1.什麼是UDF
UDF顧名思義,就是User defined Function,用戶定義函數。我們知道,MySQL本身支持很多內建的函數,此外還可以通過創建存儲方法來定義函數。UDF為用戶提供了一種更高效的方式來創建函數。
UDF與普通函數類似,有參數,也有輸出。分為兩種類型:單次調用型和聚集函數。前者能夠針對每一行數據進行處理,後者則用於處理Group By這樣的情況。
2.為什麼用UDF
既然MySQL本身提供了大量的函數,並且也支持定義函數,為什麼我們還需要UDF呢?這主要基於以下幾點:
1)UDF的兼容性很好,這得益於MySQL的UDF基本上沒有變動
2)比存儲方法具有更高的執行效率,並支持聚集函數
3)相比修改代碼增加函數,更加方便簡單
當然UDF也是有缺點的,這是因為UDF也處於mysqld的內存空間中,不謹慎的內存使用很容易導致mysqld crash掉。
3.如何編寫UDF
UDF的API包括
name_init():
在執行SQL之前會被調用,主要做一些初始化的工作,比如分配後續用到的內存、初始化變量、檢查參數是否合法等。
name_deinit()
在執行完SQL後調用,大多用於內存清理等工作。init和deinit這兩個函數都是可選的
name()
UDF的主要處理函數,當為單次調用型時,可以處理每一行的數據;當為聚集函數時,則返回Group by後的聚集結果。
name_add()
在每個分組中每行調用
name_clear()
在每個分組之後調用
為了便於理解,這裡給出兩種UDF類型的API調用圖:
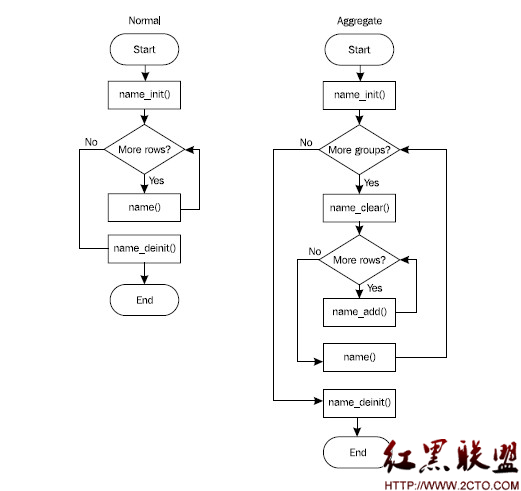
下面將就上述幾個API進行詳細的講解:
1). name_init
原型:
my_boolname_init(UDF_INIT *initid, UDF_ARGS *args, char *message)
UDF_INIT結構體如下:
字段
類型
描述
maybe_null
my_bool
如果為1表示該UDF可以返回NULL
decimals
unsigned int
返回值為實數時,表示精度,范圍0~30
max_length
unsigned long
對於返回值為INTEGER類型值為21,對於REAL類型值為17,對於字符串類型,存儲函數最長參數的長度
ptr
char*
額外的指針,我們可以在這裡分配內存。通過initd傳遞給其他API
const_item
my_bool
為1表示函數總是返回相同的值
extension
void*
用於擴展?
UDF_ARGS結構體如下:
字段
類型
描述
arg_count
unsigned int
參數個數
arg_type
enum Item_result*
參數類型數組,記錄每一個參數的類型,可以是STRING_RESULT、REAL_RESULT、INT_RESULT以及DECIMAL_RESULT
args
char **
同樣是一個數組,用於存儲實際數據。
STRING_RESULT與DECIMAL_RESULT類型為char*,INT_RESULT類型為long long*,REAL_RESULT類型為double*,或者一個NULL指針
lengths
unsigned long*
數組,用於存儲每一個參數的長度
maybe_null
char *
該數組用於表明每個參數是否可以為NULL,例如
attributes
char **
每個參數的名字
attribute_lengths
unsigned long*
每個參數名字的長度
extension
void*
用於擴展?
