1.1 備份
mysqldump 是采用SQL級別的備份機制,它將數據表導成SQL 腳本文件,在不同的MySQL 版本之間升級時相對比較合適,這也是最常用的備份方法。
現在來講一下mysqldump 的一些主要參數:
--compatible=name
它告訴mysqldump,導出的數據將和哪種數據庫或哪個舊版本的MySQL 服務器相兼容。值可以為ansi、mysql323、mysql40、postgresql、oracle、mssql、db2、maxdb、no_key_options、no_tables_options、no_field_options 等,要使用幾個值,用逗號將它們隔開。當然了,它並不保證能完全兼容,而是盡量兼容。
--complete-insert,-c
導出的數據采用包含字段名的完整INSERT 方式,也就是把所有的值都寫在一行。這麼做能提高插入效率,但是可能會受到max_allowed_packet 參數的影響而導致插入失敗。因此,需要謹慎使用該參數,至少我不推薦。
--default-character-set=charset
指定導出數據時采用何種字符集,如果數據表不是采用默認的latin1 字符集的話,那麼導出時必須指定該選項,否則再次導入數據後將產生亂碼問題。
--disable-keys
告訴mysqldump 在INSERT 語句的開頭和結尾增加/*!40000 ALTER TABLE table DISABLE KEYS */; 和/*!40000 ALTER TABLE table ENABLE KEYS */; 語句,這能大大提高插入語句的速度,因為它是在插入完所有數據後才重建索引的。該選項只適合MyISAM 表。
--extended-insert = true|false
默認情況下,mysqldump 開啟--complete-insert 模式,因此不想用它的的話,就使用本選項,設定它的值為false 即可。
--hex-blob
使用十六進制格式導出二進制字符串字段。如果有二進制數據就必須使用本選項。影響到的字段類型有BINARY、VARBINARY、BLOB。
--lock-all-tables,-x
在開始導出之前,提交請求鎖定所有數據庫中的所有表,以保證數據的一致性。這是一個全局讀鎖,並且自動關閉--single-transaction 和--lock-tables 選項。
--lock-tables
它和--lock-all-tables 類似,不過是鎖定當前導出的數據表,而不是一下子鎖定全部庫下的表。本選項只適用於MyISAM 表,如果是Innodb 表可以用--single-transaction 選項。
--no-create-info,-t
只導出數據,而不添加CREATE TABLE 語句。
--no-data,-d
不導出任何數據,只導出數據庫表結構。
--opt
這只是一個快捷選項,等同於同時添加--add-drop-tables --add-locking --create-option --disable-keys --extended-insert --lock-tables --quick --set-charset 選項。本選項能讓mysqldump 很快的導出數據,並且導出的數據能很快導回。該選項默認開啟,但可以用--skip-opt 禁用。注意,如果運行mysqldump 沒有指定--quick 或--opt 選項,則會將整個結果集放在內存中。如果導出大數據庫的話可能會出現問題。
--quick,-q
該選項在導出大表時很有用,它強制mysqldump 從服務器查詢取得記錄直接輸出而不是取得所有記錄後將它們緩存到內存中。
--routines,-R
導出存儲過程以及自定義函數。
--single-transaction
該選項在導出數據之前提交一個BEGIN SQL語句,BEGIN 不會阻塞任何應用程序且能保證導出時數據庫的一致性狀態。它只適用於事務表,例如InnoDB 和BDB。
本選項和--lock-tables 選項是互斥的,因為LOCK TABLES 會使任何掛起的事務隱含提交。
要想導出大表的話,應結合使用--quick 選項。
--triggers
同時導出觸發器。該選項默認啟用,用--skip-triggers 禁用它。
其他參數詳情請參考手冊,我通常使用以下SQL 來備份MyISAM 表:
/usr/local/mysql/bin/mysqldump -uyejr -pyejr --default-character-set=utf8 --opt --extended-insert=false /
--triggers -R --hex-blob -x db_name > db_name.sql
