一、 背景介紹
1.大數據量的存儲需要大量的數據庫資源;
2.數據量的不斷增長要求數據庫存儲具有可擴展性;
3.在保證大數據量的情況下,要保證性能、高可用性等質量要求;
4.現有框架中沒有徹底解決大數據量的存儲問題;
5.Oracle等海量存儲方案價格不菲,采用MySQL進行分庫分表節約IT成本。
1. 風險評估
1) DBA數據庫管理的資源和規范要求;
2. 業務數據量規模和變化的影響
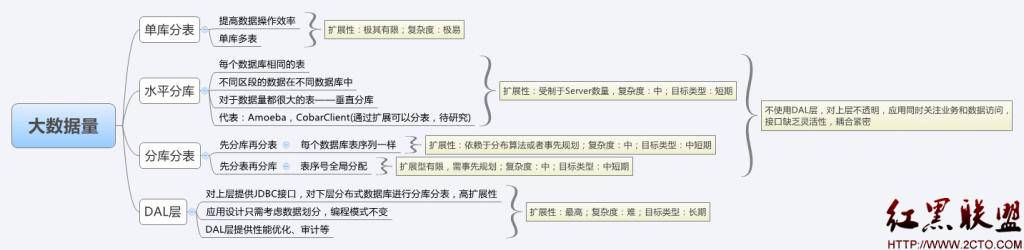
1) 對於事先可規劃的中等以上數據規模,采用單庫分表(一個數據庫實例,分多張表)、讀寫分離、或者多庫多表(多個數據庫實例,多張表)可以滿足業務需求,且相應設計和實現相對簡單,不易出錯。
2) 對於初期數據規模不可准確預知,但隨著業務發展數據規模不斷增長的系統,要求數據存儲具有可擴展性。這種可擴展性通過分庫分表解決,要求分庫分表在路由上具有極強的伸縮性,這也是分庫分表的難點,本方案提出一個循序漸進的實現路線逐步解決這個問題。
3. 技術積累
1) 公司已有簡單的分庫分表方案
2) 這個方案缺乏擴展性
3) 本方案將提出短期實現一定擴展性、中長期高可擴展性的方案
4. 開源或產品
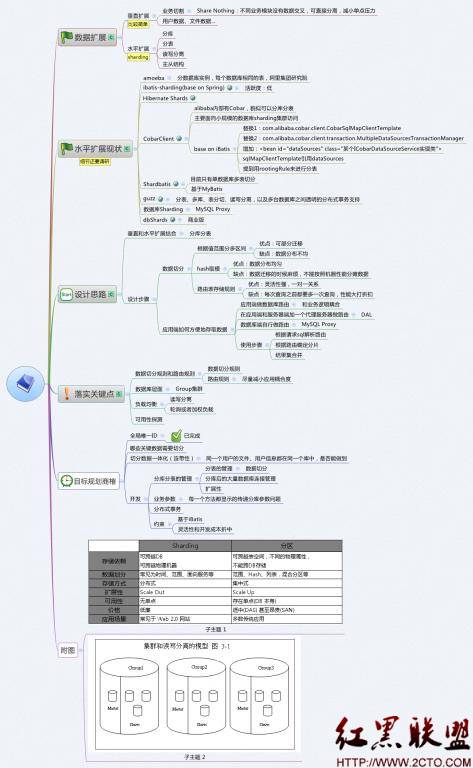
1) 商業版數據庫Sharding:MySQL Proxy,提供MySQL協議接口(非JDBC),主從結構,可以負載平衡,讀寫分離,failover等,lua語法復雜,不支持大數據量的分庫分表;
2) Amoeba,支持分數據庫實例,每個數據相同的表,不支持事務;類似MySQL Proxy,設計上拋棄lua,更簡單;
3) 阿裡集團研究院開源的CobarClient,主要面向小規模的數據庫sharding集群訪問,基於ibatis,需要規劃數據規模,缺乏擴展性;另外有Cobar,阿裡集團內部的一個完整DAL層,實現完整JDBC代理;
4) HibernateShards,Hibernate提供的sharding,支持分數據庫實例,比較復雜,事先規劃數據規模,和框架不符;
5) guzz,多庫(虛擬的數據庫,實際數據庫的路由規則仍然自定義)、表分切、讀寫分離,以及多台數據庫之間透明的分布式事務支持,設計目標是支持大型在線生產應用;需完全替換ibatis;完全和框架不符。
6) TDDL,淘寶的DAL,很強的分庫分表能力,仍然需要數據量實現規劃,動態擴展有限。
7) 以上某些產品在一定程度上可以滿足我們的需求,但不能徹底解決我們大數據量可擴展的問題。
1. 和沒有引入分庫分表時相比,每次操作最大延遲<1ms;
1. 垂直分庫,不同業務數據使用不同數據庫實例存儲
2. 數據切分:
a) 根據切分字段Hash取模;
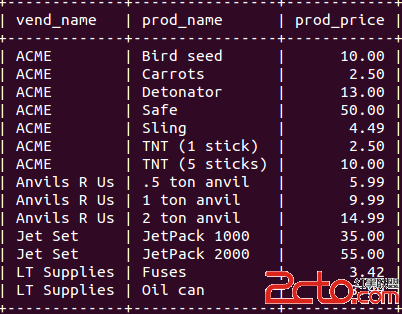
b) 確定需要切分的數據,盡量將可能進行關聯的分片數據放在一個數據庫實例中,例如同一用戶的基本信息、好友信息或者文件信息等;
3. 短期:分庫分表
a) 數據庫實例編號遞增
b) 每個數據庫內分表序號從1遞增,不全局編號
c) 基於數據源(ibatis基礎上)攔截建立訪問層,應用感知
d) 應用需在底層進行數據源、分布式事務考慮和管理等
e) 可擴展性:只支持向上擴展,不支持收縮
4. 長期:數據庫訪問層
a) 建立靈活的數據切分和路由規則
b) 支持MySQL集群
c) 讀寫分離和負載均衡
d) 可用性探測
e) 分布式事務
f) 對應用透明
附錄:
摘自 doliu6的專欄