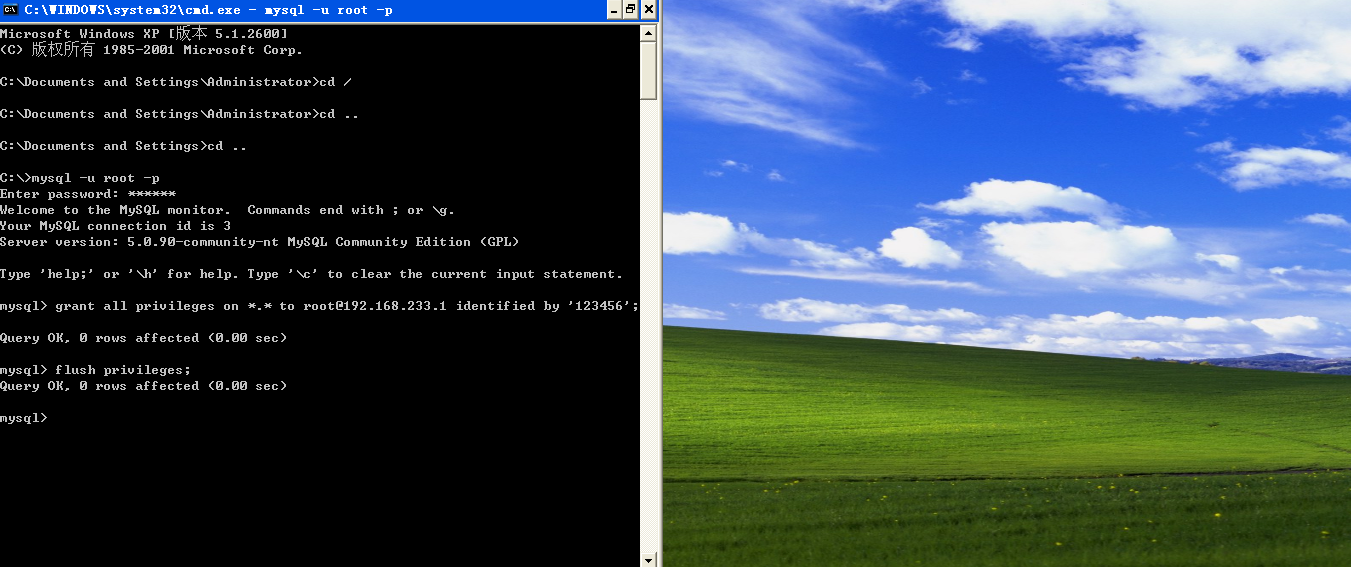
1. 與界面操作相比,通過SQL語句操作更為靈活,功能更為強大。 為了讓客服端能識別漢字: set character_set_client=gb2312; 為了讓結果不出現亂碼: set character_set_results=gb2312; www.2cto.com 2. 插入記錄命令 一旦創建了數據庫和表,下一步就是向表裡插入數據。通過insert或replace語句可以向表中插入一行或多行數據。(replace語句的用法和insert基本相同,使用replace可以在插入數據之前將與新紀錄沖突的舊記錄刪除,從而使新紀錄正常插入) insert into 表名(字段名1,字段名2.。。。) values(值1,值2.。。。); 例如: Insert into xs(學號,姓名,專業名,總學分,照片,備注)values('081101','王林','計算機' ,50,null,null); 或者:(如果提供的值的個數和順序與表中字段一致,可以省略字段名) insert into xs values('081101','王林','計算機',50,null,null); 或者:(如果只給表中的部分字段插入值時,要指明字段名) insert into xs(學號,姓名,專業名,出生日期,總學分) values('081101','王林','計算機','1990-02-10',50); 如果只給表的部分列插入數據,需要指定這些列。對於沒有指出的列,它們的值根據列默認值或有關屬性來確定,MySQL處理的原則是: 3. insert 語法格式: Insert [low_priority |delayed | high_priority] [ignore] [into] 表名 [(字段名,...)] www.2cto.com values ({expr | default},...),(...),... | SET col_name={expr| default}, ... [ on duplicate keyupdate=expr, ... ] (1)具有identity屬性的列,系統生成序號值來唯一標志列。 (2)具有默認值的列,其值為默認值。 (3)沒有默認值的列,若允許為空值,則其值為空值;若不允許為空值,則出錯。 (4)類型為timestamp的列,系統自動賦值。 values子句:包含各列需要插入的數據清單,數據的順序要與列的順序相對應。若表名後不給出列名,則在values子句中要給出每一列(除identity和timestamp類型的列)的值,如果列值為空,則值必須置為null,否則會出錯。values子句中的值: (1)expr:可以是一個常量、變量或一個表達式,也可以是空值null,其值的數據類型要與列的數據類型一致。例如,列的數據類型為int,插入的數據是‘aaa’就會出錯。當數據為字符型時要用單引號括起。 (2)default:指定為該列的默認值。前提是該列原先已經指定了默認值。如果列清單和values清單都為空,則insert會創建一行,每個列都設置成默認值。 Inert語句支持下列修飾符: www.2cto.com low_priority:可以使用在insert、delete和update等操作中,當原有客戶端正在讀取數據時,延遲操作的執行,直到沒有其他客戶端從表中讀取為止。 delayed:若使用此關鍵字,則服務器會把待插入的行放到一個緩沖器中,而發送insert delayed語句的客戶端會繼續運行。如果表正在被使用,則服務器會保留這些行。當表空閒時,服務器開始插入行,並定期檢查是否有新的讀取請求(僅適用於myisam、memory和archive表)。 High_priority:可以使用在selectT和insert操作中,使操作優先執行。 Ignore:使用此關鍵字,在執行語句時出現的錯誤就會被當做警告處理。 onduplicate key update…:使用此選項插入行後,若導致uniqe key或primary key出現重復值,則根據update後的語句修改舊行(使用此選項時delayed被忽略)。 set子句:set子句用於給列指定值,使用set子句時表名的後面省略列名。要插入數據的列名在set子句中指定,col_name為指定列名,等號後面為指定數據,未指定的列,列值指定為默認值。 4. 使用insert語句可以向表中插入一行數據,也可以插入多行數據,插入的行可以給出每列的值,也可只給出部分列的值,還可以向表中插入其他表的數據。 使用insert into…select…,可以快速地從一個或多個表中向一個表插入多個行。