本文作者: 田逸 出處:BKJIA
那天因參加MS的新品發布大會,中午就離開辦公室,當我正在出租車上前往會場的途中,同事打電話來說主數據庫出現寫保護錯誤。這可不得了,所有的應用都靠這個數據庫呀,我心裡默念:千萬不要出漏子,否則就不能參會了!於是我在電話裡交代同事重啟mysql數據庫試試,還好,重啟後問題解決。
一散會,就趕緊上去找故障原因。這裡先描述一下平台環境,把邏輯關系弄清楚。在這個應用中,由一個web前段服務器,一個tomcat應用服務器及一個mysql服務器構成,所有的系統都是linux。用戶的請求先到前端的apache服務器,如果請求頁面是.jsp,apache就把請求轉交給tomcat服務器,tomcat再從數據庫獲取數據或向數據庫插入記錄。這是典型的3層應用邏輯。
登錄到數據庫mysql服務器,用mysql客戶端連接mysql數據庫,執行命令 mysql > show processlist; 沒發現什麼異常,負載也很低。看來從這裡看不出什麼名堂。接下來當然該看mysql錯誤日志,發現如下異常:
080313 11:25:35 InnoDB: Error: cannot allocate 1064960 bytes of
InnoDB: memory with malloc! Total allocated memory
InnoDB: by InnoDB 1233305429 bytes. Operating system errno: 12
InnoDB: Check if you should increase the swap file or
InnoDB: ulimits of your operating system.
InnoDB: On FreeBSD check you have compiled the OS with
InnoDB: a big enough maximum process size.
InnoDB: Note that in most 32-bit computers the process
InnoDB: memory space is limited to 2 GB or 4 GB.
InnoDB: We keep retrying the allocation for 60 seconds...
080313 11:26:08 [ERROR] /usr/local/mysql/bin/mysqld: Sort aborted
080313 11:26:19 InnoDB: Error: cannot allocate 1064960 bytes of
InnoDB: memory with malloc! Total allocated memory
這個報錯的大意是:內存基本耗盡,沒有再可以分配的空間。由此判斷是什麼東西產生巨大的負荷導致系統內存被搾干了。不過現在數據庫服務器已經趨於平穩,暫時查不到什麼原因引起這個故障。
基本情況掌握了,停下來休息片刻,於是順手收一下郵件,乖乖,來了一封報警郵件,趕緊打開,其內容如下:
***** Nagios 2.9 *****
Notification Type: PROBLEM
Service: check_load
Host: tomcat nch100
Address: 61.154.105.100
State: WARNING
Date/Time: Thu Mar 13 10:59:53 CST 2008
Additional Info:
WARNING - load average: 3.94, 8.56, 9.17
報警消息表明主機61.154.105.100在10:59的這個時間負載過大。而這個主機正好是tomcat服務器,看來問題就在這個上面.為了近一步確認自己的想法,我來查看一下網絡流量:
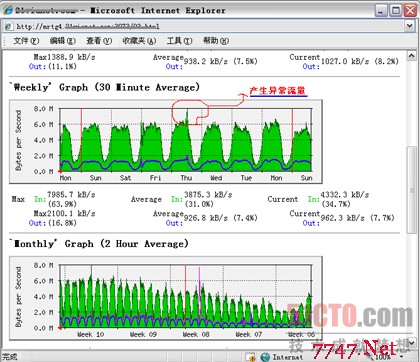
從流量圖可以看出,產生異常流量的時間正好與報警信息的時間一致,再給同事打電話,問:“你們都在61.154.105.100 這個機器上干了啥?”,答:“執行了一條不正確的sql語句,發現問題後取消這個sql語句”。至此,原因查明!