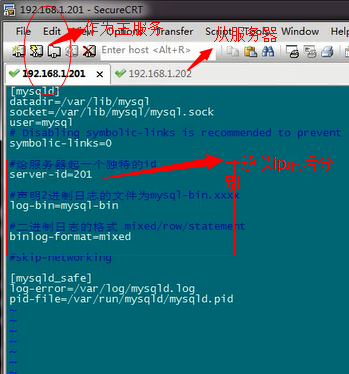
mysql limit大偏移的一個可能的優化方法 mysql limit 語句在大數據量時候,limit後的偏移量過大,第一次查詢會特別慢,因為mysql默認是開啟查詢緩存的,所以,對於第二次再次執行大偏移查詢不會有影響。 示例:100萬的一個表,id做主鍵,auto_increment。 需要查詢:
SELECT * FROM table ORDER BY id DESC LIMIT 990000,100
比較慢。 常見的辦法是:
SELECT * FROM table WHERE id >=(SELECT id FROM table ORDER BY id DESC LIMIT 990000,1) ORDER BY id DESC LIMIT 100
id可能不連續,而且排序也可能不是只依賴於id, 這種辦法基本上無法在實際項目中應用。 比如,我們的實際項目中,有排序非常復雜的方式:
ORDER BY (column1 + column2) * column3 DESC,等等這些方式,一百萬的數據,如果偏移量990000,那麼反過來的排序應該更接近頭部: -------------------------------------------------------------------[99萬-|100條]--100萬 需要實現:
SELECT * FROM table ORDER BY columns DESC LIMIT 990000, 100
推測出一種解決辦法:反向排序,然後截取頭部,再次反向,得到結果:
$head = max(100萬-99萬-100, 0 ); SELECT * FROM (SELECT * FROM table ORDER BY columns ASC LIMIT $head, 100 ) AS t ORDER BY columns DESC
優化完成,對於靠近末尾的,速度和開頭的一樣快,但如果取中間的偏移量,則沒有差別。