語法格式如下: Insert [low_priority |delayed | high_priority] [ignore] [into] 表名 [(字段名,...)] select ... [ on duplicate key update=expr, ... ] Select語句中返回的是一個查詢到的結果集,insert語句將這個結果集插入到指定表中,但結果集在每行數據的字段數、字段的數據類型要與被操作的表完全一致。 MySQL還支持圖片的存儲,圖片一般可以以路徑的形式來存儲,即插入圖片可以采用直接插入圖片的存儲路徑。當然也可以直接插入圖片本身,只要用load_file函數即可。 例如: Insert into XS values('081102', '程明', '計算機', 1, '1991-02-01',50, 'D:\IMAGE\picture.jpg', null); 下列語句是直接存儲圖片本身: Insert into XS values('081102', '程明', '計算機', 1, '1991-02-01',50, load_file('D:\IMAGE\picture.jpg'), null); 在表建完後設置主鍵,duplicateentry ‘學號’for key 1 ; 5. 刪除記錄: www.2cto.com delete from 表名 //刪除表中的所有記錄,此表變為了空表 delete from 表名 where 條件 //刪除表中符合條件的記錄 例如:delete from xs where 學號='081102'; drop table xs ; //刪除整張表,結構和記錄 truncate table 表名 //快速刪除表中的所有記錄 從單個表中刪除,語法格式: Delete [low_priority] [quick] [ignore] from表名 [where where_definition] [orderby...] [limit row_count] 說明: ● quick修飾符:可以加快部分種類的刪除操作的速度。 ● from子句:用於說明從何處刪除數據,後跟要刪除數據的表名。 ● where子句:where_definition中的內容為指定的刪除條件。如果省略where子句則刪除該表的所有行,where子句後面詳細介紹 ●order by子句:各行按照子句中指定的順序進行刪除,此子句只在與limit聯用時才起作用。 ●limit子句:用於告知服務器在控制命令被返回到客戶端前被刪除的行的最大值。 6. 從多個表中刪除行,語法格式: delete [low_priority] [quick] [ignore] 表名[.*] [,表名 [.*] ...] from table_references [wherewhere_definition] 或: delete [low_priority] [quick] [ignore] from tbl_name[.*] [, tbl_name[.*] ...] Using table_references [where where_definition] 說明:對於第一種語法,只刪除列於from子句之前的表中對應的行。對於第二種語法,只刪除列於from子句之中(在using子句之前)的表中對應的行。作用是,可以同時刪除多個表中的行,並使用其他的表進行搜索。 例子: 假設有3個表t1、t2、t3,它們都含有id列。要刪除t1中id值等於t2的id值的所有行和t2中id值等於t3的id值的所有行,使用如下語句: delete t1, t2 from t1, t2, t3 where t1.id=t2.id and t2.id=t3.id; 或: www.2cto.com Delete from t1, t2 using t1, t2, t3 where t1.id=t2.id and t2.id=t3.id; 7. 使用truncate table語句將刪除指定表中的所有數據,因此也稱其為清除表數據語句。 語法格式: truncate table 表名; 說明:由於TRUNCATETABLE語句將刪除表中的所有數據,且無法恢復,因此使用時必須十分小心。 truncate table 在功能上與不帶where子句的delete語句相同,二者均刪除表中的全部行。但 truncate table比delete速度快,且使用的系統和事務日志資源少。delete語句每次刪除一行,並在事務日志中為所刪除的每行記錄一項。而truncate table通過釋放存儲表數據所用的數據頁來刪除數據,並且只在事務日志中記錄頁的釋放。使用 truncate table,auto_increment計數器被重新設置為該列的初始值。 