使用以下SQL 來備份Innodb 表:
/usr/local/mysql/bin/mysqldump -uyejr -pyejr --default-character-set=utf8 --opt --extended-insert=false /
--triggers -R --hex-blob --single-transaction db_name > db_name.sql
1.2 還原
用mysqldump 備份出來的文件是一個可以直接倒入的SQL 腳本,有兩種方法可以將數據導入。
直接用mysql 客戶端
例如:
/usr/local/mysql/bin/mysql -uyejr -pyejr db_name < db_name.sql
用SOURCE 語法
其實這不是標准的SQL 語法,而是mysql 客戶端提供的功能,例如:
SOURCE /tmp/db_name.sql;
這裡需要指定文件的絕對路徑,並且必須是mysqld 運行用戶(例如nobody)有權限讀取的文件。
2、mysqlhotcopy
2.1 備份
mysqlhotcopy 是一個PERL 程序,最初由Tim Bunce編寫。它使用LOCK TABLES、FLUSH TABLES 和cp 或scp 來快速備份數據庫。它是備份數據庫或單個表的最快的途徑,但它只能運行在數據庫文件(包括數據表定義文件、數據文件、索引文件)所在的機器上。mysqlhotcopy 只能用於備份MyISAM,並且只能運行在 類Unix 和NetWare 系統上。
mysqlhotcopy 支持一次性拷貝多個數據庫,同時還支持正則表達。以下是幾個例子:
root#/usr/local/mysql/bin/mysqlhotcopy -h=localhost -u=yejr -p=yejr db_name /tmp (把數據庫目錄db_name 拷貝到/tmp 下)
root#/usr/local/mysql/bin/mysqlhotcopy -h=localhost -u=yejr -p=yejr db_name_1 ... db_name_n /tmp
root#/usr/local/mysql/bin/mysqlhotcopy -h=localhost -u=yejr -p=yejr db_name./regex/ /tmp
更詳細的使用方法請查看手冊,或者調用下面的命令來查看mysqlhotcopy 的幫助:
perldoc /usr/local/mysql/bin/mysqlhotcopy
注意,想要使用mysqlhotcopy,必須要有SELECT、RELOAD(要執行FLUSH TABLES) 權限,並且還必須要能夠有讀取datadir/db_name 目錄的權限。
2.2 還原
mysqlhotcopy 備份出來的是整個數據庫目錄,使用時可以直接拷貝到mysqld 指定的datadir (在這裡是/usr/local/mysql/data/)目錄下即可,同時要注意權限的問題,如下例:
root#cp -rf db_name /usr/local/mysql/data/
root#chown -R nobody:nobody /usr/local/mysql/data/ (將db_name 目錄的屬主改成mysqld 運行用戶)
3、SQL 語法備份
3.1 備份
BACKUP TABLE 語法其實和mysqlhotcopy 的工作原理差不多,都是鎖表,然後拷貝數據文件。它能實現在線備份,但是效果不理想,因此不推薦使用。它只拷貝表結構文件和數據文件,不同時拷貝索引文件,因此恢復時比較慢。
例子:
BACK TABLE tbl_name TO '/tmp/db_name/';
注意,必須要有FILE 權限才能執行本SQL,並且目錄/tmp/db_name/ 必須能被mysqld 用戶可寫,導出的文件不能覆蓋已經存在的文件,以避免安全問題。
SELECT INTO OUTFILE 則是把數據導出來成為普通的文本文件,可以自定義字段間隔的方式,方便處理這些數據。
例子:
SELECT INTO OUTFILE '/tmp/db_name/tbl_name.txt' FROM tbl_name;
注意,必須要有FILE 權限才能執行本SQL,並且文件/tmp/db_name/tbl_name.txt 必須能被mysqld 用戶可寫,導出的文件不能覆蓋已經存在的文件,以避免安全問題。
3.2 恢復
用BACKUP TABLE 方法備份出來的文件,可以運行RESTORE TABLE 語句來恢復數據表。
例子:
RESTORE TABLE FROM '/tmp/db_name/';
權限要求類似上面所述。
