我們知道,數據庫的查詢功能是我們經常用到的,那麼MySQL數據庫是怎樣進行查詢的呢?本文我們就來介紹一下MySQL數據庫的查詢步驟以及緩存原理,接下來就讓我們來一起了解一下這一部分內容。
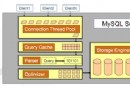
當MySQL收到客戶端發送的查詢語句時,首先會檢查緩存塊中是否緩存中此語句的結果,如果有,則檢查權限,如果能通過權限的檢查則直接返回緩存塊中的結果集,我們稱之為命中緩存,此時會增加Qcache_hits變量的值。
如果在緩存中找不到此語句的緩存(此時會增加Com_select變量的值),則進入下一步:
1、MySQL解析器將查詢語句分解成一個個標識,並建立一棵“解析樹”,解析器會使用MySQL的語法解析和驗證這個查詢語句的標識的有效性及標識是否出現在適當的位置上,它還會檢查字符串中的引號有沒有閉合。
2、預處理器會檢查此“解析樹”中的表和列是否存在,列的別名是否混淆,最後就是對權限的檢查,而這些檢查特性是解析器不具備的,只能通過預處理器來完成。
3、如果前面兩步都通過了檢驗,MySQL的優化器則對“解析樹”進行優化,並根據所預測的執行成本來生成執行成本最低的執行計劃。最後執行此計劃,存儲查詢結果,返回結果集給客戶端。
通過上述兩個變量值,我們可以通過這個公式計算出緩存的命中率: Qcache_hits / (Qcache_hits_Com_select), 通過命中率來查看我們是否可以從緩存中獲益。這裡有一個問題就是:命中率的多少才是最好的呢?這個沒有確定值的,要根據情況而定,如果命中的是那些要篩選大量數據才得到的結果的查詢語句(比如說:GROUP BY, COUNT等),即使命中率很低,但這也是一個很好的命中率值。
任何不是從緩存塊中取得數據的查詢語句都稱為:緩存錯失(cache miss), 造成緩存錯失有以下幾種原因:
1、所發送的查詢語句是不可緩存的,查詢語句不可緩存的原因有兩種:語句包含了不確定值,如CURRENT_DATE,。 所得到的結果集太大而無法將它保存到緩存中. 這兩種原因造成的結果都會增加Qcache_not_cached變量的值, 我們可以查看這個變量的值來檢查我們查詢語句的緩存情況.
2、所發送的查詢語句之前沒有發送過(第一次發送), 所以也不會有什麼緩存存在。
3、所發送的查詢語句的結果集之前是存在於緩存中的,但由於內存不足,MySQL不得不將之前的一些緩存清除,以騰出空間來放置其它新的緩存結果。同樣,數據的變更也會引發緩存的失效。比如(更新,刪除,插入)。如果是數據的變量引起緩存的失效的話,我們可以通過查看Com_*變量的值來確認有多少查詢語句更改了數據,這些變量為:Com_update, Com_delete等等
關於MySQL數據庫的查詢步驟與緩存原理的知識就介紹到這裡了,希望本次的介紹能夠對您有所收獲!
原文出處:http://52226777.blog.163.com/ 。