explain詳細說明
通過explain可以知道mysql是如何處理語句,分析出查詢或是表結構的性能瓶頸。通過expalin可以得到:
1. 表的讀取順序
2.表的讀取操作的操作類型
3.哪些索引可以使用
4. 哪些索引被實際使用
5.表之間的引用
6.每張表有多少行被優化器查詢
explain顯示字段
 1. id :語句的執行順序標識
2. select_type:使用的查詢類型,主要有以下幾種查詢類型:
1).simple 簡單類型
語句中沒有子查詢或union
1. id :語句的執行順序標識
2. select_type:使用的查詢類型,主要有以下幾種查詢類型:
1).simple 簡單類型
語句中沒有子查詢或union
 2). primary 最外層的select ,不是主鍵
2). primary 最外層的select ,不是主鍵
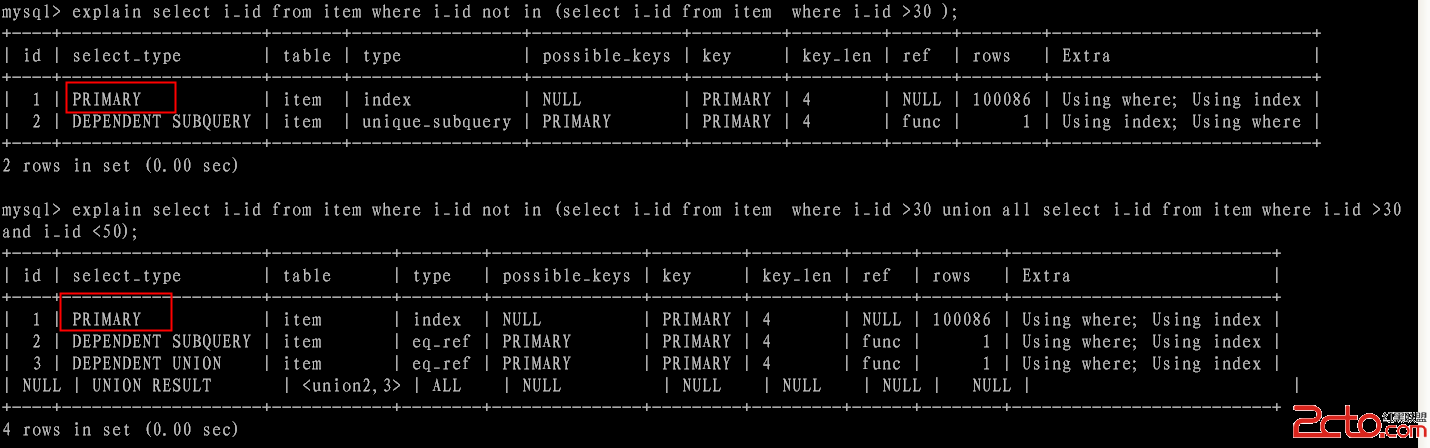 3). union
union是在select 語句中第二個select語句後面所有的select,第一個select 為primary
4).dependent subquery
子查詢中內層中第一個select語句
3). union
union是在select 語句中第二個select語句後面所有的select,第一個select 為primary
4).dependent subquery
子查詢中內層中第一個select語句
 5). dependent union
子查詢中union且為union中第二個select開始的後面所有select,依賴於外部的結果集。
5). dependent union
子查詢中union且為union中第二個select開始的後面所有select,依賴於外部的結果集。
 6). SUBQUERY
6). SUBQUERY
 7).devived
派生表的查詢語句
7).devived
派生表的查詢語句
 8). uncacheable subquery
結果集無法緩存的子查詢
9). union result
union中合並的結果
8). uncacheable subquery
結果集無法緩存的子查詢
9). union result
union中合並的結果
 3. table
顯示這一步所訪問的數據庫中表的名稱
4. type
這列很重要,顯示了連接使用了哪種類別,有無使用索引。type代表查詢執行計劃(QEP)中指定的表使用的連接方式。從最好到最差的連接類型為 1.system、2.const、3. eq_reg、4. ref、5. range、6.index、7. all
1). system
system為const一個特例,即表中只有一條記錄。
2). const
const是在where條件以常量作為查詢條件,表中最多有一條記錄匹配。由於是常量,所以實際上只需要讀一次。
3. table
顯示這一步所訪問的數據庫中表的名稱
4. type
這列很重要,顯示了連接使用了哪種類別,有無使用索引。type代表查詢執行計劃(QEP)中指定的表使用的連接方式。從最好到最差的連接類型為 1.system、2.const、3. eq_reg、4. ref、5. range、6.index、7. all
1). system
system為const一個特例,即表中只有一條記錄。
2). const
const是在where條件以常量作為查詢條件,表中最多有一條記錄匹配。由於是常量,所以實際上只需要讀一次。
 3). eq_reg
最多只會有一條匹配結果,一般是通過主鍵或是唯一索引來訪問。一般會出現在連接查詢的語句中。
3). eq_reg
最多只會有一條匹配結果,一般是通過主鍵或是唯一索引來訪問。一般會出現在連接查詢的語句中。
 4). ref
join 語句中被驅動的表索引引用查詢。這個值表示所有具有匹配的索引值的行都被用到。
5).range
索引范圍掃描
6). index
全索引樹被掃描
7). all
全表掃描,效果是最不理想的。
5. possible_keys
查詢可以利用的索引,如果沒有任何索引可以使用,就會顯示成null,這項對內容的優化時索引的調整非常重要。
6.key
從possible_keys中所選擇使用的索引
7. key_len
key_len列顯示mysql決定使用的鍵長度,如果鍵是null,則長度為null。使用的索引長度,一般越短越好。
8. ref
