一、mysql查詢的五種子句
where(條件查詢)、having(篩選)、group by(分組)、order by(排序)、
limit(限制結果數)
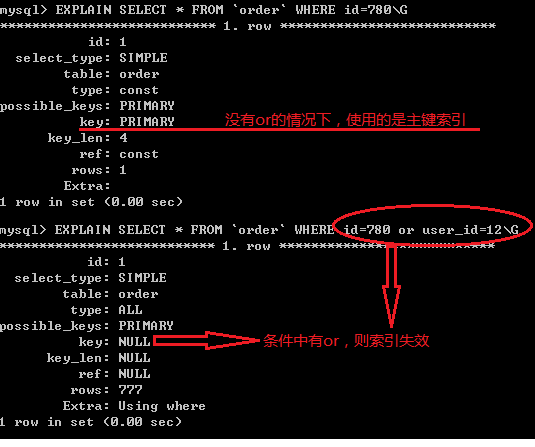
1、where常用運算符:
比較運算符
> , < ,= , != (< >),>= , <=
in(v1,v2..vn)
between v1 and v2 在v1至v2之間(包含v1,v2)
邏輯運算符
not ( ! ) 邏輯非
or ( || ) 邏輯或
and ( && ) 邏輯與
where price>=3000 and price <= 5000 or price >=500 and price <=1000
取500-1000或者3000-5000的值
where price not between 3000 and 5000
不在3000與5000之間的值
模糊查詢
like 像
通配符:
% 任意字符
_ 單個字符
where goods_name like '諾基亞%'
where goods_name like '諾基亞N__'
2、group by 分組 www.2cto.com
一般情況下group需與統計函數(聚合函數)一起使用才有意義
如:select goods_id,goods_name,cat_id,max(shop_price) from
goods group by cat_id;
這裡取出來的結果中的good_name是錯誤的!
因為shop_price使用了max函數,那麼它是取最大的,而語句中使用了group by 分組,
那麼goods_name並沒有使用聚合函數,它只是cat_id下的第一個商品,並不會因為shop_price改變
而改變
mysql中的五種統計函數:
(1)max:求最大值
select max(goods_price) from goods
這裡會取出最大的價格的值,只有值
#查詢每個欄目下價格最高的
select cat_id,max(goods_price) from goos group by cat_id;
#查出價格最高的商品編號
select goods_id,max(goods_price) from goods group by goods_id;
(2)min:求最小值
(3)sum:求總數和
#求商品庫存總和
select sum(goods_number) from goods;
(4)avg:求平均值
#求每個欄目的商品平均價格
select cat_id,avg(goods_price) from goods group by cat_id;
(5)count:求總行數
#求每個欄目下商品種類
select cat_id,count(*) from goods group by cat_id;
###要把每個字段名當成變量來理解,它可以進行運算###
例:查詢本店每個商品價格比市場價低多少;
select goods_id,goods_name,goods_price-market_price from goods;
查詢每個欄目下面積壓的貨款
select cat_id,sum(goods_price*goods_number) from goods
group by cat_id;
###可以用as來給計算結果取個別名###
select cat_id,sum(goods_price * goods_number) as hk from
goods group by cat_id
不僅列名可以取別名,表單也可以取別名 www.2cto.com
3、having 與where 的異同點
having與where類似,可以篩選數據,where後的表達式怎麼寫,having後就怎麼寫
where針對表中的列發揮作用,查詢數據
having對查詢結果中的列發揮作用,篩選數據
#查詢本店商品價格比市場價低多少錢,輸出低200元以上的商品
select goods_id,good_name,market_price - shop_price as s from goods having s>200 ;
//這裡不能用where因為s是查詢結果,而where只能對表中的字段名篩選
如果用where的話則是:
select goods_id,goods_name from goods where market_price - shop_price > 200;
#同時使用where與having
select cat_id,goods_name,market_price - shop_price as s from goods where cat_id = 3 having s > 200;
#查詢積壓貨款超過2萬元的欄目,以及該欄目積壓的貨款
select cat_id,sum(shop_price * goods_number) as t from goods group by cat_id having s > 20000
#查詢兩門及兩門以上科目不及格的學生的平均分
思路:
#先計算所有學生的平均分
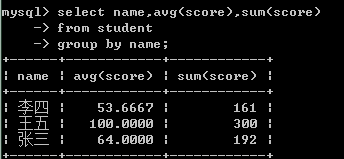
select name,avg(score) as pj from stu group by name;
#查出所有學生的掛科情況
select name,score<60 from stu;
#這裡score<60是判斷語句,所以結果為真或假,mysql中真為1假為0
#查出兩門及兩門以上不及格的學生
select name,sum(score<60) as gk from stu group by name having gk > 1;
#綜合結果
select name,sum(score<60) as gk,avg(score) as pj from stu group by name having gk >1;
4、order by
(1) order by price //默認升序排列
(2)order by price desc //降序排列
(3)order by price asc //升序排列,與默認一樣
(4)order by rand() //隨機排列,效率不高
#按欄目號升序排列,每個欄目下的商品價格降序排列
