MySQL數據庫主從延時如何去判斷呢?本文我們介紹了兩種判斷方法:1. Seconds_Behind_Master vs 2. mk-heartbeat,接下來我們就分別介紹這些內容。
日常工作中,對於MySQL主從復制檢查,一方面我們要保證復制的整體結構是否正常,另一方面需要檢查主從數據是否保持一致。對於前者我們可以通過監控復制線程是否工作正常以及主從延時是否在容忍范圍內,對於後者則可以通過分別校驗主從表中數據的md5碼是否一致,來保證數據一致,可以使用Maatkit工具包中的mk-table- checksum工具去檢查。
方法1:
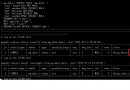
通過監控show slave status\G命令輸出的Seconds_Behind_Master參數的值來判斷,是否有發生主從延時。其值有這麼幾種:
NULL — 表示io_thread或是sql_thread有任何一個發生故障,也就是該線程的Running狀態是No,而非Yes。
0 — 該值為零,是我們極為渴望看到的情況,表示主從復制良好,可以認為lag不存在。
正值 — 表示主從已經出現延時,數字越大表示從庫落後主庫越多。
負值 — 幾乎很少見,我只是聽一些資深的DBA說見過,其實,這是一個BUG值,該參數是不支持負值的,也就是不應該出現。
show slave status\G,該命令的輸出結果非常豐厚,給我們的監控提供了很多有意義的參數,比如:Slave_IO_Running該參數可作為 io_thread的監控項,Yes表示io_thread的和主庫連接正常並能實施復制工作,No則說明與主庫通訊異常,多數情況是由主從間網絡引起的問題;Slave_SQL_Running該參數代表sql_thread是否正常,具體就是語句是否執行通過,常會遇到主鍵重復或是某個表不存在。下面就說到今天的重點Seconds_Behind_Master,該值作為判斷主從延時的指標,那麼它又是怎麼得到這個值的呢,同時,它為什麼又受到很多人的質疑?
Seconds_Behind_Master是通過比較sql_thread執行的event的timestamp和 io_thread復制好的event的timestamp(簡寫為ts)進行比較,而得到的這麼一個差值。我們都知道的relay-log和主庫的 bin-log裡面的內容完全一樣,在記錄sql語句的同時會被記錄上當時的ts,所以比較參考的值來自於binlog,其實主從沒有必要與NTP進行同步,也就是說無需保證主從時鐘的一致。
你也會發現,其實比較真正是發生在io_thread與sql_thread之間,而io_thread才真正與主庫有關聯,於是,問題就出來了,當主庫I/O負載很大或是網絡阻塞,io_thread不能及時復制binlog(沒有中斷,也在復制),而 sql_thread一直都能跟上io_thread的腳本,這時Seconds_Behind_Master的值是0,也就是我們認為的無延時,但是,實際上不是,你懂得。這也就是為什麼大家要批判用這個參數來監控數據庫是否發生延時不准的原因,但是這個值並不是總是不准,如果當io_thread與 master網絡很好的情況下,那麼該值也是很有價值的。
之前,提到Seconds_Behind_Master這個參數會有負值出現,我們已經知道該值是io_thread的最近跟新的ts與sql_thread執行到的ts差值,前者始終是大於後者的,唯一的肯能就是某個event的ts發生了錯誤,比之前的小了,那麼當這種情況發生時,負值出現就成為可能。
方法2:
mk-heartbeat,Maatkit萬能工具包中的一個工具,被認為可以准確判斷復制延時的方法。
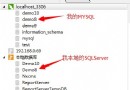
mk-heartbeat的實現也是借助timestmp的比較實現的,它首先需要保證主從服務器必須要保持一致,通過與相同的一個NTP server同步時鐘。它需要在主庫上創建一個heartbeat的表,裡面至少有id與ts兩個字段,id為server_id,ts就是當前的時間戳 now(),該結構也會被復制到從庫上。
表建好以後,會在主庫上以後台進程的模式去執行一行更新操作的命令,定期去向表中的插入數據,這個周期默認為1 秒,同時從庫也會在後台執行一個監控命令,與主庫保持一致的周期去比較,復制過來記錄的ts值與主庫上的同一條ts值,差值為0表示無延時,差值越大表示延時的秒數越多。
我們都知道復制是異步的ts不肯完全一致,所以該工具允許半秒的差距,在這之內的差異都可忽略認為無延時。這個工具就是通過實打實的復制,巧妙的借用timestamp來檢查延時,非常好用!
關於檢查MySQL數據庫的主從延時的兩種方法就介紹到這裡了,希望本次的介紹能夠對您有所收獲!