列出的是通過常量const,或是某個表的某個字段來過濾的。
9.rows
通過系統收集到的統計信息,估計出來的結果集記錄條數
10. extra
Extra:查詢中每一步實現的額外細節信息,主要可能會是以下內容:
1). Distinct:查找distinct值,所以當mysql找到了第一條匹配的結果後,將停止該值的查詢而轉為後面其他值的查詢; FullscanonNULLkey:子查
詢中的一種優化方式,主要在遇到無法通過索引訪問null值的使用使用;
2). ImpossibleWHEREnoticedafterreadingconsttables:MySQLQueryOptimizer通過收集到的統計信息判斷出不可能存在結果;
3). Notables:Query語句中使用FROMDUAL或者不包含任何FROM子句;
4). Notexists:在某些左連接中MySQLQueryOptimizer所通過改變原有Query的組成而使用的優化方法,可以部分減少數據訪問次數;
5). Rangecheckedforeachrecord(indexmap:N):通過MySQL官方手冊的描述,當MySQLQueryOptimizer沒有發現好的可以使用的索引的時候,如果
發現如果來自前面的表的列值已知,可能部分索引可以使用。對前面的表的每個行組合,MySQL檢查是否可以使用range或index_merge訪問方法來索取
行。
6). Selecttablesoptimized away:當我們使用某些聚合函數來訪問存在索引的某個字段的時候,MySQLQueryOptimizer會通過索引而直接一次定位到
所需的數據行完成整個查詢。當然,前提是在Query中不能有GROUPBY操作。如使用MIN()或者MAX()的時候;
7). Usingfilesort:當我們的Query中包含ORDERBY操作,而且無法利用索引完成排序操作的時候,MySQLQueryOptimizer不得不選擇相應的排序算法
來實現。
8). Usingindex:所需要的數據只需要在Index即可全部獲得而不需要再到表中取數據;
9). Usingindexforgroup-by:數據訪問和Usingindex一樣,所需數據只需要讀取索引即可,而當Query中使用了GROUPBY或者DISTINCT子句的時候,
如果分組字段也在索引中,Extra中的信息就會是Usingindexforgroup-by;
10). Usingtemporary:當MySQL在某些操作中必須使用臨時表的時候,在Extra信息中就會出現Usingtemporary。主要常見於GROUPBY和ORDERBY等
操作中。
11). Usingwhere:如果我們不是讀取表的所有數據,或者不是僅僅通過索引就可以獲取所有需要的數據,則會出現Usingwhere信息;
12). Usingwherewithpushedcondition:這是一個僅僅在NDBCluster存儲引擎中才會出現的信息,而且還需要通過打開ConditionPushdown優化功能
才可能會被使用。控制參數為engine_condition_pushdown。
附:
4). ref
join 語句中被驅動的表索引引用查詢。這個值表示所有具有匹配的索引值的行都被用到。
5).range
索引范圍掃描
6). index
全索引樹被掃描
7). all
全表掃描,效果是最不理想的。
5. possible_keys
查詢可以利用的索引,如果沒有任何索引可以使用,就會顯示成null,這項對內容的優化時索引的調整非常重要。
6.key
從possible_keys中所選擇使用的索引
7. key_len
key_len列顯示mysql決定使用的鍵長度,如果鍵是null,則長度為null。使用的索引長度,一般越短越好。
8. ref
列出的是通過常量const,或是某個表的某個字段來過濾的。
9.rows
通過系統收集到的統計信息,估計出來的結果集記錄條數
10. extra
Extra:查詢中每一步實現的額外細節信息,主要可能會是以下內容:
1). Distinct:查找distinct值,所以當mysql找到了第一條匹配的結果後,將停止該值的查詢而轉為後面其他值的查詢; FullscanonNULLkey:子查
詢中的一種優化方式,主要在遇到無法通過索引訪問null值的使用使用;
