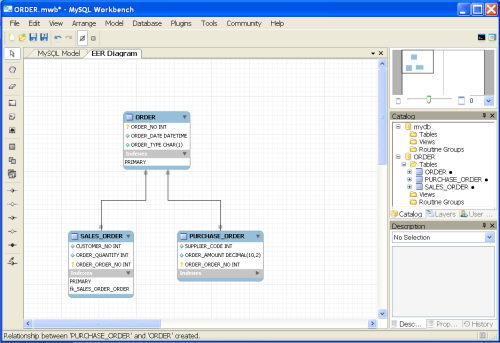
MySQL算法簡析
在MySQL 中,只有一種Join 算法,就是大名鼎鼎的Nested Loop Join,他沒有其他很多數據庫所提供的Hash Join,也沒有Sort Merge Join。顧名思義,Nested Loop Join 實際上就是通過驅動表的結果集作為循環基礎數據,然後一條一條的通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然後合並結果。如果還有第三個參與Join,則再通過前兩個表的Join 結果集作為循環基礎數據,再一次通過循環查詢條件到第三個表中查詢數據,如此往復。
MySQL 目前可以通過兩種算法來實現數據的排序操作。 www.2cto.com
1. 取出滿足過濾條件的用於排序條件的字段以及可以直接定位到行數據的行指針信息,在SortBuffer 中進行實際的排序操作,然後利用排好序之後的數據根據行指針信息返回表中取得客戶端請求的其他字段的數據,再返回給客戶端;
2. 根據過濾條件一次取出排序字段以及客戶端請求的所有其他字段的數據,並將不需要排序的字段存放在一塊內存區域中,然後在Sort Buffer 中將排序字段和行指針信息進行排序,最後再利用排序後的行指針與存放在內存區域中和其他字段一起的行指針信息進行匹配合並結果集,再按照順序返回給客戶端。
www.2cto.com
加大max_length_for_sort_data 參數的設置;
在MySQL 中,決定使用第一種老式的排序算法還是新的改進算法的依據是通過參數max_length_for_sort_data 來決定的。當我們所有返回字段的最大長度小於這個參數值的時候,MySQL 就會選擇改進後的排序算法,反之,則選擇老式的算法。所以,如果我們有充足的內存讓MySQL 存放需要返回的非排序字段的時候,可以加大這個參數的值來讓MySQL 選擇使用改進版的排序算法。
作者 bengda