MySQL 5.6 Replication復制FAQ
原文請參照MySQL官方文檔Reference Manual,版本5.6.10。
復制功能使得數據可以從一個MySQL數據庫(master主庫)復制到另一個或多個MySQL數據庫(slave從庫)。缺省情況下,復制是異步的,slave無需保持持久的連接來從master獲得更新。這意味著更新能工作在遠程連接,甚至是臨時間斷性的連接上,比如撥號連接服務。根據不同的配置,你能復制master上所有的數據庫,或指定的數據庫,甚至某一數據庫中指定的數據表。
下面是關於復制功能,新手經常問到的問題。
1. slave必須要持久連接到master嗎?
不需要。slave可以關機或失去連接幾小時甚至幾天,然後重新連接獲取更新。舉例來說,你能在撥號連接網絡上建立復制,而該撥號網絡只有不定時或短時間的連接。這也意味著,在任何給定時間點,slave不能保證和master保持完全一致,除非你采取某些特別的措施。
為了保證能獲取在slave失去連接時的更新,你不能從master上移除包含未完成復制內容的binary二進制日志文件。異步復制能維持工作的條件:slave能從最後一次讀取事件的點繼續讀取binary二進制日志。
2. 復制必須要在master和slave上開啟網絡功能嗎?
是的,必須要在master和slave上開啟網絡功能。如果網絡沒有連接,slave就無法連接到master傳輸binary二進制日志。在每個服務器上檢查配置文件,skip-networking選項沒有被開啟。
3. 如何知道slave比master落後更新了多久?或者說,如何知道slave最後一次更新的日期?
檢查 SHOW SLAVE STATUS 輸出中的 Seconds_Behind_Master 列。 當slave的SQL線程執行一個從master的讀事件,它修改自己的時間為該事件的時間點Timestamp。(這就是為什麼TIMESTAMP可以被很好的復制。)在 SHOW PROCESSLIST 輸出中的 Time 列,顯示的是slave的SQL線程最後一次復制事件中的時間點timestamp和slave服務器的真實時間之間的秒數差。(這一句翻譯得好辛苦。) 你能利用這個數值來確定上次復制事件的日期。如果你的slave已經和master斷開連接1小時,然後重新連接,你可以在 SHOW PROCESSLIST 輸出中的 Time 列立刻看到大的時間數值,如3600。這是因為slave正在執行超過1小時前的語句。
4. 如何強制master阻止更新,直到slave能跟上來?
在master上執行:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> SHOW MASTER STATUS;
記錄下SHOW語句輸出中的復制代理的值。(當前的binary二進制日志文件的文件名和位置)
在slave執行:(參數使用上一步獲得的值)
mysql> SELECT MASTER_POS_WAIT('log_name', log_pos);
這個SELECT語句會保持運行,直到slave根據指定的日志文件和位置完成和master的同步,然後該SELECT語句返回。
在master執行:(解除更新限制)
mysql> UNLOCK TABLES;
5. 設置雙向復制,我需要了解什麼問題?
MySQL復制當前不支持master和slave之間的任何鎖定協議來保證跨服務器分發更新的原子性。(原子性:作為事務一部分的所有步驟或者都發生,或者都不發生。) 舉例來說,客戶端A在master1上作了一個更新,與此同時,在這個更新傳播到master2前,客戶端B在master2上也作了一個與客戶端A不同的更新,因此,當客戶端A的更新到達master2,它要處理的表數據將不同於在master1上的,master2上的更新傳播到master1上,也會面臨同樣的問題。這意味著,除非你確定你的更新與次序無關,或者在客戶端代碼中采取某些方法處理無序的更新,否則你不能把兩個服務器連在一起做成雙向復制。
你還應該知道雙向復制實際上不能改善更多的性能,每一個服務器都需要作同樣數量的更新,就像你只有一個服務器時一樣。唯一的區別是可以減少一點鎖競爭,原因是來自另一個服務器的更新在slave是順序進行的。即使如此,這點好處還可能會被網絡延遲所抵消。
6. 如何利用復制改善系統的性能?
設置一個服務器作為master,所有的寫操作都在它上面完成。然後在預算和機架容量范圍內設置盡可能多的slave服務器,把讀操作分攤在master和slave服務器上。你還可以以下述參數啟動slave,在slave端獲得速度上的提升。slave使用非事務性的MyISAM表取代InnoDB表,消除事務的開銷來獲得更高的速度。
--skip-innodb
--low-priority-updates
--delay-key-write=ALL
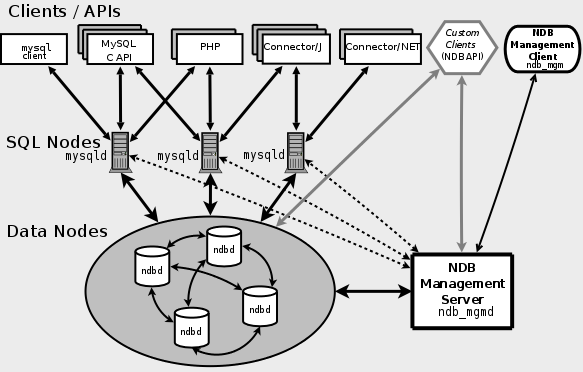
7. 如何在我的應用內編寫客戶端代碼使用性能增強的復制?
