mysql之知識點與細節
這些天又把mysql系統的看了一遍,溫故而知新……
1. char/varchar 類型區別
char定長字符串,長度固定為創建表時聲明的長度(0-255),長度不足時在它們的右邊填充空格以達到聲明長度。當檢索到CHAR值時,尾部的空格被刪除掉
varchar變長字符串(0-65535),VARCHAR值保存時只保存需要的字符數,另加一個字節來記錄長度(如果列聲明的長度超過255,則使用兩個字節),varchar值保存時不進行填充。當值保存和檢索時尾部的空格仍保留。 www.2cto.com
它們檢索的方式不同,char速度相對快些
注意它們的長度表示為字符數,無論中文還是英文均是那麼長
text搜索速度稍慢,因此如果不是特別大的內容,用char/varchar,另外text不能加默認值
2. windows中mysql自帶的客戶端中查詢的內容亂碼,那是因為系統的編碼為gbk,使用前發送一條"set names utf8"語句即可
3. 小數型:float(M,D),double(M,D),decimal(M,D) M代表總位數,不包括小數點,D代表小數位,如(5,2) -999.99——999.99
M是小數總位數,D是小數點後面的位數。如果M和D被省略,根據硬件允許的限制來保存值。單精度浮點數精確到大約7位小數位。
4. group by與聚合函數結合使用才有意義(sum,avg,max,min,count),group by 有一個原則,就是 select 後面的所有列中,沒有使用聚合函數的列,必須出現在 group by 後面,如果沒有出現,只取每類中第一行的結果

如果想查詢每個欄目下面最貴的商品:id,價格,商品名,種類。用select goods_id,cat_id,goods_name,max(shop_price) from goods group by cat_id;查詢的結果商品名,id是和最貴商品不匹配的,如果再加上order by哪?也是錯誤的,因為:Select語句執行有順序(語法前後也有):
where子句基於指定的條件對記錄行進行篩選;
group by子句將數據劃分為多個分組;
使用聚集函數進行計算; www.2cto.com
使用having子句篩選分組;
計算所有的表達式;
使用order by對結果集進行排序。
可以用下面查詢語句: select * from (select goods_id,cat_id,goods_name,shop_price from goods order by cat_id asc,shop_price desc) as tmp group by cat_id;
5. having having子句在查詢過程中慢於聚合語句(sum,min,max,avg,count).而where子句在查詢過程中則快於聚合語句(sum,min,max,avg,count)。
簡單說來:
where子句:
select sum(num) as rmb from order where id>10
//只有先查詢出id大於10的記錄才能進行聚合語句
having子句:
select reportsto as manager, count(*) as reports from employees
group by reportsto having count(*) > 4
以下這條語句是錯誤的:
select goods_id,cat_id,market_price-shop_price as sheng where cat_id=3 where sheng>200; 應改為:
select goods_id,cat_id,market_price-shop_price as sheng where cat_id=3 having sheng>200; where針對表中的列發揮作用,查詢數據,having針對查詢結果中的列發揮作用,篩選數據 www.2cto.com
看下面的一道面試題:
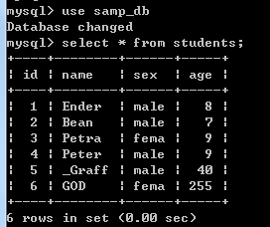
有下面一張表
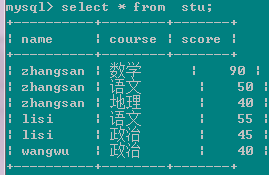
查詢:有兩門及兩門以上不及格成績同學的平均分
起初用的以下語句: select name,count(score<60) as s,avg(score) from stu group by name having s>1;這條語句是不行的
首先弄清以下2點:
a,count(exp) 參數無論是什麼,查詢的都是行數,不受參數結果影響如
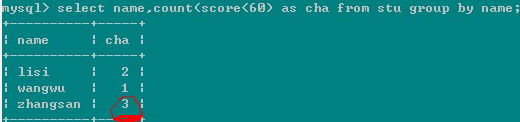
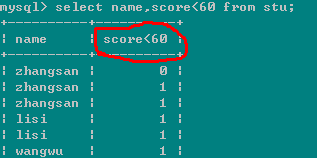
b,
可以用如下語句,將count換成sum:

