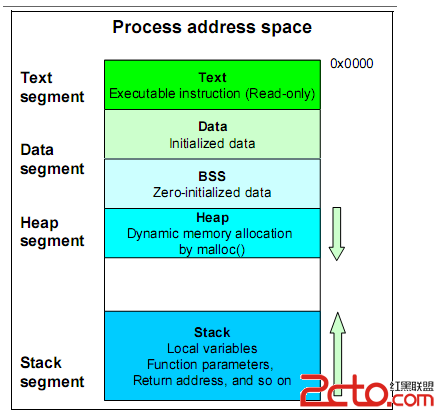
MySQL字符集和copy_and_convert 關於copy_and_convert 在對MySQL做業務壓力測試的時候,我們在perf結果中發現 copy_and_convert 是一個耗費cpu的操作。這個函數的意思,就是在字符集之間做內容轉換。 如果源和目標的字符集相同,就可以直接用memcpy,這顯然比做字符集轉換(按字節或字長拷貝更快,和節省cpu) 當整個系統是CPU瓶頸時,我們希望能夠減少這種cpu消耗。 www.2cto.com 一次查詢涉及的拷貝 如果我們執行一個簡單的select語句,會涉及到兩部分的內容:metadata和data。MySQL的返回包是能夠“自解析”的,也就是說不僅有內容,還有描述信息。這些描述信息我們稱為metadata。 在將這兩部分信息返回給客戶端的時候,就涉及到字符串拷貝,如果源字符集和目標字符集不同,就需要作轉換。 字符集裡面可以定義的部分 1、 表的字符集 比如我們創建如下的表 www.2cto.com CREATE TABLE `t` ( `c` int(11) DEFAULT NULL, `d` varchar(50) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=gbk; 這就定義了這個表的字符集,要求存入數據按照gbk格式存儲。在我們查詢的時候,從表中讀出的數據,就是我們上文說到的“源字符集”,在這裡是gbk. 比如 Insert t values(2012, ‘南方很冷’); 2、連接字符集 在連接的時候我們可以在mysql客戶端指定參數 mysql -default-character-set=gbk ,表示我們接收的內容希望是gbk編碼,這個就是上文說的“目標字符集”。 一般我們會被建議:連接字符集和表字符集相同。 有的文章說防止亂碼—-亂碼倒是不會,實際的原因就是在內容拷貝時避免字符集轉換計算。 本文要說的“但是” 但是即使這麼做,在壓力測試(或者你gdb)時,還是會發現會調用到 copy_and_convert。 www.2cto.com 原因有二: 首先,metadata部分,是固定的使用utf8,這個值可以從show variables like ‘character_set_system’;的結果看到,hardcode,配置無法修改。 其次,雖然我們定義表字符集是gbk, 但是整型字段是是Latin1存儲, #define my_charset_numeric my_charset_latin1,配置無法修改。 因此在我們上面的設置中,一次查詢,在傳回metadata的時候需要utf8->gbk, 返回結果中c這個字段需要latin1->gbk. 問題和建議 從上面分析知道,這存在的問題就是,無論用戶怎麼設置,都無法完全避免這種轉換。 由於數字類型轉成字符串後,使用什麼字符集都占用一樣的空間。 1) 在代碼上最簡單的修改可以如下: 將 #define my_charset_numeric my_charset_latin1 改成 #define my_charset_numeric my_charset_utf8_general_ci 這樣跟metadata部分相同,然後建表和客戶端都是使用utf-8。 2) 更靈活一點是把character_set_system改成可配置,然後整型存儲按照用戶定義的字符集。