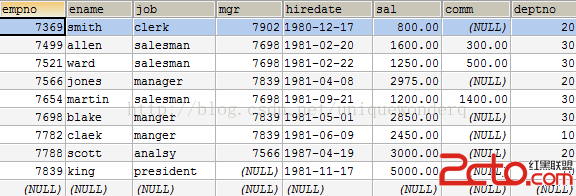
mysql筆試題一:查詢where having以及統計函數的使用 題目: 有表如下: www.2cto.com 只用一個select語句查詢:不及格科目大於或等於2科的學生,的平均分(所有科目的平均分)。 [sql] <span style="font-size:18px;">mysql> select * from student; +------+---------+--------+ | name | subject | score | +------+---------+--------+ | 張三 | 數學 | 80 | | 張三 | 語文 | 53 | | 張三 | 英語 | 59 | | 李四 | 數學 | 55 | | 李四 | 語文 | 56 | | 李四 | 英語 | 50 | | 王五 | 數學 | 100 | | 王五 | 語文 | 90 | +------+---------+--------+ 8 rows in set</span> 要點: www.2cto.com 1、要統計每個學生不及格科目的個數。 2、計算平均分。 誤解一:使用count統計。count永遠是統計的所有行! 正解:用sum統計。先計算所有人的平均分,再篩選。 [sql] <span style="font-size:18px;">mysql> select name,avg(score),sum(score < 60) as cnt from student group by name having cnt >= 2; +------+------------+-----+ | name | avg(score) | cnt | +------+------------+-----+ | 張三 | 64.0000 | 2 | | 李四 | 53.6667 | 3 | +------+------------+-----+ 2 rows in set</span> sum(score < 60) 就是統計 掛科數目。 having 是用於篩選的,這裡不用用where。where只能用於存在的列。 當然也可以用 子查詢 左鏈接, 這樣反到麻煩了。 題目2:還是上面的表。 查詢每個學生的最大分數的科目及分數。 誤解1: [sql] mysql> select *,max(score) from student group by name; +------+---------+-------+------------+ | name | subject | score | max(score) | +------+---------+-------+------------+ | 張三 | 數學 | 80 | 80 | | 李四 | 數學 | 55 | 56 | | 王五 | 數學 | 100 | 100 | +------+---------+-------+------------+ 3 rows in set 雖然查出了最大分數,但顯示的科目是錯誤的。因為group by總是取第一條記錄。 正解: 1、where 子查詢 (先找到每個學生的最大分數, 在根據分數刷新出記錄)。 [sql] mysql> select * from student where score in(select max(score) from student group by name); +------+---------+-------+ | name | subject | score | +------+---------+-------+ | 張三 | 數學 | 80 | | 李四 | 語文 | 56 | | 王五 | 數學 | 100 | +------+---------+-------+ 3 rows in set 2、from子查詢 (先排序,在group by 拿到第一個,即最大分數的那條記錄) www.2cto.com [sql] mysql> select * from (select * from student order by score desc) as tmp group by name; +------+---------+-------+ | name | subject | score | +------+---------+-------+ | 張三 | 數學 | 80 | | 李四 | 語文 | 56 | | 王五 | 數學 | 100 | +------+---------+-------+ 3 rows in set 整兩種方法是有很大區別的,第二種只能取出一條記錄,如果最大分數相同的話。