或者:select name,avg(score) from stu group by name having sum(score<60)>1;寫法
6. 子查詢
a. where 子查詢:把內層查詢的結果作為外層查詢的比較條件。eg:查詢最新的商品
select max(goods_id),goods_name from goods;報錯:Mixing of GROUP columns (MIN(),MAX(),COUNT(),...) with no GROUP columns is illegal if there is no GROUP BY clause
可以用這樣的查詢:select goods_id,goods_name from goods where goods_id=(select max(goods_id) from goods); www.2cto.com
查詢每個欄目下的最新商品: select goods_id,cat_id,goods_name from goods where goods_id in(select max(goods_id) from goods group by cat_id);
b.from 型子查詢:把內層查詢結果當成臨時表,供外層sql再次查詢(臨時表必須加一個別名)
查詢每個欄目下最新商品 select * from (select goods_id,cat_id,goods_name from goods order by cat_id asc,goods_id desc) as t group by cat_id;
5中 查詢掛科兩門及以上同學的平均分 select sname from (select name as sname from stu) as tmp;
c. exists子查詢:把外層查詢的結果變量,拿到內層,看內層的查詢是否成立
查詢有商品的欄目:select cat_id,cat_name from category where exists (select * from goods where goods.cat_id=category.cat_id);
由於沒有條件,將會查出所有欄目: select cat_id,cat_name from category where exists (select * from goods); 用in也可實現
7. in(v1,v2-----) between v1 and v2(包括v1,v2) like(%,_) order by column1(asc/desc),column2(asc/desc)先按第一個排序,然後在此基礎上按第二個排序
8. union 把兩次或多次查詢結果合並起來
兩次查詢的列數一致 ,對應列的類型一致
列名不一致時,取第一個sql的列名
如果不同的語句中取出的行的值相同,那麼相同的行將會合並(去重復),如果不去重用union all來指定
如果子句中有order by,limit 子句必須加(),
select * from ta union all select * from tb;
取第四欄目商品,價格降序排列,還想取第五欄目商品,價格也按降序排列
(select goods_id,cat_id,goods_name,shop_price from goods where cat_id=4 order by shop_price desc) union (select goods_id,cat_id,goods_name,shop_price from goods where cat_id=5 order by shop_price desc); www.2cto.com
推薦放到所有子句之後,即:對最終合並的結果來排序
( select goods_id,cat_id,goods_name,shop_price from goods where cat_id=4 order by shop_price desc) union (select goods_id,cat_id,goods_name,shop_price from goods where cat_id=5 order by shop_price desc);
9. 連接查詢
左連接:
select column1,column2,columnN from ta left join tb on ta列=tb列[此處表連接成一張大表,完全當成普通的表看]
where group,having....照常寫
右連接:
select column1,column2,columnN from ta right join tb on ta列=tb列[此處表連接成一張大表,完全當成普通的表看] www.2cto.com
where group,having....照常寫
內連接:
select column1,column2,columnN from ta inner join tb on ta列=tb列[此處表連接成一張大表,完全當成普通的表看]
where group,having....照常寫
左連接以左表為准,去右表找匹配數據,沒有匹配的列用null補齊,有多個的均列出
如有下兩表:
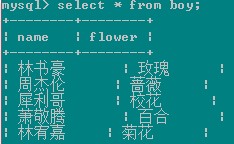
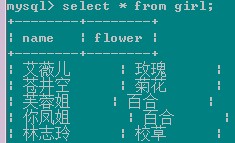
select boy.*,girl.* from boy left join girl on boy.flower=girl.flower;
結果:

左右連接可以相互轉化,推薦用左連接,數據庫移植方便 www.2cto.com
內連接:查詢左右表都有的數據(左右連接的交集) 選取都有配對的組合
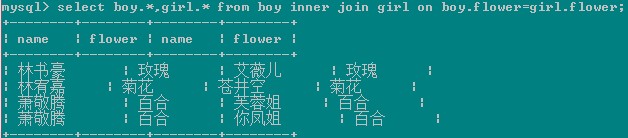
左或右連接查詢實際上是指定以哪個表的數據為准,而默認(不指定左右連接)是以兩個表中都存在的列數據為准,也就是inner join
mysql不支持外連接 outer join 即左右連接的並集
當多個表中都有的字段要指明哪個表中的字段
三個表連接查詢 brand,goods,category
select g.goods_id,cat_name,g.brand_id,brand_name,goods_name from goods g left join brand b on b.brand_id=g.brand_id left join category c on g.cat_id=c.cat_id;
作者 ljfbest