用SELECT INTO OUTFILE 方法備份出來的文件,可以運行LOAD DATA INFILE 語句來恢復數據表。
例子:
LOAD DATA INFILE '/tmp/db_name/tbl_name.txt' INTO TABLE tbl_name;
權限要求類似上面所述。倒入數據之前,數據表要已經存在才行。如果擔心數據會發生重復,可以增加REPLACE 關鍵字來替換已有記錄或者用IGNORE 關鍵字來忽略他們。
4、 啟用二進制日志(binlog)
采用binlog 的方法相對來說更靈活,省心省力,而且還可以支持增量備份。
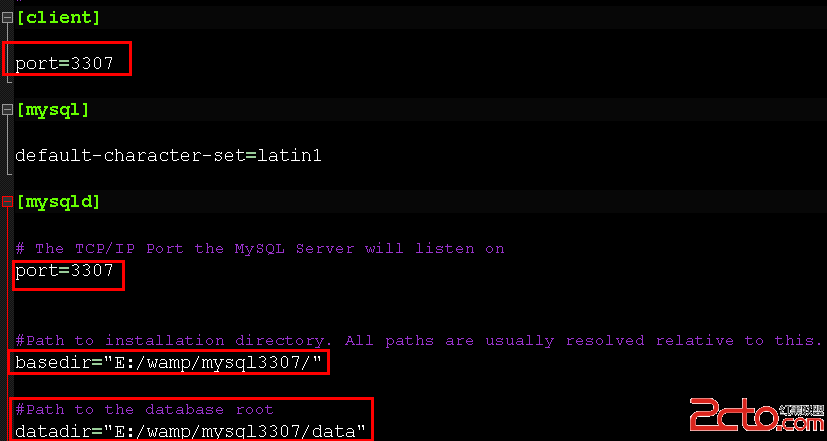
啟用binlog 時必須要重啟mysqld。首先,關閉mysqld,打開my.cnf,加入以下幾行:
server-id = 1
log-bin = binlog
log-bin-index = binlog.index
然後啟動mysqld 就可以了。運行過程中會產生binlog.000001 以及binlog.index,前面的文件是mysqld 記錄所有對數據的更新操作,後面的文件則是所有binlog 的索引,都不能輕易刪除。關於binlog 的信息請查看手冊。
需要備份時,可以先執行一下SQL 語句,讓mysqld 終止對當前binlog 的寫入,就可以把文件直接備份,這樣的話就能達到增量備份的目的了:
FLUSH LOGS;
如果是備份復制系統中的從服務器,還應該備份master.info 和relay-log.info 文件。
備份出來的binlog 文件可以用MySQL 提供的工具mysqlbinlog 來查看,如:
/usr/local/mysql/bin/mysqlbinlog /tmp/binlog.000001
該工具允許你顯示指定的數據庫下的所有SQL 語句,並且還可以限定時間范圍,相當的方便,詳細的請查看手冊。
恢復時,可以采用類似以下語句來做到:
/usr/local/mysql/bin/mysqlbinlog /tmp/binlog.000001 | mysql -uyejr -pyejr db_name
把mysqlbinlog 輸出的SQL 語句直接作為輸入來執行它。
如果你有空閒的機器,不妨采用這種方式來備份。由於作為slave 的機器性能要求相對不是那麼高,因此成本低,用低成本就能實現增量備份而且還能分擔一部分數據查詢壓力,何樂而不為呢?
5、 直接備份數據文件
相較前幾種方法,備份數據文件最為直接、快速、方便,缺點是基本上不能實現增量備份。為了保證數據的一致性,需要在靠背文件前,執行以下SQL 語句:
FLUSH TABLES WITH READ LOCK;
也就是把內存中的數據都刷新到磁盤中,同時鎖定數據表,以保證拷貝過程中不會有新的數據寫入。這種方法備份出來的數據恢復也很簡單,直接拷貝回原來的數據庫目錄下即可。
注意,對於Innodb 類型表來說,還需要備份其日志文件,即ib_logfile* 文件。因為當Innodb 表損壞時,就可以依靠這些日志文件來恢復。
6、 備份策略
對於中等級別業務量的系統來說,備份策略可以這麼定:第一次全量備份,每天一次增量備份,每周再做一次全量備份,如此一直重復。而對於重要的且繁忙的系統來說,則可能需要每天一次全量備份,每小時一次增量備份,甚至更頻繁。為了不影響線上業務,實現在線備份,並且能增量備份,最好的辦法就是采用主從復制機制(replication),在slave 機器上做備份。
7、 數據維護和災難恢復
作為一名DBA(我目前還不是,呵呵),最重要的工作內容之一是保證數據表能安全、穩定、高速使用。因此,需要定期維護你的數據表。以下SQL 語句就很有用:
CHECK TABLE 或REPAIR TABLE,檢查或維護MyISAM 表
OPTIMIZE TABLE,優化MyISAM 表
ANALYZE TABLE,分析MyISAM 表
當然了,上面這些命令起始都可以通過工具myisamchk 來完成,在這裡不作詳述。
Innodb 表則可以通過執行以下語句來整理碎片,提高索引速度:
ALTER TABLE tbl_name ENGINE = Innodb;
這其實是一個NULL 操作,表面上看什麼也不做,實際上重新整理碎片了。
通常使用的MyISAM 表可以用上面提到的恢復方法來完成。如果是索引壞了,可以用myisamchk 工具來重建索引。而對於Innodb 表來說,就沒這麼直接了,因為它把所有的表都保存在一個表空間了。不過 Innodb 有一個檢查機制叫 模糊檢查點,只要保存了日志文件,就能根據日志文件來修復錯誤。可以在my.cnf 文件中,增加以下參數,讓mysqld 在啟動時自動檢查日志文件:
innodb_force_recovery = 4
本文出自 “技術” 博客