存取設計,就涉及一塊非常重要的知識: 關系數據庫的基礎知識和關系數據理論的范式。對於范式的知識點,特別解釋下,建議學到BCNF范式為止,1NF、2NF、3NF和BCNF之間的差別,各自規避的問題、存在的缺陷都要一清二楚,但是在真實的工作環境中,不要任何存取設計都想向范式靠,用一句佛語准確點表達:空即是色,色即是空。