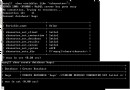
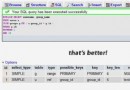
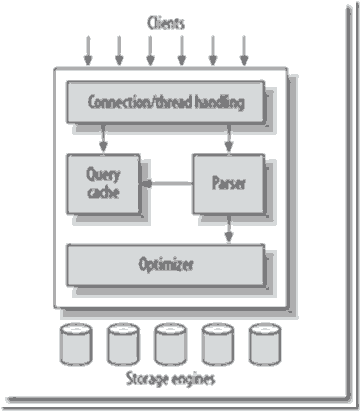
Mysql SQL性能優化之order mysql的order在排序時,會被select出來的數據多少所影響, 數據列越多,排序越慢,為了說明這個問題,請看幾個例子。 www.2cto.com 高效的查詢 低性能: select id,job_name from test_results where id <96836230 order by id desc limit 0,1; 1 rows fetched (390 ms) 高性能: select id,job_name from test_results where id =(select id from test_results where id<110836230 order by id desc limit 0,1 ) limit 1; 1 rows fetched (281 ms) 高效的分頁查詢 www.2cto.com 低性能: select id,job_name from test_results order by id desc limit 1200000,100; 100 rows fetched (34.616 sec) 高性能: select id,job_name from test_results join (select id from test_results order by id desc limit 1300000,100) as t2 using(id); 100 rows fetched (5.460 sec) 接下來我們分析其原因,首先從mysql的執行順序開始講起, 執行順序從上到下: www.2cto.com FROM < left_table > ON < join_condition > < join_type> JOIN < right_table> WHERE < where_condition> GROUP BY < group_by_list > HAVING < having_condition> SELECT DISTINCT ORDER BY < order_by_list> 所以得出結論,select出來的數據越多,排序越慢。 減少了order by中的排序數據,再去join或者=查詢即可加快執行效率。