select * from goods where cat_id !=2 order by cat_id,price desc;
5、limit
limit [offset,] N
offset 偏移量,可選,不寫則相當於limit 0,N
N 取出條目
#取價格第4-6高的商品
select good_id,goods_name,goods_price from goods order by good_price desc limit 3,3; www.2cto.com
###查詢每個欄目下最貴的商品
思路:
#先對每個欄目下的商品價格排序
select cat_id,goods_id,goods_name,shop_price from goods order by cat_id,shop_price desc;
#上面的查詢結果中每個欄目的第一行的商品就是最貴的商品
#把上面的查詢結果理解為一個臨時表[存在於內存中]【子查詢】
#再從臨時表中選出每個欄目最貴的商品
select * from (select goods_id,goods_name,cat_id,shop_price
from goods order by cat_id,shop_price desc) as t group by cat_id;
#這裡使用group by cat_id是因為臨時表中每個欄目的第一個商品
就是最貴的商品,而group by前面沒有使用聚合函數,所以默認就取每個分組的第一行數據,
這裡以cat_id分組
良好的理解模型:
1、where後面的表達式,把表達式放在每一行中,看是否成立
2、字段(列),理解為變量,可以進行運算(算術運算和邏輯運算)
3、 取出結果可以理解成一張臨時表
二、mysql子查詢
1、where型子查詢
(把內層查詢結果當作外層查詢的比較條件)
#不用order by 來查詢最新的商品
select goods_id,goods_name from goods where goods_id =
(select max(goods_id) from goods);
#取出每個欄目下最新的產品(goods_id唯一)
select cat_id,goods_id,goods_name from goods where goods_id in(select max(goods_id) from goods group by cat_id);
2、from型子查詢
(把內層的查詢結果供外層再次查詢)
#用子查詢查出掛科兩門及以上的同學的平均成績
思路:
#先查出哪些同學掛科兩門以上
select name,count(*) as gk from stu where score < 60
having gk >=2;
#以上查詢結果,我們只要名字就可以了,所以再取一次名字
select name from (select name,count(*) as gk from stu
having gk >=2) as t;
#找出這些同學了,那麼再計算他們的平均分
select name,avg(score) from stu where name in
(select name from (select name,count(*) as gk from stu having gk >=2) as t) group by name;
3、exists型子查詢
(把外層查詢結果拿到內層,看內層的查詢是否成立)
#查詢哪些欄目下有商品,欄目表category,商品表goods
select cat_id,cat_name from category where exists
(select * from goods where goods.cat_id = category.cat_id); www.2cto.com
三、union的用法
(把兩次或多次的查詢結果合並起來,要求查詢的列數一致,
推薦查詢的對應的列類型一致,可以查詢多張表,多次查詢語句時如果列名不一樣,
則取第一次的列名!如果不同的語句中取出的行的每個列的值都一樣,那麼結果將自動會去重復,
如果不想去重復則要加all來聲明,即union all)
## 現有表a如下
id num
a 5
b 10
c 15
d 10
表b如下
id num
b 5
c 10
d 20
e 99
求兩個表中id相同的和
select id,sum(num) from (select * from ta union select * from tb)
as tmp group by id;
//以上查詢結果在本例中的確能正確輸出結果,但是,如果把tb中的b的值
改為10以查詢結果的b的值就是10了,因為ta中的b也是10,所以union後會被過濾掉一個重復的結果,
這時就要用union all
select id,sum(num) from (select * from ta union all select * from tb)
as tmp group by id;
#取第4、5欄目的商品,按欄目升序排列,每個欄目的商品價格降序排列,用union完成
select goods_id,goods_name,cat_id,shop_price from goods
where cat_id=4 union select goods_id,goods_name,cat_id,shop_price from goods
where cat_id=5 order by cat_id,shop_price desc;
【如果子句中有order by 需要用( ) 包起來,但是推薦在最後使用order by,
即對最終合並後的結果來排序】
#取第3、4個欄目,每個欄目價格最高的前3個商品,結果按價格降序排列
(select goods_id,goods_name,cat_id,shop_price from
goods where cat_id=3 order by shop_price desc limit 3) union (select goods_id,goods_name,cat_id,shop_price from goods where cat_id=4 order by
shop_price desc limit 3) order by shop_price desc;
四、左連接,右連接,內連接 www.2cto.com
現有表a有10條數據,表b有8條數據,那麼表a與表b的笛爾卡積是多少?
