基於MySQL水平分區的優化示例
我們知道,MYSQL5.1開始支持水平分區功能。我們來嘗試下如何在已經分區的表上面做查詢優化。
總體來說,優化的原則和對單獨的表做優化是一樣的,保證對磁盤上表的掃描次數減小。
www.2cto.com
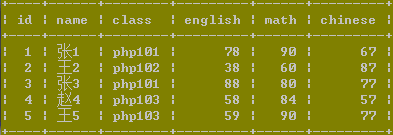
我們的表結構如下:
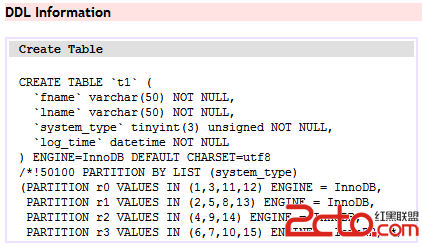
這裡已經插入2W多行數據進行測試。
看看這條查詢。
SELECT * FROM t1 WHERE system_type IN (1,2)
UNION ALL
SELECT * FROM t1 WHERE system_type = 3;
這條語句對system_type字段過濾了兩次,然後進行了一次UNION ALL。 但是不知道,其實對兩個分區一共進行了三次全表掃描。
我們改成這樣:
SELECT * FROM t1 WHERE system_type IN (1,3)
UNION ALL
SELECT * FROM t1 WHERE system_type = 2;
看似簡簡單單的改變,我們把對兩個分區的掃描從三次減少到了兩次。 但是這樣,開銷也很大,能不能把UNION ALL去掉呢?當然可以。
SELECT * FROM t1 WHERE system_type >0 and system_type < 4;
去掉了UNION ALL,但是遇到的問題是對分區的掃描變成了范圍查找,而且上下限不固定,相對來說,還有優化的空間。
www.2cto.com
我們改下對system_type列的過濾條件,變成如下:
SELECT * FROM t1 WHERE system_type in(1,2,3);
id select_type table partitions type possible_keys key key_len ref rows Extra
1 SIMPLE t1 r0,r1 ALL \N \N \N \N 17719 Using where
現在,依然是范圍掃描,但是上下限就很明了了。這樣對掃描分區來說,很快的找到上下限,比之前來的要快,開銷來的要小點了。
但是貌似還可以優化, 雖然過濾條件的上下限明顯了,但是對於區域之內的掃描還是全分區(相當於整個表的全表。)。
OK,那現在給這個列加上索引吧。
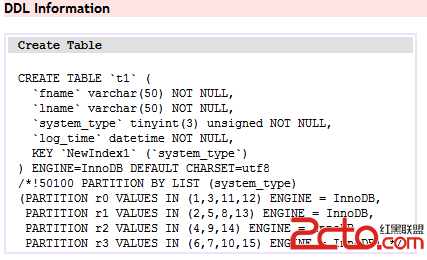 ALTER TABLE t1 ANALYZE PARTITION r0,r1;
SELECT * FROM t1 WHERE system_type in(1,2,3);
id select_type table partitions type possible_keys key key_len ref rows Extra
1 SIMPLE t1 r0,r1 range NewIndex1 NewIndex1 1 \N 6462 Using where
www.2cto.com
當然,我們的例子非常簡單, 這裡只是為了演示下在水平分區下如何進行SQL優化。
作者 四爺
ALTER TABLE t1 ANALYZE PARTITION r0,r1;
SELECT * FROM t1 WHERE system_type in(1,2,3);
id select_type table partitions type possible_keys key key_len ref rows Extra
1 SIMPLE t1 r0,r1 range NewIndex1 NewIndex1 1 \N 6462 Using where
www.2cto.com
當然,我們的例子非常簡單, 這裡只是為了演示下在水平分區下如何進行SQL優化。
作者 四爺