MyISAM引擎使用B+Tree作為索引結構,葉節點的data域存放的是數據記錄的地址。下圖是MyISAM索引的原理圖:
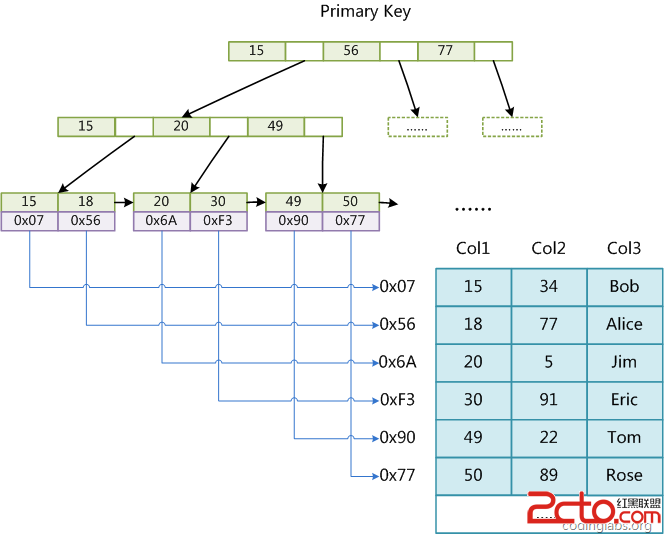 這裡設表一共有三列,假設我們以Col1為主鍵,則上圖是一個MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件僅僅保存數據記錄的地址。在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重復。如果我們在Col2上建立一個輔助索引,則此索引的結構如下圖所示:
這裡設表一共有三列,假設我們以Col1為主鍵,則上圖是一個MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件僅僅保存數據記錄的地址。在MyISAM中,主索引和輔助索引(Secondary key)在結構上沒有任何區別,只是主索引要求key是唯一的,而輔助索引的key可以重復。如果我們在Col2上建立一個輔助索引,則此索引的結構如下圖所示:
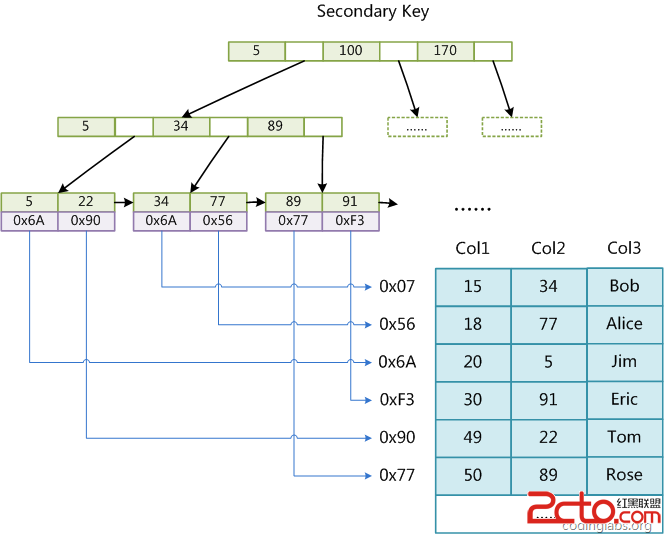 同樣也是一顆B+Tree,data域保存數據記錄的地址。因此,MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址,讀取相應數據記錄。
MyISAM的索引方式也叫做“非聚集”的,之所以這麼稱呼是為了與InnoDB的聚集索引區分。
同樣也是一顆B+Tree,data域保存數據記錄的地址。因此,MyISAM中索引檢索的算法為首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,則取出其data域的值,然後以data域的值為地址,讀取相應數據記錄。
MyISAM的索引方式也叫做“非聚集”的,之所以這麼稱呼是為了與InnoDB的聚集索引區分。
InnoDB索引實現
雖然InnoDB也使用B+Tree作為索引結構,但具體實現方式卻與MyISAM截然不同。
第一個重大區別是InnoDB的數據文件本身就是索引文件。從上文知道,MyISAM索引文件和數據文件是分離的,索引文件僅保存數據記錄的地址。而在InnoDB中,表數據文件本身就是按B+Tree組織的一個索引結構,這棵樹的葉節點data域保存了完整的數據記錄。這個索引的key是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
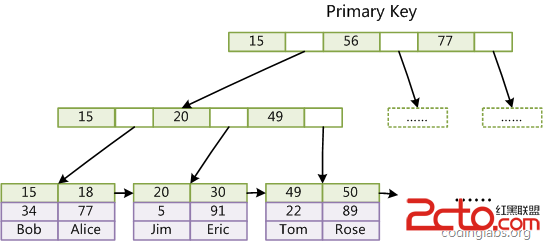 上圖是InnoDB主索引(同時也是數據文件)的示意圖,可以看到葉節點包含了完整的數據記錄。這種索引叫做聚集索引。因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長整形。
上圖是InnoDB主索引(同時也是數據文件)的示意圖,可以看到葉節點包含了完整的數據記錄。這種索引叫做聚集索引。因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長整形。
第二個與MyISAM索引的不同是InnoDB的輔助索引data域存儲相應記錄主鍵的值而不是地址。換句話說,InnoDB的所有輔助索引都引用主鍵作為data域。例如,下圖為定義在Col3上的一個輔助索引:
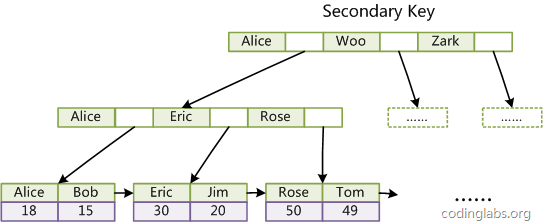 這裡以英文字符的ASCII碼作為比較准則。聚集索引這種實現方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
這裡以英文字符的ASCII碼作為比較准則。聚集索引這種實現方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然後用主鍵到主索引中檢索獲得記錄。
了解不同存儲引擎的索引實現方式對於正確使用和優化索引都非常有幫助,例如知道了InnoDB的索引實現後,就很容易明白為什麼不建議使用過長的字段作為主鍵,因為所有輔助索引都引用主索引,過長的主索引會令輔助索引變得過大。再例如,用非單調的字段作為主鍵在InnoDB中不是個好主意,因為InnoDB數據文件本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時數據文件為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增字段作為主鍵則是一個很好的選擇。