MySql無限分類結構
無限分類是我們開發中非常常見的應用,像論壇的的版塊,CMS的類別,應用的地方特別多。
我們最常見最簡單的方法就是在MySql裡ID ,parentID,name:
優點是簡單,結構簡單。
缺點是效率不高,因為每一次遞歸都要查詢數據庫,幾百條數據庫時就不是很快了!
存儲樹是一種常見的問題,多種解決方案。主要有兩種方法:鄰接表的模型,並修改樹前序遍歷算法。
我們將探討這兩種方法的節能等級的數據。我會使用樹從一個虛構的網上食品商店作為一個例子。這食品商店組織其食品類,通過顏色和類型。這棵樹看起來像這樣:
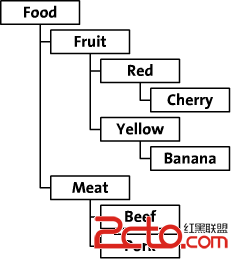
下面我們將用另外一種方法,這就是預排序遍歷樹算法(modified preorder tree traversal algorithm) 。
這種方法大家可能接觸的比較少,初次使用也不像上面的方法容易理解,但是由於這種方法不使用遞歸查詢算法,有更高的查詢效率。
我們首先將多級數據按照下面的方式畫在紙上,在根節點Food的左側寫上 1 然後沿著這個樹繼續向下 在 Fruit 的左側寫上 2 然後繼續前進, 沿著整個樹的邊緣給每一個節點都標上左側和右側的數字。最後一個數字是標在Food 右側的 18。 在下面的這張圖中你可以看到整個標好了數字的多級結 構。(沒有看懂?用你的手指指著數字從1數到18就明白怎麼回事了。還不明白,再數一遍,注意移動你的手指)。
這些數字標明了各個節點之間的關系,”Red”的號是3和6,它是 ”Food” 1-18 的子孫節點。 同樣,我們可以看到 所有左值大於2和右值小於11的節點 都是”Fruit” 2-11 的子孫節點
如圖所示:
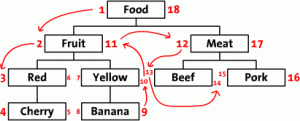
這樣整個樹狀結構可以通過左右值來存儲到數據庫中。繼續之前,我們看一看下面整理過的數據表。
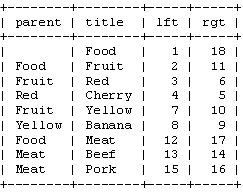
注意:由於”left”和”right”在 SQL中有特殊的意義,所以我們需要用”lft”和”rgt”來表示左右字段。 另外這種結構中不再需要”parent”字段來表示樹狀結構。也就是 說下面這樣的表結構就足夠了。
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
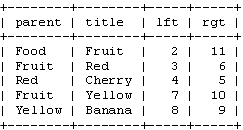
看到了吧,只要一個查詢就可以得到所有這些節點。為了能夠像上面的遞歸函數那樣顯示整個樹狀結構,我們還需要對這樣的查詢進行排序。用節點的左值進行排序:
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
那麼某個節點到底有多少子孫節點呢?很簡單,子孫總數=(右值-左值-1)/2
descendants = (right – left - 1) / 2 ,如果不是很清楚這個公式,那就去翻下書,我們在上數據結構寫的很清楚!
添加同一層次的節點的方法如下:
LOCK TABLE nested_category WRITE;
SELECT @myRight := rgt FROM nested_category
WHERE name = ‘Cherry’;
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myRight;
INSERT INTO nested_category(name, lft, rgt) VALUES(‘Strawberry’, @myRight + 1, @myRight + 2);
UNLOCK TABLES;
添加樹的子節點的方法如下:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft FROM nested_category
WHERE name = ‘Beef’;
UPDATE nested_category SET rgt = rgt + 2 WHERE rgt > @myLeft ;
UPDATE nested_category SET lft = lft + 2 WHERE lft > @myLeft ;
INSERT INTO nested_category(name, lft, rgt) VALUES(‘charqui’, @myLeft + 1, @myLeft + 2);
UNLOCK TABLES;
每次插入節點之後都可以用以下SQL進行查看驗證:
SELECT CONCAT( REPEAT( ‘ ‘, (COUNT(parent.name) – 1) ), node.name) AS name
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;
刪除節點的方法,稍微有點麻煩是有個中間變量,如下:
LOCK TABLE nested_category WRITE;
SELECT @myLeft := lft, @myRight := rgt, @myWidth := rgt – lft + 1
FROM nested_category
WHERE name = ‘Cherry’;
DELETE FROM nested_category WHERE lft BETWEEN @myLeft AND @myRight;
UPDATE nested_category SET rgt = rgt – @myWidth WHERE rgt > @myRight;
UPDATE nested_category SET lft = lft – @myWidth WHERE lft > @myRight;
UNLOCK TABLES;
這種方式就是有點難的理解,但是適合數據量很大規模使用,查看所有的結構只需要兩條SQL語句就可以了,在添加節點和刪除節點的時候略顯麻煩,不過相對於 效率來說還是值得的,這次發現讓我發現了數據庫結構真的很有用,但是我在學校學的樹基本上都忘記了,這次遇到這個問題才應用到項目中!