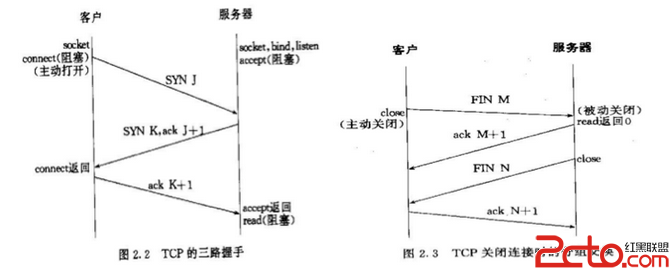
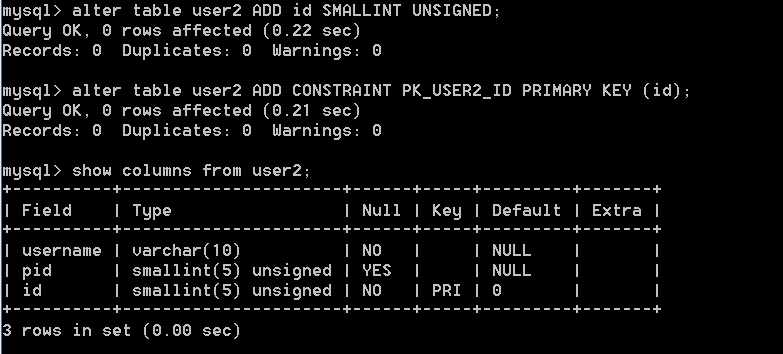
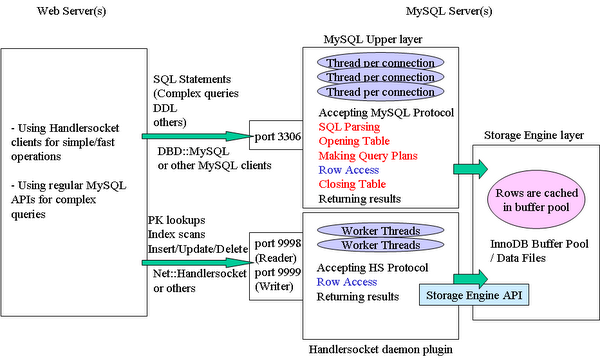
Mysql中排序在SQL優化中的部分解析 在mysql中,相關的復制的sql語句,會對所要搜取得結果進行規整,這裡就有排序,分組,統計等相關整理過程,其中排序的算法的意義最為重要,在mysql不同的版本中,特別是在5.1系列以後對排序算法的定義不斷加強改善; 在排序算法中對新舊算法當中提到的陣列的寬度,以及函數搜取的范圍,大小,影響的高度等都進行了修改,並設置相關的閥值,以指導相關的參數自動閉合;以下是在5.5系列中相關的sort文件截取; [html] #define UT_SORT_FUNCTION_BODY(SORT_FUN, ARR, AUX_ARR, LOW, HIGH, CMP_FUN)\ {\ ulint ut_sort_mid77;\ ulint ut_sort_i77;\ ulint ut_sort_low77;\ ulint ut_sort_high77;\ \ ut_ad((LOW) < (HIGH));\ ut_ad(ARR);\ ut_ad(AUX_ARR);\ \ if ((LOW) == (HIGH) - 1) {\ return;\ } else if ((LOW) == (HIGH) - 2) {\ if (CMP_FUN((ARR)[LOW], (ARR)[(HIGH) - 1]) > 0) {\ (AUX_ARR)[LOW] = (ARR)[LOW];\ (ARR)[LOW] = (ARR)[(HIGH) - 1];\ (ARR)[(HIGH) - 1] = (AUX_ARR)[LOW];\ }\ return;\ }\ \ ut_sort_mid77 = ((LOW) + (HIGH)) / 2;\ \ SORT_FUN((ARR), (AUX_ARR), (LOW), ut_sort_mid77);\ SORT_FUN((ARR), (AUX_ARR), ut_sort_mid77, (HIGH));\ \ ut_sort_low77 = (LOW);\ ut_sort_high77 = ut_sort_mid77;\ \ for (ut_sort_i77 = (LOW); ut_sort_i77 < (HIGH); ut_sort_i77++) {\ \ if (ut_sort_low77 >= ut_sort_mid77) {\ (AUX_ARR)[ut_sort_i77] = (ARR)[ut_sort_high77];\ ut_sort_high77++;\ } else if (ut_sort_high77 >= (HIGH)) {\ (AUX_ARR)[ut_sort_i77] = (ARR)[ut_sort_low77];\ ut_sort_low77++;\ } else if (CMP_FUN((ARR)[ut_sort_low77],\ (ARR)[ut_sort_high77]) > 0) {\ (AUX_ARR)[ut_sort_i77] = (ARR)[ut_sort_high77];\ ut_sort_high77++;\ } else {\ (AUX_ARR)[ut_sort_i77] = (ARR)[ut_sort_low77];\ ut_sort_low77++;\ }\ }\ \ memcpy((void*) ((ARR) + (LOW)), (AUX_ARR) + (LOW),\ ((HIGH) - (LOW)) * sizeof *(ARR));\ }\ 參數max_length_for_sort_data; 在MySQL中,決定使用第一種老式的排序算法還是新的改進算法的依據是通過參數max_length_for_sort_data來決定的。當我們所有返回字段的最大長度小於這個參數值的時候,MySQL就會選擇改進後的排序算法,反之,則選擇老式的算法。所以,如果我們有充足的內存讓MySQL存放需要返回的非排序字段的時候,可以加大這個參數的值來讓MySQL選擇使用改進版的排序算法。 參數sort_buffer_size; 增大sort_buffer_size並不是為了讓MySQL可以選擇改進版的排序算法,而是為了讓MySQL可以盡量減少在排序過程中對需要排序的數據進行分段,因為這樣會造成MySQL不得不使用臨時表來進行交換排序。 還有就是對相關的字段進行規避;選擇返回需要的即可.