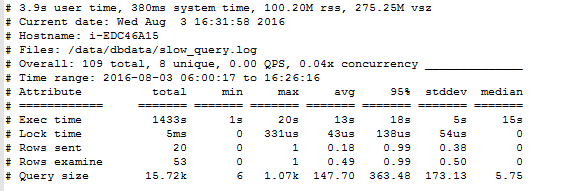
總的來說,在 MySQL 中的ORDER BY有兩種排序實現方式,一種是利用有序索引獲取有序數據,另一種則是通過相應的排序算法,將取得的數據在內存中進行排序。
下面將通過實例分析兩種排序實現方式及實現圖解:
假設有 Table A 和 B 兩個表結構分別如下:
sky@localhost : example 01:48:21> show create table A\G
*************************** 1. row ***************************
Table: A
Create Table: CREATE TABLE `A` (
`c1` int(11) NOT NULL default ‘0′,
`c2` char(2) default NULL,
`c3` varchar(16) default NULL,
`c4` datetime default NULL,
PRIMARY KEY (`c1`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
sky@localhost : example 01:48:32> show create table B\G
*************************** 1. row ***************************
Table: B
Create Table: CREATE TABLE `B` (
`c1` int(11) NOT NULL default ‘0′,
`c2` char(2) default NULL,
`c3` varchar(16) default NULL,
PRIMARY KEY (`c1`),
KEY `B_c2_ind` (`c2`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1、利用有序索引進行排序,實際上就是當我們 Query 的 ORDER BY 條件和 Query 的執行計劃中所利用的 Index 的索引鍵(或前面幾個索引鍵)完全一致,且索引訪問方式為 rang、 ref 或者 index 的時候,MySQL 可以利用索引順序而直接取得已經排好序的數據。這種方式的 ORDER BY 基本上可以說是最優的排序方式了,因為 MySQL 不需要進行實際的排序操作。
假設我們在Table A 和 B 上執行如下SQL:
sky@localhost : example 01:44:28> EXPLAIN SELECT A.* FROM A,B
-> WHERE A.c1 > 2 AND A.c2 < 5 AND A.c2 = B.c2 ORDER BY A.c1\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: A
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 3
Extra: Using where
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: B
type: ref
possible_keys: B_c2_ind
key: B_c2_ind
key_len: 7
ref: example.A.c2
rows: 2
Extra: Using where; Using index
我們通過執行計劃可以看出,MySQL實際上並沒有進行實際的排序操作,實際上其整個執行過程如下圖所示:

通過相應的排序算法,將取得的數據在內存中進行排序方式,MySQL 比需要將數據在內存中進行排序,所使用的內存區域也就是我們通過 sort_buffer_size 系統變量所設置的排序區。這個排序區是每個 Thread 獨享的,所以說可能在同一時刻在 MySQL 中可能存在多個 sort buffer 內存區域。
第二種方式在 MySQL Query Optimizer 所給出的執行計劃(通過 EXPLAIN 命令查看)中被稱為 filesort。在這種方式中,主要是由於沒有可以利用的有序索引取得有序的數據,MySQL只能通過將取得的數據在內存中進行排序然後再將數據返回給 客戶端。在 MySQL 中 filesort 的實現算法實際上是有兩種的,一種是首先根據相應的條件取出相應的排序字段和可以直接定位行數據的行指針信息,然後在 sort buffer 中進行排序。另外一種是一次性取出滿足條件行的所有字段,然後在 sort buffer 中進行排序。
在 MySQL4.1 版本之前只有第一種排序算法,第二種算法是從 MySQL4.1開始的改進算法,主要目的是為了減少第一次算法中需要兩次訪問表數據的 IO 操作,將兩次變成了一次,但相應也會耗用更多的 sort buffer 空間。當然,MySQL4.1開始的以後所有版本同時也支持第一種算法,MySQL 主要通過比較我們所設定的系統參數 max_length_for_sort_data 的大小和 Query 語句所取出的字段類型大小總和來判定需要使用哪一種排序算法。如果 max_length_for_sort_data 更大,則使用第二種優化後的算法,反之使用第一種算法。所以如果希望 ORDER BY 操作的效率盡可能的高,一定要主義 max_length_for_sort_data 參數的設置。曾經就有同事的數據庫出現大量的排序等待,造成系統負載很高,而且響應時間變得很長,最後查出正是因為 MySQL 使用了傳統的第一種排序算法而導致,在加大了 max_length_for_sort_data 參數值之後,系統負載馬上得到了大的緩解,響應也快了很多。
我們再看看 MySQL 需要使用 filesort 實現排序的實例。
假設我們改變一下我們的 Query,換成通過A.c2來排序,再看看情況:
sky@localhost : example 01:54:23> EXPLAIN SELECT A.* FROM A,B
-> WHERE A.c1 > 2 AND A.c2 < 5 AND A.c2 = B.c2 ORDER BY A.c2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: A
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 3
Extra: Using where; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: B
type: ref
possible_keys: B_c2_ind
key: B_c2_ind
key_len: 7
ref: example.A.c2
rows: 2
Extra: Using where; Using index
MySQL 從 Table A 中取出了符合條件的數據,由於取得的數據並不滿足 ORDER BY 條件,所以 MySQL 進行了 filesort 操作,其整個執行過程如下圖所示:

在 MySQL 中,filesort 操作還有一個比較奇怪的限制,那就是其數據源必須是來源於一個 Table,所以,如果我們的排序數據如果是兩個(或者更多個) Table 通過 Join所得出的,那麼 MySQL 必須通過先創建一個臨時表(Temporary Table),然後再將此臨時表的數據進行排序,如下例所示:
sky@localhost : example 02:46:15> explain select A.* from A,B
-> where A.c1 > 2 and A.c2 < 5 and A.c2 = B.c2 order by B.c3\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: A
type: range
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 3
Extra: Using where; Using temporary; Using filesort
*************************** 2. row ***************************
id: 1
select_type: SIMPLE
table: B
type: ref
possible_keys: B_c2_ind
key: B_c2_ind
key_len: 7
ref: example.A.c2
rows: 2
Extra: Using where
這個執行計劃的輸出還是有點奇怪的,不知道為什麼,MySQL Query Optimizer 將 “Using temporary” 過程顯示在第一行對 Table A 的操作中,難道只是為讓執行計劃的輸出少一行?
實際執行過程應該是如下圖所示: