MySQL優化器中一個Count和覆蓋索引的問題
 現象說明
其實這裡主要要說明的是一個優化器還需要改進的地方。
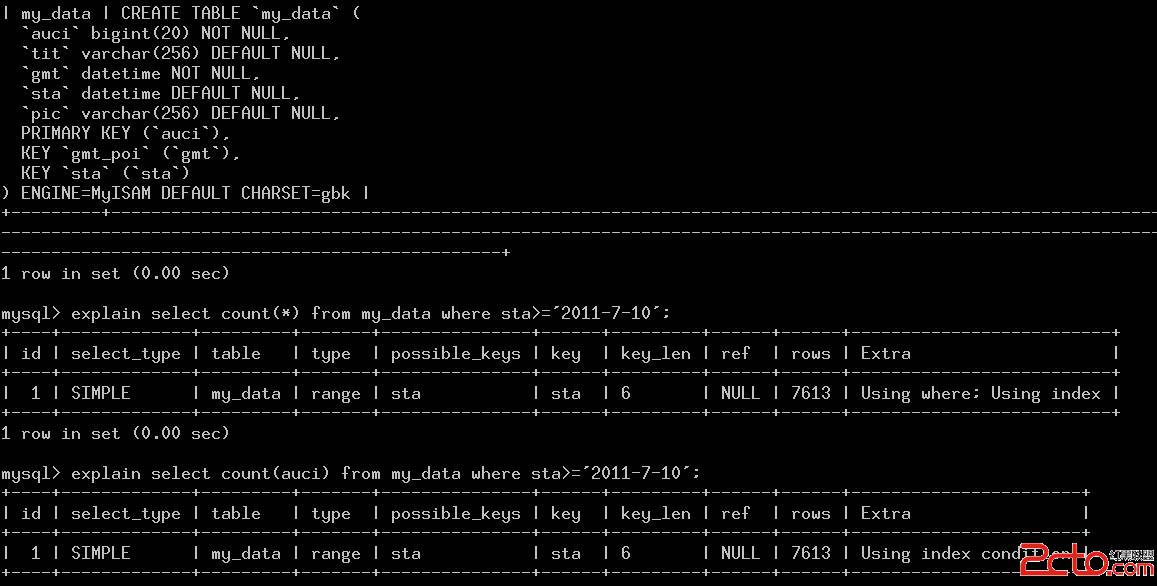
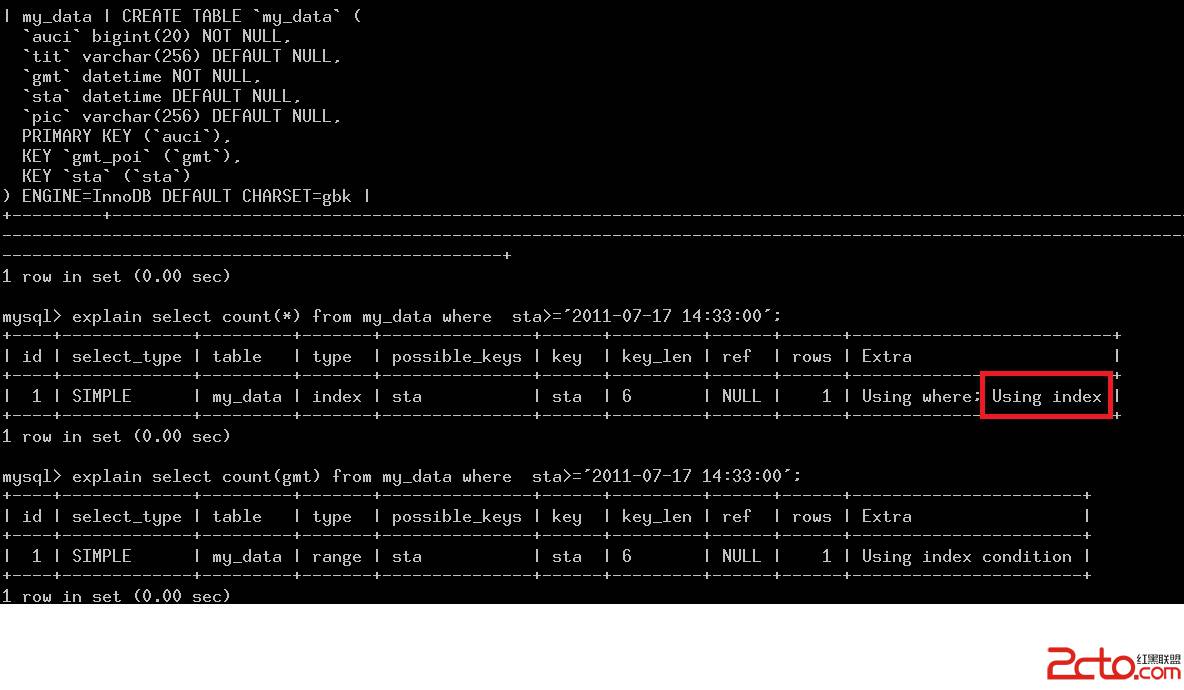
優化器會根據where條件和select_list裡面的字段決定在使用一個索引(sta)後,是否需要回表—回到聚集索引取數據。
基本的做法是:在確定了一個索引後,將select_list和where中出現的所有字段都拿來判斷一下,如果字段都存在於sta索引中,則可以使用覆蓋索引。
第一個explan可以用上覆蓋索引(Using Index), 是因為select_list裡面只有count(*),而count(*)在語法解析階段就被特殊處理,不作為特殊字段。
第二個字段在現在的實現中,因為gmt不是sta索引的一部分(sta索引定義上只有sta一個字段,算上聚集索引結構,就是sta,auci)。所以最後判定為不能使用覆蓋索引。
性能差別
表中放入500w數據以後,這兩個查詢的時間相差25倍(0.19s vs 5s)。
存在改進
其實我說這個“不科學”,是因為第二個語句居然不能使用覆蓋索引。按照count(gmt)的語義,是計算gmt不為NULL的所有行的數目。但是表定義中,分分明已經說明了gmt為not null。那麼就可以轉成count(*)了!
目前因為count、sum、count(distinct)這些操作的處理方法被揉在一起,因此沒有特別分開。
應用警惕
好在按照正常的習慣,需要計算總數時,最多是count(auci)或者count(*), 不會故意去count一個別的字段。當時若使用的是MyISAM,就需要小心了。
