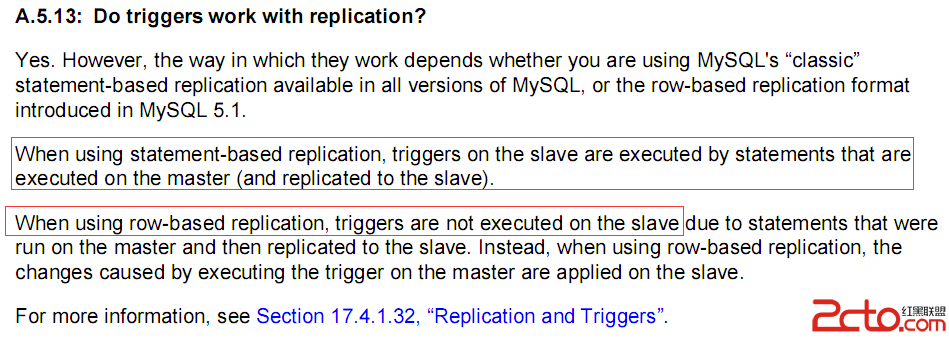
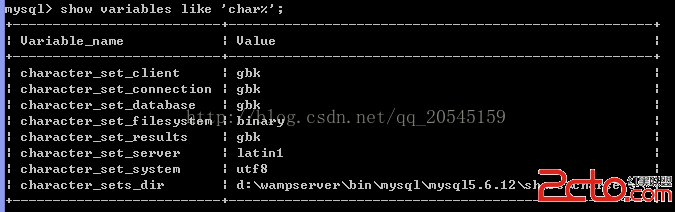
mysql中數據去重和優化 更改表user_info的主鍵uid為自增的id後,忘了設置原來主鍵uid屬性為unique,結果導致產生uid重復的記錄。為此需要清理後來插入的重復記錄。 基本方法可以參考後面的附上的資料,但是由於mysql不支持同時對一個表進行操作,即子查詢和要進行的操作不能是同一個表,因此需要通過零時表中轉一下。 寫在前面:數據量大時,一定要多涉及的關鍵字段創建索引!!!否則很慢很慢很慢,慢到想死的心都有了 1 單字段重復 生成零時表,其中uid是需要去重的字段 create table tmpuid as (select uid from userinfo group by uid having count(uid)) create table tmpid as (select min(id) from userinfo group by uid having count(uid)) 數據量大時一定要為uid創建索引 create index indexuid on tmpuid create index indexid on tmpid 刪除多余的重復記錄,保留重復項中id最小的 delete from user_info where id not in (select id from tmp_id) and uid in (select uid from tmp_uid) 2.多字段重復 由uid的重復間接的導致了relationship中的記錄重復,故繼續去重。先介紹正常處理流程,在介紹本人根據自身數據特點實踐的更加有效的方法! 2.1一般方法 基本的同上面: 生成零時表 create table tmp_relation as (select source,target from relationship group by source,target having count(*)>1) create table tmprelationshipid as (select min(id) as id from relationship group by source,target having count(*)>1) 創建索引 create index indexid on tmprelationship_id 刪除 delete from relationship where id not in (select id from tmprelationshipid) and (source,target) in (select source,target from relationship) 2.2 實踐出真知 實踐中發現上面的刪除字段重復的方法,由於沒有辦法為多字段重建索引,導致數據量大時效率極低,低到無法忍受。最後,受不了等了半天沒反應的狀況,本人決定,另辟蹊徑。 考慮到,估計同一記錄的重復次數比較低。一般為2,或3,重復次數比較集中。所以可以嘗試直接刪除重復項中最大的,直到刪除到不重復,這時其id自然也是當時重復的裡邊最小的。 大致流程如下: 1)選擇每個重復項中id最大的一個記錄 create table tmprelationid2 as (select max(id) from relationship group by source,target having count(*)>1) 2)創建索引(僅需在第一次時執行) create index indexid on tmprelation_id2 3)刪除 重復項中id最大的記錄 delete from relationship where id in (select id from tmprelationid2) 4)刪除臨時表 drop table tmprelationid2 重復上述步驟1),2),3),4),直到創建的臨時表中不存在記錄就結束(對於重復次數的數據,比較高效) 查詢及刪除重復記錄的方法 (一) 1、查找表中多余的重復記錄,重復記錄是根據單個字段(peopleId)來判斷 select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) 2、刪除表中多余的重復記錄,重復記錄是根據單個字段(peopleId)來判斷,只留有rowid最小的記錄 delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId) > 1) and rowid not in (select min(rowid) from people group by peopleId having count(peopleId )>1) 3、查找表中多余的重復記錄(多個字段) select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) 4、刪除表中多余的重復記錄(多個字段),只留有rowid最小的記錄 delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count() > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count()>1)