Message:用於打印錯誤信息,該指針本身提供長度為MYSQL_ERRMSG_SIZE,來存儲信息;
2).name_deinit
原型:
void name_deinit(UDF_INIT*initid)
該函數會進行一些內存釋放和清理的工作,在之前我們提到initid->ptr,我們可以在該區域·進行內存的動態分配,這裡就可以直接進行內存釋放。
3).name()
原型:針對不同的返回值類型,有不同的函數原型:
返回值類型
函數原型
STRING or DECIMAL
char *name(UDF_INIT *initid, UDF_ARGS *args, char *result, unsigned long *length, char *is_null, char *error)
INTEGER
long long name(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error)
REAL
double name(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error);
當返回值為STRING類型時,參數result開辟一個buffer來存儲返回值,但不超過766字節,在length參數中存儲了字符串的長度。
每個函數原型還包括了is_null和error參數,當*is_null被設置為1時,返回值為NULL,設置*error為1,表明發生了錯誤。
4).name_add()和name_clear()
原型:
void name_add(UDF_INIT *initid, UDF_ARGS *args, char *is_null,char *error)
void name_clear(UDF_INIT *initid, char *is_null, char *error)
對於聚合類型的UDF,name_addd和name_clear會被反復調用。
4. 兩個例子
下面將舉兩個簡單的例子,一個單次調用型函數,一個聚集類型函數,來描述寫一個UDF的過程。
1)接受一個參數,並返回該參數的值
//初始化
my_booludf_int_init(UDF_INIT *initid, UDF_ARGS *args, char *message)
{
if (args->arg_count != 1){ //檢查參數個數
strcpy(message,
"udf_intexample() can onlyaccept one argument");
return 1;
}
if (args->arg_type[0] != INT_RESULT){ //檢查參數類型
strcpy(message,
"udf_intexample() argumenthas to be an integer");
return 1;
}
return 0;
}
//清理操作
voidudf_int_deinit(UDF_INIT *initid)
{
}
//主函數
long long udf_int(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error)
{
long long num = (*(long long *)args->args[0]); //獲取第一個參數值
return num;
}
2)接受一個浮點數類型的參數,並對每個分組進行求和
//初始化
my_booludf_floatsum_init(UDF_INIT *initid, UDF_ARGS *args, char *message)
{
double *total = (double *) malloc (sizeof(double));
if (total == NULL){ //內存分配失敗
strcpy(message,"udf_floatsum:alloc mem failed!");
return 1;
}
*total = 0;
initid->ptr = (char *)total;
if (args->arg_count != 1){ //檢查參數個數
strcpy(message, "too moreargs,only one!");
return 1;
}
if (args->arg_type[0] != REAL_RESULT){ //檢查參數類型
strcpy(message, "wrongtype");
return 1;
}
initid->decimals = 3; //設置返回值精度
return 0;
}
//清理、釋放在init函數中分配的內存
voidudf_floatsum_deinit(UDF_INIT *initid)
{
free(initid->ptr);
}
//每一行都會調用到該函數
voidudf_floatsum_add(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error)
{
double* float_total;
float_total = (double*)initid->ptr;
if (args->args[0])
*float_total += *(double*)args->args[0];
}
//每個分組完成後,返回結果
doubleudf_floatsum(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error)
{
double* float_total;
float_total = (double *)initid->ptr;
return *float_total;
}
//在進行下一個分組前調用,設置initid->ptr指向的值為0,以便下一次分組統計
voidudf_floatsum_clear(UDF_INIT *initid, char *is_null, char *error)
{
double *float_total;
float_total = (double *)initid->ptr;
*float_total = 0;
}
3) Mysql-udf-http是一個開源的UDF,可以利用HTTP協議進行REST操作。什麼是REST操作呢?REST是一種web service架構風格,其實現基於HTTP協議的四種方法:POST、GET、PUT以及DELETE操作,在mysql-udf-http裡分別對應的函數是http_post、http_get()、http_put()、http_delete()。
源碼下載:http://curl.haxx.se/download/curl-7.21.1.tar.gz
./configure–prefix={mysql安裝目錄} –with-mysql=/usr/local/webserver/mysql/bin/mysql_config
Make&& make install
該UDF的實現原理比較簡單,主要使用libcurl庫函數來實現http協議通信,總共三百多行代碼。這裡有使用和介紹http://blog.s135.com/mysql-udf-http/
有些比較有趣的功能:
例如,我們可以通過GET方法獲取微博中的個人信息,其中1821798401為用戶ID
selecthttp_get('http://api.t.sina.com.cn/statuses/user_timeline/1821798401.json?count=1&source=1561596835')
UDF具有非常高的自由度,你可以編寫你任何想要實現的功能函數,甚至可以引用MySQL內核的代碼和變量。
當然,UDF也有著局限性,如下:
a) 在mysql庫下必須有func表,並且在‑‑skip‑grant‑tables開啟的情況下,UDF會被禁止;
b) 當UDF掛掉時,有可能會導致mysqld crash掉;
c) 所有的UDF的函數必須是線程安全的,如果非要用全局變量,需要加互斥,盡量在name_init中分配資源,並在name_deinit中釋放
d) 需要有insert權限
作者 zhaiwx1987