從上面的分析可以推測得到,如果這是個MyISAM表,還是一樣的where條件,count(*)是可以使用覆蓋索引的,但是count(auci)就不行了。
現象說明
其實這裡主要要說明的是一個優化器還需要改進的地方。
優化器會根據where條件和select_list裡面的字段決定在使用一個索引(sta)後,是否需要回表—回到聚集索引取數據。
基本的做法是:在確定了一個索引後,將select_list和where中出現的所有字段都拿來判斷一下,如果字段都存在於sta索引中,則可以使用覆蓋索引。
第一個explan可以用上覆蓋索引(Using Index), 是因為select_list裡面只有count(*),而count(*)在語法解析階段就被特殊處理,不作為特殊字段。
第二個字段在現在的實現中,因為gmt不是sta索引的一部分(sta索引定義上只有sta一個字段,算上聚集索引結構,就是sta,auci)。所以最後判定為不能使用覆蓋索引。
性能差別
表中放入500w數據以後,這兩個查詢的時間相差25倍(0.19s vs 5s)。
存在改進
其實我說這個“不科學”,是因為第二個語句居然不能使用覆蓋索引。按照count(gmt)的語義,是計算gmt不為NULL的所有行的數目。但是表定義中,分分明已經說明了gmt為not null。那麼就可以轉成count(*)了!
目前因為count、sum、count(distinct)這些操作的處理方法被揉在一起,因此沒有特別分開。
應用警惕
好在按照正常的習慣,需要計算總數時,最多是count(auci)或者count(*), 不會故意去count一個別的字段。當時若使用的是MyISAM,就需要小心了。
從上面的分析可以推測得到,如果這是個MyISAM表,還是一樣的where條件,count(*)是可以使用覆蓋索引的,但是count(auci)就不行了。