將模型簡單化,假設有三個表:tblA, tblB, tblC. 每個表包含三列:col1, col2, col3. 表的其它屬性不考慮。
在不創建index的情況下,我們使用以下語句關聯三個表:
- SELECT
- *
- FROM
- tblA, 5 tblB, 6 tblC 7 WHERE
- tblA.col1 = tblB.col1 9 AND tblA.col2 = tblC.col1;
對該語句使用EXPLAIN命令查看其處理情況:
+-------+------+---------------+------+---------+------+------+-------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+------+---------+------+------+-------------+ | tblA | ALL | NULL | NULL | NULL | NULL | 1000 | | | tblB | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | | tblC | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | +-------+------+---------------+------+---------+------+------+-------------+關於EXPLAIN命令中,各個參數的具體含義,詳解見ali的博文
[http://www.cnitblog.com/aliyiyi08/archive/2008/09/09/48878.html]
查詢機制
對於命令的查詢機制,可以參照下MySQL manual(7.2.1)中的一段說明:
The tables are listed in the output in the order that MySQL would read them while processing the query. MySQL resolves all joins using a single-sweep multi-join method. This means that MySQL reads a row from the first table, then finds a matching row in the second table, then in the third table, and so on. When all tables are processed, MySQL outputs the selected columns and backtracks through the table list until a table is found for which there are more matching rows. The next row is read from this table and the process continues with the next table.
正如上面所說,MySQL按照tblA, tblB, tblC的順序依次讀取數據,從EXPLAIN輸出的信息結構看,之前的表查詢的數據用來查找當前表對應的內容。即用tblA的值來查找tblB中滿足條件的值,tblB的值用來查找tblC中滿足條件的值。而當一次查找完成時即三個表的值都查找過一次),MySQL並不會重新返回到tblA中的下一個數據重新開始,而是繼續返回到tblB中的數據,來看tblB中是否還有其它行的值和tblA相匹配,如果有的話,繼續到tblC,重復剛才的過程。這整個過程的關鍵原則就是:使用前一個表查詢的數據來查找當前表對應的內容。
了解到MySQL在執行多表查詢時使用前一個表查詢的數據來查找當前表對應的內容這一原理後,那麼創建Index的目的就是告訴MySQL怎麼去直接找到下一個表的對應數據,如何按照MySQL需要的數據順序來關聯(JOIN)一個表。
再拿剛才的例子,tblA和tblB兩個表通過條件 ”tblA.col1 = tblB.col1” 關聯起來。我們首先獲得tblA.col1,接下來MySQL需要的是來自tblB.col1的值,所以我們為它創建INDEX tblB.col1. 創建index後再次EXPLAIN之前的查詢命令如下:

+-------+------+---------------+----------+---------+-----------+------+-------------+ | table | type | possible_keys | key | key_len | ref | rows | Extra | +-------+------+---------------+----------+---------+-----------+------+-------------+ | tblA | ALL | NULL | NULL | NULL | NULL | 1000 | | | tblB | ref | ndx_col1 | ndx_col1 | 5 | tblA.col1 | 1 | Using where | | tblC | ALL | NULL | NULL | NULL | NULL | 1000 | Using where | +-------+------+---------------+----------+---------+-----------+------+-------------+
從結果中可以看出,MySQL現在使用key ‘ndx_col1’來關聯tblB到tblA。也就是說,當MySQL查找tblB中的各行數據時,它直接使用key ‘ndx_col1’ 對應的tblA.col1來找到對應的行,而不是像之前那樣進行全表掃描查找。
例子
舉一個實例說明用法
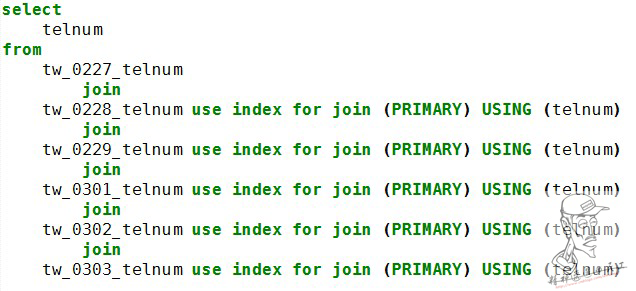
其中USING選擇的參數,要求是每個表所共有且在每個表中值不重復,以保證index唯一。
join (PRIMARY)中PRIMARY參數為Index名,
表的屬性中,作為index需要將參數勾選PK屬性,即Primary Key。
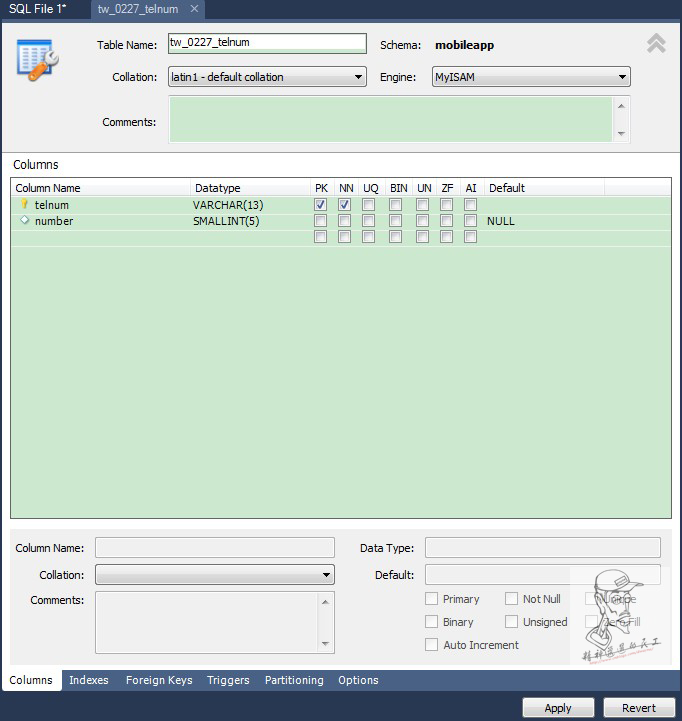
勾選telnum作為主鍵,需要將Default值中默認的NULL刪除,PRIMARY_KEY不允許包含NULL值。
為每一個表創建了Index值後,EXPLAIN輸出為:

對於MySQL,不管多復雜的查詢,每次只需要按照EXPLAIN顯示的順序關聯兩張表中的內容。創建Index是為了讓MySQL能夠利用已經查找到的內容來快速找到下一張表的對應行內容。
原文鏈接:http://www.cnblogs.com/dwayne/archive/2012/07/06/MySQL_index_join_wayne.html
編輯推薦】