學過數據庫理論的讀者,都應該還記得關於CHAR和VARCHAR的性能對比:CHAR比VARCHAR更快,因為CHAR是固定長度的,而VARCHAR需要增加一個長度標識,處理時需要多一次運算。
針對這種情況,我做了一下基准測試,基准測試環境如下:
【硬件配置】
硬件
配置
CPU
Intel(R) Xeon(R) CPU E5620 主頻2.40GHz, 物理CPU 2個,邏輯CPU 16個
內存
24G(6塊 * 4G DDR3 1333 REG)
硬盤
300G * 3個,SAS硬盤 15000轉,無RAID,有RAID卡,且開了回寫功能
OS
RHEL5
MySQL
5.1.49/5.1.54
【MySQL配置】
配置項
配置
innodb_buffer_pool_size
18G
innodb_log_file_size
200M
innodb_log_files_in_group
3
sync_binlog
100
innodb_flush_log_at_trx_commit
2
【表配置】
VARCHAR平均長度200,CHAR長度250,其它配置如下:
配置項
配置
記錄數
1000萬,2000萬,5000萬,1億
存儲引擎
Innodb
行格式
compact
性能測試結果如下:
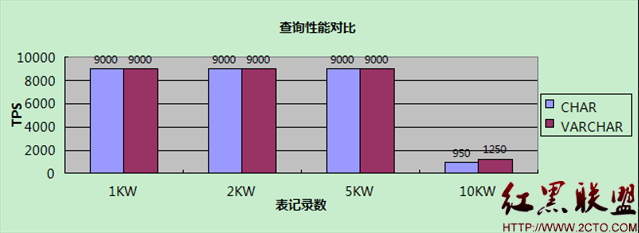
【查詢】
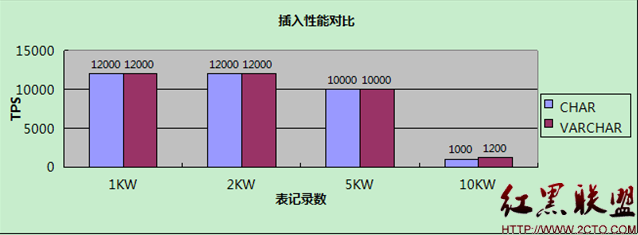
【插入】
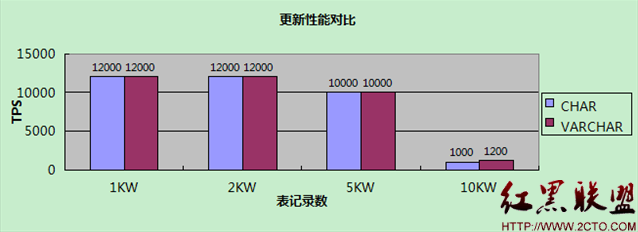
【更新】
更新時VARCHAR也是隨機長度
【刪除】
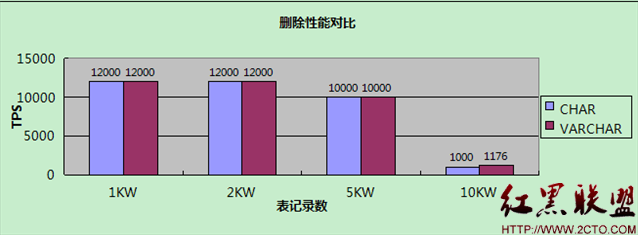
測試結果展現了一個與理論不太相符的現象:當表大小小於Innodb buffer pool時,CHAR和VARCHAR沒有差別,而在表大小大於Innodb buffer pool時,VARCHAR性能反而更高!這是為什麼呢?
首先,性能是綜合硬件、配置、表記錄數、業務模型等多種因素綜合後的結果,單一因素的差異,對整體來說可能幾乎沒有影響;
例如,執行一個操作需要100ms,而CHAR 比 VARCHAR性能上只快了1微秒,那麼最終的性能就不會有影響。
這就是當Innodb buffer pool足夠大時,CHAR 和VARCHAR沒有差別的原因。
再次,理論上CHAR比VARCHAR快的根本原因是站在CPU的角度來說的,但性能是綜合各種因素後的最終結果,當Innodb buffer pool小於表大小時,"磁盤讀寫"成為了性能的關鍵因素,而VARCHAR更短,因此性能反而比CHAR高。
最後,有朋友可能會認為,VARCHAR更新時如果新的數據比舊的數據要長,可能需要移動數據,導致性能更低;從實測結果來看,這種操作對最終的性能也是沒有明顯影響的。可能是因為Innodb采用頁管理數據,數據移動是先在內存裡完成,再寫到磁盤,因此數據即使移動也很快。
【應用技巧】
基於以上測試結果和分析,我個人認為一般情況下優先使用VARCHAR,特別是字符串的平均長度比最大長度要小很多的情況;
當然,如果你的字符串本來就很短,例如只有10個字符,那麼就優先選CHAR了。
附:
1)有興趣的朋友可以推斷一下:為什麼測試結果中10KW的表性能,VARCHAR比CHAR快大約20%?
2)測試數據只為對比用,不代表一般情況下MySQL的性能就這麼高,因為為了能夠對比,測試時做了很多准備工作,測試操作也是比較特殊的
摘自 yah99_wolf的專欄