正則表達式描述了一組字符串。最簡單的正則表達式是不含任何特殊字符的正則表達式。例如,正則表達式hello匹配hello。
非平凡的正則表達式采用了特殊的特定結構,從而使得它們能夠與1個以上的字符串匹配。例如,正則表達式hello|word匹配字符串hello或字符串word。
www.2cto.com
作為一個更為復雜的示例,正則表達式B[an]*s匹配下述字符串中的任何一個:Bananas,Baaaaas,Bs,以及以B開始、以s結束、並在其中包含任意數目a或n字符的任何其他字符串。
對於REGEXP操作符,正則表達式可以使用任何下述特殊字符和結構:
· ^
匹配字符串的開始部分。
mysql>SELECT 'fo\nfo' REGEXP '^fo$'; ->0 mysql> SELECT 'fofo' REGEXP '^fo'; -> 1
· $
匹配字符串的結束部分。
mysql>SELECT 'fo\no' REGEXP '^fo\no$'; ->1 mysql> SELECT 'fo\no' REGEXP '^fo$'; ->0
· .
匹配任何字符(包括回車和新行)。
mysql>SELECT 'fofo' REGEXP '^f.*$'; ->1 mysql> SELECT 'fo\r\nfo' REGEXP '^f.*$';-> 1
·a*
匹配0或多個a字符的任何序列。
mysql>SELECT 'Ban' REGEXP '^Ba*n'; ->1 mysql> SELECT 'Baaan' REGEXP '^Ba*n'; ->1 mysql> SELECT 'Bn' REGEXP '^Ba*n'; -> 1
·a+
匹配1個或多個a字符的任何序列。
mysql>SELECT 'Ban' REGEXP '^Ba+n'; ->1 mysql> SELECT 'Bn' REGEXP '^Ba+n'; -> 0
·a?
匹配0個或1個a字符。
mysql>SELECT 'Bn' REGEXP '^Ba?n'; ->1 mysql> SELECT 'Ban' REGEXP '^Ba?n'; ->1 mysql> SELECT 'Baan' REGEXP '^Ba?n'; ->0
·de|abc
匹配序列de或abc。
mysql>SELECT 'pi' REGEXP 'pi|apa'; ->1 mysql> SELECT 'axe' REGEXP 'pi|apa'; ->0 mysql> SELECT 'apa' REGEXP 'pi|apa'; ->1
mysql>SELECT 'apa' REGEXP '^(pi|apa)$'; -> 1 mysql>SELECT 'pi' REGEXP '^(pi|apa)$'; -> 1 mysql>SELECT 'pix' REGEXP '^(pi|apa)$'; -> 0
· (abc)*
匹配序列abc的0個或多個實例。
mysql>SELECT 'pi' REGEXP '^(pi)*$'; ->1
mysql> SELECT 'pip' REGEXP '^(pi)*$'; -> 0
mysql> SELECT 'pipi' REGEXP '^(pi)*$';-> 1
· {1}, {2,3}
{n}或{m,n}符號提供了編寫正則表達式的更通用方式,能夠匹配模式的很多前述原子(或“部分”)。m和n均為整數。
o a*
可被寫入為a{0,}。
o a+
可被寫入為a{1,}。
o a?
可被寫入為a{0,1}。
更准確地講,a{n}與a的n個實例准確匹配。a{n,}匹配a的n個或更多實例。a{m,n}匹配a的m~n個實例,包含m和n。
m和n必須位於0~RE_DUP_MAX(默認為255)的范圍內,包含0和RE_DUP_MAX。如果同時給定了m和n,m必須小於或等於n。
mysql>SELECT 'abcde' REGEXP 'a[bcd]{2}e'; -> 0mysql> SELECT 'abcde' REGEXP'a[bcd]{3}e'; -> 1mysql> SELECT 'abcde' REGEXP 'a[bcd]{1,10}e'; -> 1
· [a-dX], [^a-dX]
匹配任何是(或不是,如果使用^的話)a、b、c、d或X的字符。兩個其他字符之間的“-”字符構成一個范圍,與從第1個字符開始到第2個字符之間的所有字符匹配。
例如,[0-9]匹配任何十進制數字。要想包含文字字符“]”,它必須緊跟在開括號“[”之後。要想包含文字字符“-”,它必須首先或最後寫入。對於[]對內未定義任何特殊含義的任何字符,僅與其本身匹配。
mysql>SELECT 'aXbc' REGEXP '[a-dXYZ]'; -> 1mysql> SELECT 'aXbc' REGEXP'^[a-dXYZ]$'; -> 0mysql> SELECT 'aXbc' REGEXP '^[a-dXYZ]+$'; ->1mysql> SELECT 'aXbc' REGEXP '^[^a-dXYZ]+$'; -> 0mysql> SELECT 'gheis'REGEXP '^[^a-dXYZ]+$'; -> 1mysql> SELECT 'gheisa' REGEXP '^[^a-dXYZ]+$';-> 0
· [.characters.]