select * from ta,tb //輸出結果為8*10=80條
1、左連接
以左表為准,去右表找數據,如果沒有匹配的數據,則以null補空位,
所以輸出結果數>=左表原數據數
語法:select n1,n2,n3 from ta left join tb on ta.n1= ta.n2
[這裡on後面的表達式,不一定為=,也可以>,<等算術、邏輯運算符]【連接完成後,
可以當成一張新表來看待,運用where等查詢】
#取出價格最高的五個商品,並顯示商品的分類名稱
select goods_id,goods_name,goods.cat_id,cat_name,shop_price
from goods left join category on goods.cat_id = category.cat_id order by shop_price
desc limit 5;
2、右連接
a left join b 等價於 b right join a
推薦使用左連接代替右連接
語法:select n1,n2,n3 from ta right join tb on ta.n1= ta.n2
3、內連接
查詢結果是左右連接的交集,【即左右連接的結果去除null項後的並集
(去除了重復項)】
mysql目前還不支持 外連接(即左右連接結果的並集,不去除null項)
語法:select n1,n2,n3 from ta inner join tb on ta.n1= ta.n2
#########
例:現有表a
name hot
a 12
b 10
c 15
表b:
name hot
d 12
e 10
f 10
g 8
表a左連接表b,查詢hot相同的數據
select a.*,b.* from a left join b on a.hot = b.hot
查詢結果: www.2cto.com
name hot name hot
a 12 d 12
b 10 e 10
b 10 f 10
c 15 null null
從上面可以看出,查詢結果表a的列都存在,表b的數據只顯示符合條件的項目
再如表b左連接表a,查詢hot相同的數據
select a.*,b.* from b left join a on a.hot = b.hot
查詢結果為:
name hot name hot
d 12 a 12
e 10 b 10
f 10 b 10
g 8 null null
再如表a右連接表b,查詢hot相同的數據
select a.*,b.* from a right join b on a.hot = b.hot
查詢結果和上面的b left join a一樣
###練習,查詢商品的名稱,所屬分類,所屬品牌
select goods_id,goods_name,goods.cat_id,goods.brand_id,category.cat_name,brand.brand_name
from goods left join category on goods.cat_id = category.cat_id left join
brand on goods.brand_id = brand.brand_id limit 5;
理解:每一次連接之後的結果都可以看作是一張新表
###練習,現創建如下表
create table m(
id int,
zid int,
kid int,
res varchar(10),
mtime date
) charset utf8;
insert into m values
(1,1,2,'2:0','2006-05-21'),
(2,3,2,'2:1','2006-06-21'),
(3,1,3,'2:2','2006-06-11'),
(4,2,1,'2:4','2006-07-01');
create table t www.2cto.com
(tid int,tname varchar(10)) charset utf8;
insert into t values
(1,'申花'),
(2,'紅牛'),
(3,'火箭');
要求按下面樣式打印2006-0601至2006-07-01期間的比賽結果
樣式:
火箭 2:0 紅牛 2006-06-11
查詢語句為:
select zid,t1.tname as t1name,res,kid,t2.tname as t2name,mtime from m left join t as t1 on m.zid = t1.tid
left join t as t2 on m.kid = t2.tid where mtime between '2006-06-01' and '2006-07-01';
總結:可以對同一張表連接多次,以分別取多次數據
作者 cnbeir