架構圖
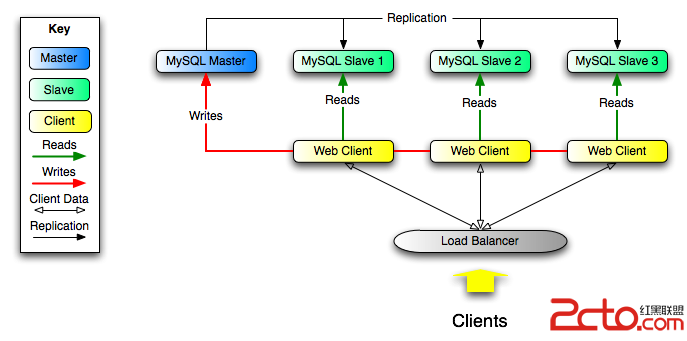 Replication原理
Replication原理
Mysql 的 Replication 是一個異步的復制過程,從一個MySQL節點(稱之為Master)復制到另一個MySQL節點(稱之Slave)。在 Master 與 Slave 之間的實現整個復制過程主要由三個線程來完成,其中兩個線程(SQL 線程和 I/O 線程)在 Slave 端,另外一個線程(I/O 線程)在 Master 端。
www.2cto.com
要實現 MySQL 的 Replication ,首先必須打開 Master 端的 Binary Log,因為整個復制過程實際上就是 Slave 從 Master 端獲取該日志然後再在自己身上完全順序的執行日志中所記錄的各種操作。
看上去MySQL的Replication原理非常簡單,總結一下:
* 每個從僅可以設置一個主。
* 主在執行sql之後,記錄二進制log文件(bin-log)。
* 從連接主,並從主獲取binlog,存於本地relay-log,並從上次記住的位置起執行sql,一旦遇到錯誤則停止同步。
從這幾條Replication原理來看,可以有這些推論:
* 主從間的數據庫不是實時同步,就算網絡連接正常,也存在瞬間,主從數據不一致。
* 如果主從的網絡斷開,從會在網絡正常後,批量同步。
* 如果對從進行修改數據,那麼很可能從在執行主的bin-log時出現錯誤而停止同步,這個是很危險的操作。所以一般情況下,非常小心的修改從上的數據。
* 一個衍生的配置是雙主,互為主從配置,只要雙方的修改不沖突,可以工作良好。
* 如果需要多主的話,可以用環形配置,這樣任意一個節點的修改都可以同步到所有節點。
主從設置
因為原理比較簡單,所以Replication從MySQL 3就支持,並在所有平台下可以工作,多個MySQL節點甚至可以不同平台,不同版本,不同局域網。做Replication配置包括用戶和my.ini(linux下為my.cnf)兩處設置。
首先在主MySQL節點上,為slave創建一個用戶:
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'192.168.1.10' IDENTIFIED BY 'slave';
實際上,為支持主從動態同步,或者手動切換,一般都是在所有主從節點上創建好這個用戶。然後就是MySQL本身的配置了,這需要修改my.cnf或者my.ini文件。在mysqld這一節下面增加:
www.2cto.com
server-id=1
auto-increment-increment=2
auto-increment-offset=1
log-bin
binlog-do-db=mstest
binlog_format=mixed
master-host=192.168.1.62
master-user=slave
master-password=slave
replicate-do-db=mstest
上面這兩段設置,前一段是為主而設置,後一段是為從設置的。也就是說在兩個MySQL節點上,各加一段就好。binlog-do-db和 replicate-do-db就是設置相應的需要做同步的數據庫了,auto-increment-increment和auto- increment-offset是為了支持雙主而設置的(參考下一節),在只做主從的時候,也可以不設置。
雙主的設置