在括號表達式中(使用[和]),匹配用於校對元素的字符序列。字符為單個字符或諸如新行等字符名。在文件regexp/cname.h中,可找到字符名稱的完整列表。
mysql>SELECT '~' REGEXP '[[.~.]]'; -> 1 mysql> SELECT '~' REGEXP '[[.tilde.]]'; ->1
· [=character_class=]
在括號表達式中(使用[和]),[=character_class=]表示等同類。它與具有相同校對值的所有字符匹配,包括它本身,例如,如果o和(+)均是等同類的成員,那麼[[=o=]]、[[=(+)=]]和[o(+)]是同義詞。等同類不得用作范圍的端點。
· [:character_class:]
在括號表達式中(使用[和]),[:character_class:]表示與術語類的所有字符匹配的字符類。標准的類名稱是:
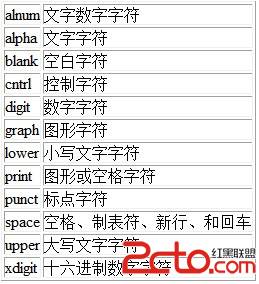 它們代表在ctype(3)手冊頁面中定義的字符類。特定地區可能會提供其他類名。字符類不得用作范圍的端點。
mysql>SELECT 'justalnums' REGEXP '[[:alnum:]]+'; ->1 mysql> SELECT '!!' REGEXP '[[:alnum:]]+';-> 0
· [[:<:]], [[:>:]]
這些標記表示word邊界。它們分別與word的開始和結束匹配。word是一系列字字符,其前面和後面均沒有字字符。字字符是alnum類中的字母數字字符或下劃線(_)。
www.2cto.com
mysql>SELECT 'a word a' REGEXP '[[:<:]]word[[:>:]]'; -> 1
mysql> SELECT 'a xword a' REGEXP'[[:<:]]word[[:>:]]'; -> 0
要想在正則表達式中使用特殊字符的文字實例,應在其前面加上2個反斜槓“\”字符。MySQL解析程序負責解釋其中一個,正則表達式庫負責解釋另一個。例如,要想與包含特殊字符“+”的字符串“1+2”匹配,在下面的正則表達式中,只有最後一個是正確的:
mysql>SELECT '1+2' REGEXP '1+2'; ->0
mysql> SELECT '1+2' REGEXP '1\+2'; -> 0
mysql> SELECT '1+2' REGEXP '1\\+2'; -> 1
它們代表在ctype(3)手冊頁面中定義的字符類。特定地區可能會提供其他類名。字符類不得用作范圍的端點。
mysql>SELECT 'justalnums' REGEXP '[[:alnum:]]+'; ->1 mysql> SELECT '!!' REGEXP '[[:alnum:]]+';-> 0
· [[:<:]], [[:>:]]
這些標記表示word邊界。它們分別與word的開始和結束匹配。word是一系列字字符,其前面和後面均沒有字字符。字字符是alnum類中的字母數字字符或下劃線(_)。
www.2cto.com
mysql>SELECT 'a word a' REGEXP '[[:<:]]word[[:>:]]'; -> 1
mysql> SELECT 'a xword a' REGEXP'[[:<:]]word[[:>:]]'; -> 0
要想在正則表達式中使用特殊字符的文字實例,應在其前面加上2個反斜槓“\”字符。MySQL解析程序負責解釋其中一個,正則表達式庫負責解釋另一個。例如,要想與包含特殊字符“+”的字符串“1+2”匹配,在下面的正則表達式中,只有最後一個是正確的:
mysql>SELECT '1+2' REGEXP '1+2'; ->0
mysql> SELECT '1+2' REGEXP '1\+2'; -> 0
mysql> SELECT '1+2' REGEXP '1\\+2'; -> 1