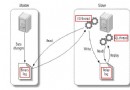
略懂MySQL字符集 本文雖說旨在明白、但若略懂亦可、畢竟諸葛孔明如是 只有基於字符的值才有所謂字符集的概念 某些字符集可能需要更多CPU、消費更多的內存和磁盤空間、甚至影響索引使用 這還不包括令人蛋碎的亂碼、 可見、我們還是有必要花點時間略懂下MySQL字符集 先直觀認識各階梯下顯示使用字符集:
[sql]
# 囊括三個層級:DB、Table、Column
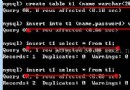
mysql> create database d charset utf8;
Query OK, 1 row affected (0.04 sec)
mysql> create table d.t
-> (str varchar(10) charset latin1)
-> default charset=utf8;
Query OK, 0 rows affected (0.05 sec)
那如果沒有顯示指定?MySQL是如何設置?路分兩條: ① 創建對象時的默認設置 這是個逐層繼承的默認設置: Server → DB → Table → Column 高層為底層設置默認值、底層可遵可棄、 沒有指定字符集、謂之可遵 顯示指定字符集、謂之可棄 ② 服務器和客戶端通信時的設置 當客戶端提交一條SQL到MySQL時、MySQL Server總是假定客戶端字符集是character_set_client 其後、Server把character_set_client轉為character_set_connection進行SQL處理、 在返回結果集給客戶端時、Server又將character_set_connection轉為character_set_result、然後返回 以上涉及的三個字符集、我們可以通過set names 一次搞定 字符集之間的相互轉換是需要額外的系統開銷的、 如何知道? explain extended + show warnings 即可 那該如何盡量避免這種隱式轉換? 這裡介紹一種被稱為"極簡原則"的方法、如下: 先為服務器(或數據庫)選擇合適的字符集、然後依據業務、讓某些列選擇合適的字符集 在MySQL字符集中隱含了些意外驚喜、主要有三: ① 有趣的character_set_database 當character_set_database和character_set_server不同時、庫的默認字符集由後者決定 你不能直接修改csd、改變css就改變了csd、因為csd和庫默認字符集相同、 改變庫默認字符集、csd就隨之改變、而css決定庫的默認字符集 所以、當連接到mysql實例、又沒有指定庫時、默認字符集與css相同 ② load data infile 進行此操作時、建議最佳實踐如下: use 庫; set names 字符集; 開始加載數據; 這就使用統一字符集、避免混搭的"字符集style" ③ select into outfile 該行為沒有進行任何轉碼操作! 有人說、不管37二十一、全用utf8、整個世界都清淨了 但這不僅消耗更多磁盤空間、也帶來一定性能犧牲 為什麼?因為utf8是多字節字符集、比如一個漢字是三個字節 這會帶來兩方面的問題: ① 浪費空間、如char(10)可能會開辟30字節空間、即使不需要 ② 索引長度限制、mysql總是假定一個字符三個字節、導致最長索引長度變成1/3 行文至此、大意已明、後續想到、再續前緣