注意:對於參與了索引和視圖的表,不能使用 truncate table刪除數據,而應使用delete語句。 8. 修改記錄(更新記錄) 要修改表中的一行數據,可以使用update語句,update可以用來修改一個表,也可以修改多個表。簡要格式: update 表名 set 字段名1=值1 [,字段名2=值2.。。。] where 條件 修改單個表,語法格式: update[low_priority] [ignore] 表名 set col_name1=expr1 [, col_name2=expr2 ...] [where where_definition] [order by ...] [limit row_count] 說明: set子句:根據where子句中指定的條件對符合條件的數據行進行修改。若語句中不設定where子句,則更新所有行。col_name1、col_name2…為要修改列值的列名,expr1、expr2…可以是常量、變量或表達式。可以同時修改所在數據行的多個列值,中間用逗號隔開。 9. 修改多個表,語法格式: update [low_priority] [ignore] table_references set col_name1=expr1 [, col_name2=expr2 ...] [where where_definition] 說明:table_references中包含了多個表的聯合,各表之間用逗號隔開。 10. 按SQL包的格式導進來:source SQL包路徑; 顯示表的記錄:select * from 表名; www.2cto.com 插入記錄時,除了數值類型不用加引號,其他類型都要加單引號(比如:char、date等) 11. show語句 show tables或show tables from 庫名:顯示當前數據庫中所有表的名稱。 show databases:顯示MySQL中所有數據庫的名稱。 show columns from 表名 from庫名或show columnsfrom 庫名.表名:顯示表中列的名稱。 show grants for user_name:顯示一個用戶的權限,顯示結果類似於grant命令。 show index from table_name:顯示表的索引。 show staus:顯示一些系統特定資源的信息,例如,正在運行的線程數量。 show variables:顯示系統變量的名稱和值。 show processlist:顯示系統中正在運行的所有進程,也就是當前正在執行的查詢。大多數用戶可以查看他們自己的進程,但是如果他們擁有process權限,就可以查看所有人的進程,包括密碼。 show table status:顯示當前使用或者指定的database中的每個表的信息。信息包括表類型和表的最新更新時間。 show privileges:顯示服務器所支持的不同權限。 show create database 庫名:顯示創建某一個數據庫的create database語句。 show create table 表名:顯示創建一個表的create table語句。 show events:顯示所有事件的列表。 show innoDB status:顯示InnoDB存儲引擎的狀態。 show logs:顯示BDB存儲引擎的日志。 show warnings:顯示最後一個執行的語句所產生的錯誤、警告和通知。 show errors:只顯示最後一個執行語句所產生的錯誤。 show [storage] engines:顯示安裝後的可用存儲引擎和默認引擎。 show procedure status:顯示數據庫中所有存儲過程基本信息,包括所屬數據庫、存儲過程名稱、創建時間等。 show create procedure sp_name:顯示某一個存儲過程的詳細信息。 12. describe語句(即desc) describe語句用於顯示表中各列的信息,結果等於showcolumns from語句。 語法格式: {describe | desc} tb1_name [col_name |wild ] 說明: desc是describe的簡寫,二者用法相同。 www.2cto.com col_name可以是一個列名稱,或一個包含‘%’和‘_’的通配符的字符串,用於獲得對於帶有與字符串相匹配的名稱的各列的輸出。沒有必要在引號中包含字符串,除非其中包含空格或其他特殊字符。 例如: 顯示學生表: desc|describe xs; 顯示學生表學號列: desc xs 學號; 注意:用圖形界面時,輸入數據的時候要防止出現不必要的空格,否則檢索數據時可能會出現漏洞。 作者 tianyazaiheruan