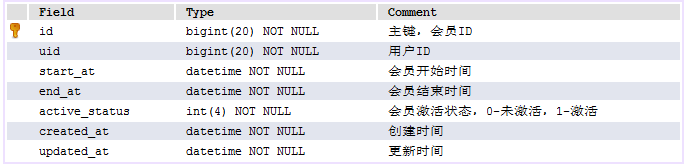
如果在INSERT語句末尾指定了ON DUPLICATE KEY UPDATE,並且插入行後會導致在一個UNIQUE索引或PRIMARY KEY中出現重復值,則在出現重復值的行執行UPDATE;
如果不會導致唯一值列重復的問題,則插入新行。 www.2cto.com
例如,如果列 a 為 主鍵 或 擁有UNIQUE索引,並且包含值1,則以下兩個語句具有相同的效果:
1
INSERT INTO TABLE (a,c) VALUES (1,3) ON DUPLICATE KEY UPDATE c=c+1;
2
UPDATE TABLE SET c=c+1 WHERE a=1;
如果行作為新記錄被插入,則受影響行的值顯示1;如果原有的記錄被更新,則受影響行的值顯示2。
這個語法還可以這樣用:
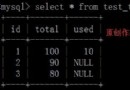
如果INSERT多行記錄(假設 a 為主鍵或 a 是一個 UNIQUE索引列):
1
1.INSERT INTO TABLE (a,c) VALUES (1,3),(1,7) ON DUPLICATE KEY UPDATE c=c+1;
執行後, c 的值會變為 4 (第二條與第一條重復, c 在原值上+1).
1 www.2cto.com
2.INSERT INTO TABLE (a,c) VALUES (1,3),(1,7) ON DUPLICATE KEY UPDATE c=VALUES(c);
執行後, c 的值會變為 7 (第二條與第一條重復, c 在直接取重復的值7).
注意:ON DUPLICATE KEY UPDATE只是MySQL的特有語法,並不是SQL標准語法!
這個語法和適合用在需要 判斷記錄是否存在,不存在則插入存在則更新的場景.
可以參考語法:
http://dev.mysql.com/doc/refman/5.1/zh/sql-syntax.html#insert
作者 雪人