2). ImpossibleWHEREnoticedafterreadingconsttables:MySQLQueryOptimizer通過收集到的統計信息判斷出不可能存在結果;
3). Notables:Query語句中使用FROMDUAL或者不包含任何FROM子句;
4). Notexists:在某些左連接中MySQLQueryOptimizer所通過改變原有Query的組成而使用的優化方法,可以部分減少數據訪問次數;
5). Rangecheckedforeachrecord(indexmap:N):通過MySQL官方手冊的描述,當MySQLQueryOptimizer沒有發現好的可以使用的索引的時候,如果
發現如果來自前面的表的列值已知,可能部分索引可以使用。對前面的表的每個行組合,MySQL檢查是否可以使用range或index_merge訪問方法來索取
行。
6). Selecttablesoptimized away:當我們使用某些聚合函數來訪問存在索引的某個字段的時候,MySQLQueryOptimizer會通過索引而直接一次定位到
所需的數據行完成整個查詢。當然,前提是在Query中不能有GROUPBY操作。如使用MIN()或者MAX()的時候;
7). Usingfilesort:當我們的Query中包含ORDERBY操作,而且無法利用索引完成排序操作的時候,MySQLQueryOptimizer不得不選擇相應的排序算法
來實現。
8). Usingindex:所需要的數據只需要在Index即可全部獲得而不需要再到表中取數據;
9). Usingindexforgroup-by:數據訪問和Usingindex一樣,所需數據只需要讀取索引即可,而當Query中使用了GROUPBY或者DISTINCT子句的時候,
如果分組字段也在索引中,Extra中的信息就會是Usingindexforgroup-by;
10). Usingtemporary:當MySQL在某些操作中必須使用臨時表的時候,在Extra信息中就會出現Usingtemporary。主要常見於GROUPBY和ORDERBY等
操作中。
11). Usingwhere:如果我們不是讀取表的所有數據,或者不是僅僅通過索引就可以獲取所有需要的數據,則會出現Usingwhere信息;
12). Usingwherewithpushedcondition:這是一個僅僅在NDBCluster存儲引擎中才會出現的信息,而且還需要通過打開ConditionPushdown優化功能
才可能會被使用。控制參數為engine_condition_pushdown。
附:
CREATE TABLE `item` ( `i_id` int(11) NOT NULL, `i_im_id` int(11) DEFAULT NULL, `i_name` varchar(24) DEFAULT NULL, `i_price` decimal(5,2) DEFAULT NULL, `i_data` varchar(50) DEFAULT NULL, PRIMARY KEY (`i_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 ; CREATE TABLE `orders` ( `o_id` int(11) NOT NULL, `o_d_id` tinyint(4) NOT NULL, `o_w_id` smallint(6) NOT NULL, `o_c_id` int(11) DEFAULT NULL, `o_entry_d` datetime DEFAULT NULL, `o_carrier_id` tinyint(4) DEFAULT NULL, `o_ol_cnt` tinyint(4) DEFAULT NULL, `o_all_local` tinyint(4) DEFAULT NULL, PRIMARY KEY (`o_w_id`,`o_d_id`,`o_id`), KEY `idx_orders` (`o_w_id`,`o_d_id`,`o_c_id`,`o_id`), CONSTRAINT `fkey_orders_1` FOREIGN KEY (`o_w_id`, `o_d_id`, `o_c_id`) REFERENCES `customer` (`c_w_id`, `c_d_id`, `c_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1;