從原理論來看MySQL也支持雙主的設置,即兩個MySQL節點互為主備,不過雖然理論上,雙主只要數據不沖突就可以工作的很好,但實際情況中還 是很容發生數據沖突的,比如在同步完成之前,雙方都修改同一條記錄。因此在實際中,最好不要讓兩邊同時修改。即邏輯上仍按照主從的方式工作。但雙主的設置 仍然是有意義的,因為這樣做之後,切換主備會變的很簡單。因為在出現故障後,如果之前配置了雙主,則直接切換主備會很容易。
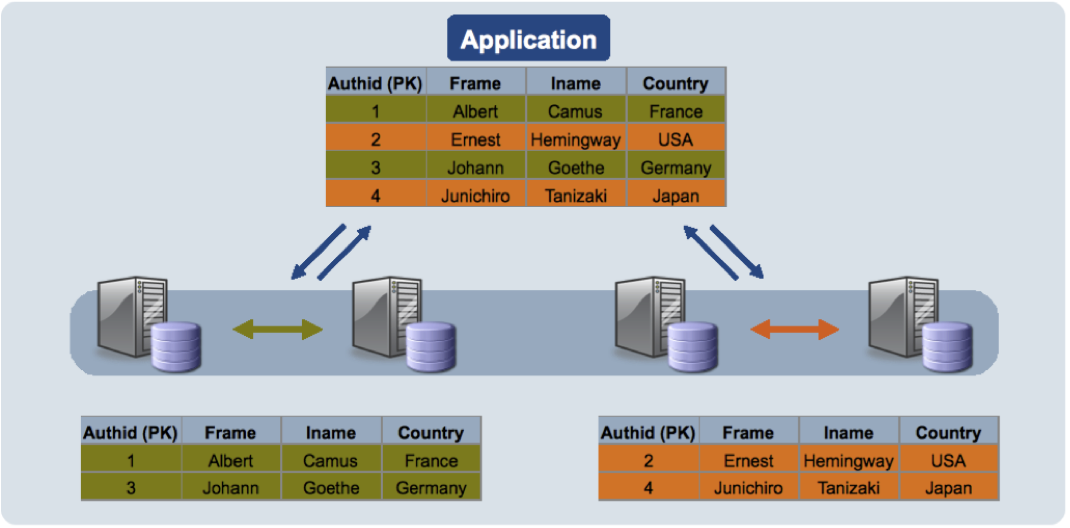
雙主在設置時,只需將上面的一段設置復制一份,分別寫入兩個MySQL節點的配置文件,但要修改相應的server-id,auto- increment-offset和master-host。auto-increment-offset就是為了讓雙主同時在一張表中進行添加操作時不 會出現id沖突,所以在兩個節點上auto-increment-offset設置為不同的值就好。 另:不要忘了,在兩個節點上都為對方創建用戶。應用層的負載均衡 本文只介紹了MySQL自身的Repilication配置,在上面的圖中也可以看出,有了Replication,還需要應用層(或者中間件)做一個負載均衡,這樣才能最大程度發揮MySQL Replication的優勢,這些將在以後探討。
Mysql的 Replication 是一個異步的復制過程,從一個 Mysql instace(我們稱之為 Master)復制到另一個 Mysql instance(我們稱之 Slave)。在 Master 與 Slave 之間的實現整個復制過程主要由三個線程來完成,其中兩個線程(Sql線程和IO線程)在 Slave 端,另外一個線程(IO線程)在 Master 端。
要實現 MySQL 的 Replication ,首先必須打開 Master 端的Binary Log(mysql-bin.xxxxxx)功能,否則無法實現。因為整個復制過程實際上就是Slave從Master端獲取該日志然後再在自己身上完全 順序的執行日志中所記錄的各種操作。打開 MySQL 的 Binary Log 可以通過在啟動 MySQL Server 的過程中使用 “—log-bin” 參數選項,或者在 my.cnf 配置文件中的 mysqld 參數組([mysqld]標識後的參數部分)增加 “log-bin” 參數項。
www.2cto.com
MySQL 復制的基本過程如下:
1. Slave 上面的IO線程連接上 Master,並請求從指定日志文件的指定位置(或者從最開始的日志)之後的日志內容;
2. Master 接收到來自 Slave 的 IO 線程的請求後,通過負責復制的 IO 線程根據請求信息讀取指定日志指定位置之後的日志信息,返回給 Slave 端的 IO 線程。返回信息中除了日志所包含的信息之外,還包括本次返回的信息在 Master 端的 Binary Log 文件的名稱以及在 Binary Log 中的位置;
3. Slave 的 IO 線程接收到信息後,將接收到的日志內容依次寫入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,並將讀取到的Master端的bin-log的文件名和位置記錄到master- info文件中,以便在下一次讀取的時候能夠清楚的高速Master“我需要從某個bin-log的哪個位置開始往後的日志內容,請發給我”
4. Slave 的 SQL 線程檢測到 Relay Log 中新增加了內容後,會馬上解析該 Log 文件中的內容成為在 Master 端真實執行時候的那些可執行的 Query 語句,並在自身執行這些 Query。這樣,實際上就是在 Master 端和 Slave 端執行了同樣的 Query,所以兩端的數據是完全一樣的。