參考“利用復制橫向擴展”,下面這張圖不錯。
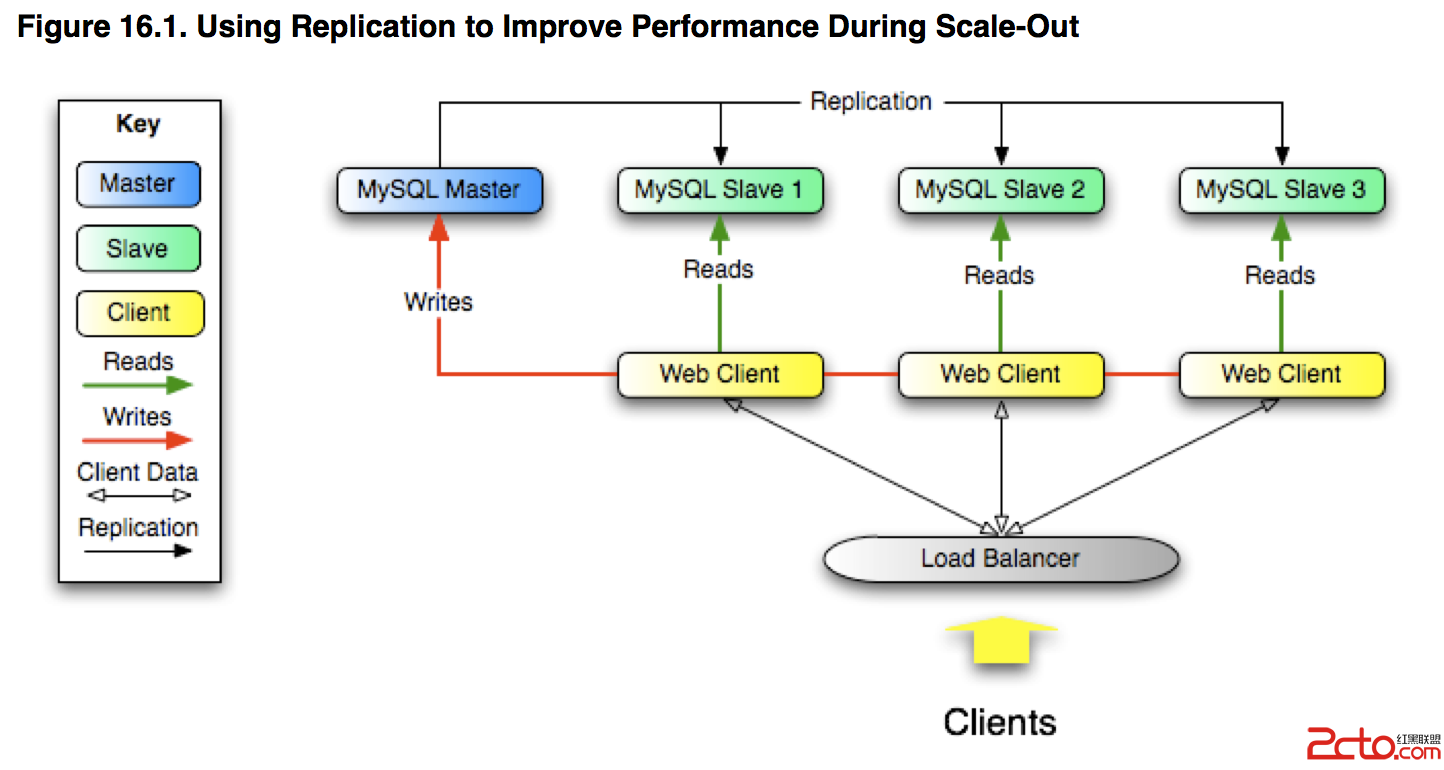
8. MySQL復制在什麼時候,多大程度上能改善我的系統的性能?
MySQL復制能在這樣的系統中發揮最大的效能:頻繁的讀操作,不頻繁的寫操作。從原理上說,使用單master和多slave方案,你能通過增加slave來擴展系統直到超出網絡的帶寬,或者你的master不能承受更新的負載增長。
為了確定你在獲得的好處能穩定下來前要使用多少slave,確定你的站點能獲得多少性能改善,你必須清楚你的查詢模式,然後憑經驗測定典型master和slave上讀和寫的總量。(後面一大段舉例的內容就不翻譯了,偷懶 ... ^_^)
9. 如何利用復制提供冗余或高可用?
如何實現冗余完全取決於你的應用和應用環境設置。高可用方案(故障轉移)要求主動的監控,使用自定義的腳本或第三方的工具為MySQL提供故障時轉移到slave的支持。
手動處理這一過程,你應該能從一個故障的master切換到一個預先配制好的slave,修改DNS設置,使你的應用連接新的服務器。
10. 如何設置master使用基於語句 statement-based 還是使用基於數據行 row-based 的二進制binary日志格式?
檢查 binlog_format 系統變量:
mysql> SHOW VARIABLES LIKE 'binlog_format';
顯示的值可能是 STATEMENT, ROW, MIXED 中之一。MIXED模式使用基於行row-based的復制,但是會在特定條件下自動切換到基於語句statement-based的日志。
11. 如何設置slave使用基於行row-based的復制?
slave會自動獲知應該使用哪種格式。
12. 如何避免 GRANT 和 REVOKE 語句被復制到slave服務器?
啟動服務器使用 --replicate-wild-ignore-table=mysql.% 選項 忽略復制mysql數據庫中的數據表。
13. 復制可以工作在跨平台嗎?(如master運行在Linux,而slaves運行在Mac或Windows)
是的!(這一點我喜歡)
14. 復制可以工作在不同的硬件架構上嗎?(如master運行在64為平台,而slaves運行在32位平台)
是的!(這一點我就更喜歡了)