數據庫索引操作
以前沒用過索引,沒能體會索引的好處,前陣子要處理幾百萬條記錄的表,比如說兩邊查詢,記錄多了,查詢的速度那是相當的慢,所以就試著用了索引,發現速度提升那可不是一點點,而是很多很多點。
具體操作如下:
一、首先創建兩張表,如下圖所示:
 建表語句如下
建表語句如下
[sql] CREATE TABLE `t1` ( `ID` bigint(20) NOT NULL AUTO_INCREMENT, `Num` int(11) NOT NULL, PRIMARY KEY (`ID`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
表二和表一類似創建 二、往兩表中填充數據,用存儲過程實現,步驟如下:
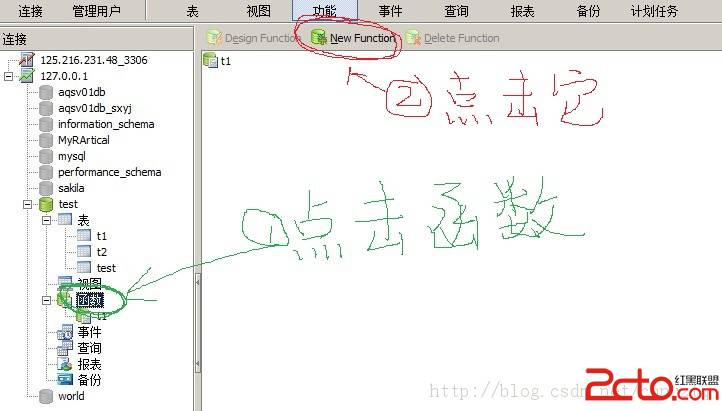
 以上是用navicat創建存儲過程的界面,創建兩個存儲過程,分別網t1、t2中填充數據,代碼分別如下:
填充t1的存儲過程
以上是用navicat創建存儲過程的界面,創建兩個存儲過程,分別網t1、t2中填充數據,代碼分別如下:
填充t1的存儲過程
[sql]
BEGIN
#Routine body goes here...
declare n int;
set n = 1;
while n <= 50000
do
insert into t1(Num) values(n);
set n = n + 1;
end while;
END
填充t2的存儲過程
[sql]
BEGIN
#Routine body goes here...
declare n int;
set n = 1;
while n <= 25000
do
insert into t2(Num) values(n);
set n = n + 1;
end while;
set n = 1;
while n <= 25000
do
insert into t2(Num) values(0);
set n = n + 1;
end while;
END
三、進行聯表查詢 求兩表中,Num字段相同的行數,查詢語句如下:
[sql] select count(*) from t1,t2 where t1.Num = t1.Num;
t1的每一行都要和t2的每一行進行比較,也就是說t2要被從頭到尾掃描50000次,如果數據再大點,再有耐心的人都等不下去了,所以必須想想辦法,這裡就可以用到索引了。創建索引的好處我在這裡就不說了,只說一下如何用索引。 其實很簡單,其他都不用變,只需在查詢之前多做兩件事: 第一、為t1創建索引; 第二、為t2創建索引; 創建索引的語句是:
[sql] create index Num_i1 on t1(Num); create index Num_i2 on t2(Num);然後在執行一樣的查詢語句,沒加索引在我電腦上跑要幾分鐘,加了索引之後,一眨眼的功夫就出結果了。 所以如果當數據量大的時候,一定記得用索引,如果有多個過濾條件,也可以對多個列進行索引。比如
create index Num_i1 on t1(ID,Num);