先建立兩張表。
1.student表

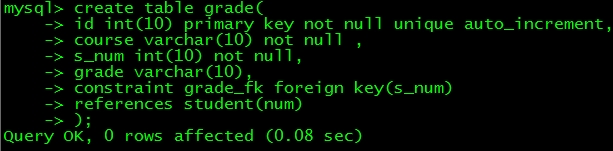
2.grade表
一:mysql的復制技術
1.表與數據的復制->>實現表結構和數據的同步
create table desttable select * from srctable;
(desttable:目標表,srctable:原表)
2.表結構的復制->>只實現表結構的同步
create table desttable select * from srctable where 0>1;
想想為什麼???
select語句既產生了表結構又產生了結果集,如果後面限制條件不成立,那麼結果集為空,就實現了只復制表結構。
3.全表記錄的復制->>將一個表的全部記錄插入另外一個表
insert into desttable select * from srctable;
4.部分字段的復制
insert into desttable(字段一,字段二.......) select (字段一,字段二.......) from srctable;
二:索引注意事項
(1):使用FULLTEXT參數可以設置索引為全文索引,全文索引只能創建在CHAR ,VARCHAR ,TEXT類型字段上。->>但只有MyISAM存儲引擎支持全文索引。
(2):多列索引:在表的多列字段上建立一個索引,但只有在查詢這些字段的第一個字段時,索引才會被使用。
(3):查詢語句使用like關鍵字進行查詢,如果匹配的第一個字符為”%“時,索引不會被使用
select * from student where num like '%4'; //索引不會被使用
select * from student where num like '4%'; //索引會被使用
(4):查詢語句中使用or關鍵字時,只有or前後兩個條件的列都是索引時,查詢時才使用索引
(5): 學會使用explain檢查索引是否被使用,我們用explain命令檢驗(2)的說法
先創建索引:create index index_nu_name on student(num,name);
#1. explain select * from student where num=2;
執行結果如下:

#2.explain select * from student where name=‘lwy’;
執行結果如下:

通過比較,我們發現,第二個的possible-key和key等都為空,而且Extra顯示查詢用where子句沒有用索引。
我們關注一下rows信息,如果用where子句,則查詢行數為2,如果使用索引,則查詢行數為1(這張表只有2條記錄,可以想象如果記錄為上萬條,用索引真的很快)
所以,通過實實驗證明了我們(2)的說法。
三:權限管理
mysql中的權限分配是按照user表,db表,tables_priv表,columns_priv表的順序進行分配的。數據庫系統中,
先判斷user表中的值是否是Y,如果是Y則就不需要檢查下面的表了。如果user表的為N,則依次檢查db表,tables_priv表,和columns_priv表。
簡單的說,就是user表存儲的是對所有數據庫的權限,db表存儲的是對某一數據庫的權限,tables_privs存儲的是對數據庫表的權限,columns_privs存儲的是表中列的權限。
比如我們新建一用戶:
#1.create user 'test1' identified by 'admin'; //注意:用戶名和密碼要交引號,為什麼->>字符串
注意下面的:create user 'test2'@localhost identified by 'admin';
這兩句有什麼區別呢?
有localhost標識的代表該用戶只能在本地連接mysql數據庫,而不能通過遠程連接。不帶localhsot的可以通過遠程連接mysql數據庫。
顯著的區別就是在user表的Host字段一個是localhost一個是%
這時我們用test1用戶連接mysql,發現成功連接,用命令show databases 發現只有information_schema這個數據庫,為什麼會有這個數據庫呢??
information_schema數據庫是MySQL自帶的,它提供了訪問數據庫元數據的方式。什麼是元數據呢?元數據是關於數據的數據,
如數據庫名或表名,列的數據類型,或訪問權限等。有些時候用於表述該信息的其他術語包括“數據詞典”和“系統目錄”。在MySQL中,
把information_schema 看作是一個數據庫,確切說是信息數據庫。其中保存著關於MySQL服務器所維護的所有其他數據庫的信息。
如數據庫名,數據庫的表,表欄的數據類型與訪問權限等。在information_schema中,有數個只讀表。它們實際上是視圖,而不是基本表,
因此,你將無法看到與之相關的任何文件。
我們用root用戶查看一下發現在user表中的權限全是N,也就是說什麼都做不了。
這時給用戶授予權限:grant seelct ,update on *.* to test1;
## *.*:第一個*代表數據庫,第二個*代表表,所以*.*就是所有數據庫的所有表。
這時會發現user表的select_priv和update_priv字段的值變為了Y。
這時再用test1用戶連接mysql數據庫,show database ,發現所有的數據庫都可以查看和更新了。
#2.這時我們再給test2授權:grant select ,update on mysql.* to test2; //只能查詢和更新mysql的所有表。
這時就會發現user表中用戶test2的所有權限都是N,而db表中test2用戶對mysql數據庫的select_priv和update_priv的值為Y。
下面tables_priv表,和columns_priv表的權限由自己分析。
經過以上分析,我們對mysql的權限有了更深一點的認識。
四:mysql日志
mysql日志有四種:
#1.二進制文件:以二進制的形式記錄了數據庫中的操作,但不記錄查詢語句
#2.錯誤日志:記錄mysql的啟動,關閉和運行錯誤等信息,默認開啟且無法停止
#3.通用查詢日志:記錄用戶登錄和記錄查詢的信息
#4.慢查詢日志:記錄查詢時間超過指定時間的操作
默認情況下,只開啟了錯誤日志的功能,其余的根據需要管理員設置
##使用二進制日志還原數據庫
因為二進制文件存儲更新數據庫的語句,所以可以用來還原數據庫
mysqlbinlog filename.number | mysql -uroot -p //mysqlbinlog 用於打開二進制文件
使用mysqlbinlog進行還原數據庫時,必須是編號(number)小的先還原。
五:性能優化
#1.性能參數:
show status ; //查詢mysql的性能參數
show status like 'value' ; //查看某一參數
常用參數介紹如下:
Connections:連接mysql服務器的次數
Uptime:mysql服務器的上線時間
Slow_queries:慢查詢的次數
Com_select:查詢操作的次數
Com_insert:插入操作的次數
Com_update:更新操作的次數
Com_delete:刪除操作的次數
#2.優化查詢
##2.1用explain和describe分析查詢語句
注使用索引查詢記錄時,一定要注意索引的使用情況 ->>見上面使用索引的注意事項
我們將上面用過的explain來分析
explain select * from student where num=2;
執行結果如下:
1.id :select語句的編號
2.select_type:select語句的類型
#simple:簡單查詢,不包含連接查詢和子查詢
#primary:主查詢或最外層的查詢語句
#union:連接查詢的第二個或後面的查詢語句
2.table:查詢的表
4.type:表的連接類型
#system:表中只有一條記錄
#const:表中有多條記錄,但只從表中查詢一條
#all:對表進行了完整的掃描
#eq_ref:多表連接時,後面的表使用了union或者primary key
#ref:多表連接時,後面使用了普通索引
#unique_subquery:子查詢使用了unique或者primary key
#index_subquery:子查詢使用了普通索引
#range:查詢語句給出了查詢范圍
#index:對表中的索引進行了完整的掃描
5.possible_keys:查詢中可能使用的索引
6.key:查詢使用的索引
7.key_len:索引字段的長度
8.ref:表示使用哪個列或常數與索引一起查詢記錄
9.rows:查詢的行數
10:extra:查詢附加信息
describe 語句使用方法和explain一樣。
##2.2 優化子查詢
多用連接查詢來代替子查詢
為什麼呢?
因為子查詢時,mysql需要為內層查詢結果建立一個臨時表,然後外層查詢在臨時表中查找,查詢完後需要撤銷臨時表。
而連接查詢不需要建立臨時表,所以比子查詢快。
##2.3優化插入記錄的速度
插入記錄時,索引,唯一性校驗等都會影響到插入記錄的速度。而且,一次插入多條記錄和多次插入記錄所耗費的時間也不同。
1.禁用索引
插入數據時,mysql會根據表的索引對插入的記錄進行排序,降低插入速度。解決這個問題可以在插入記錄之前禁用索引,等到插入完畢後在開啟。
alter table 表名disable keys; //禁用索引
alter table 表名enable keys; //開啟索引
2.禁用唯一性檢查
插入數據時,mysql會對插入的記錄進行唯一性檢查,會降低插入速度。
set unique_checks=0; //禁用唯一性
set unique_checks=1; //開啟唯一性
3.優化insert語句
insert into 表名values
(......),
(......);
insert into 表名values (......);
insert into 表名values (......);
上面兩種插入方法,第一種與數據庫的連接等操作,明顯比第二種快。
##2.3分析表,檢查表和優化表
分析表:分析關鍵字的分布
檢查表:檢查表是否存在錯誤
優化表:消除刪除或者更新造成的空間浪費
當執行下面三個操作時,mysql數據庫會給表加一個只讀鎖,只能讀取記錄,不能更新和插入記錄。
1.分析表
analyze table 表名1 [,表名2....];
2.檢查表
check table 表名1 [,表名2....] [option];
option有五個參數:quick,fast,changed,medium,extended ->>執行效率依次降低
-->option選項只對MyISAM類型的表有效。
3.優化表
optimize table 表名1 [,表名2....];
-->只能優化表中的varchar,blob和text字段
如果一個表使用了text或blob這樣的數據類型,那麼更新,刪除等就會造成的磁盤空間的浪費。操作完成後,以前分配的磁盤空間不會自動回收。
使用optimize可以將磁盤碎片整理出來,以便利用。
下面是一些mysql基本使用命令。
一:mysql查看基本命令
(1):查看當前有哪些數據庫
show databases;
(2):使用mysql數據庫
use test;
(3):查看當前數據庫下的表
show tables;
(4):查看上述grade表建立的命令
show create table grade;
(5):查看student表的結構
desc student;
(6):查看數據庫支持的存儲引擎
show engines;
show engines \G ; // \G讓結果更美觀
(7):查看默認存儲引擎
show variables like 'storage_engine';
二:mysql的修改表
(1)將grade表的course字段的數據類型修改為varchar(20)
alter table grade modify course varchar(20);
(2)將s_num字段的位置改到course前面
alter table grade modify s_num int(10) after id;
(3)將grade字段改名為score
alter table grade change grade score varchar(10);
(4)刪除grade的外鍵約束
alter table grade drop foreign key grade_fk;
(5)將grade的存儲引擎修改為INnoDB
alter grade engine=INnoDB;
(6)將student的address字段刪除
alter table student drop address;
(7)在student表中增加名位phone的字段
alter table student add phone int (10);
(8)將grade的表名修改為gradeinfo
lter table grade rename gradeinfo;
(9):刪除student表
drop table student; //由於先前已經刪除外鍵,所以才能刪除父表studnet