MySQL Cluster的高可用性 - 1
使用mysql cluster,能達到99.999的高可靠性,在這一章節,主要介紹一些基本概念:
Network Partitioning
在一個mysql集群中,如果幾個節點之間網絡出問題了,mysql cluster能決定哪些節點應該繼續提供服務。比方有兩個Node Group共四個節點:SN1, SN2,SN2, SN4。
SN1和SN2在Node Group1, SN3和SN4在Node Group2。如果{SN1, SN3}與{SN2, SN4}失去聯系,那麼他們中的任何兩個都擁有完整數據,都能對外提供服務。為了數據完整性,我們必須隔離一半。根據配置,一個或者幾個管理節點能夠提供仲裁,幫助我們選擇哪一對節點繼續存活。假如我們配置了兩個管理節點(MGM1, MGM2)都能提供仲裁服務,我們要避免以下這樣的配置:
路由器1: MGM1, SN1, SN3
路由器2: MGM2, SN2, SN4
如果你有這樣配置,路由器1與路由器2之間出了問題,而MGM1, MGM2都能仲裁,那麼有可能兩邊都在對外提供服務。結果你懂的。
Synchronous Replication: 同步復制。
這比較好理解,在同一個Node Group內部,事務提交為two-phase commit,而且是同步的。每個數據節點內的數據都同步復制到另一個節點上。MySQL Cluster 配置通常至少有 2 個全部數據的副本,存放在不同主機上。為避免整體系統故障,系統會根據可配置的頻率在磁盤上定期保存事務日志和檢查點文件。如果某個節點發生故障,至少有另一個數據節點存儲著相同的信息。
注意:同步復制只是內存的復制,對於mysql cluster來說,他可能還沒有寫到硬盤(與Checkpoint和Redo, UNDO log相關)。如果同一個Node Group同時下電,那麼我們就可能丟數據。Mysql cluster的數據一致性是說我們幾乎沒有兩個節點同時over,所以我們進行部署時最好不要同一個Node Group的data node在同一個機架。
Failure Detection 錯誤檢測。
通常有兩種錯誤,communication loss 和 heartbeat failure。一是通訊丟失,可以通過tcp,共享內存等方式在各存儲節點之間通訊來偵測節點是否正常這種方式是最快的故障檢測方式,
二是心跳失敗,通訊丟失的檢測方法在某些特殊情況下無效,例如磁盤故障等問題.所有的存儲節點通過組成一個環路,每個節點向下一個節點發送心跳信號,如果下一個節點沒有收到心跳信號,則認為上一個存儲節點故障,並依次向下下個節點廣播此故障信息
Logging:
正常情況下,不管什麼類型的數據庫,都會有日志,它包含所有的insert/update/delete。在系統出現故障的時候我們用它來輔助恢復數據庫。
Local Checkpoints:
Redo log是一個環形日志文件,隨著數據庫的操作,redo log也在增長,如果不及時清理的話,log空間很快就會用光,我們需要及時地把snapshot image寫到disk,然後把redo log的tail指針向前挪。NoOfFragmentLogFiles用來控制redo log的大小,TimeBetweenLocalCheckpoints控制cluster local checkpoint的頻率。這兒的Time並不指時間,而是指操作的個數,它是以指數形式增長的,比方20是4M的寫操作,但是21就是8M。
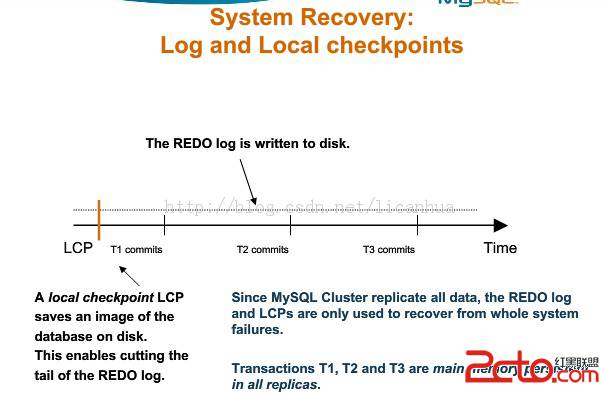 Global Checkpoints:
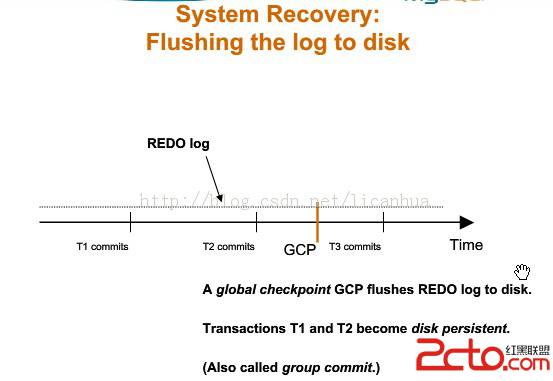
Mysql cluster是一個in-memory數據庫,為了性能的關系,事務都是先同步到內存,然後後面寫log。GlobalCheckpoints就是每隔一段時間TimeBetweenGlobalCheckpoints,我們把一組提交的事務寫到disk。Global Checkpoint就是定時將Redo log寫到disk。
Global Checkpoint是寫Redo log,Local Checkpoint是截Redo log的尾。
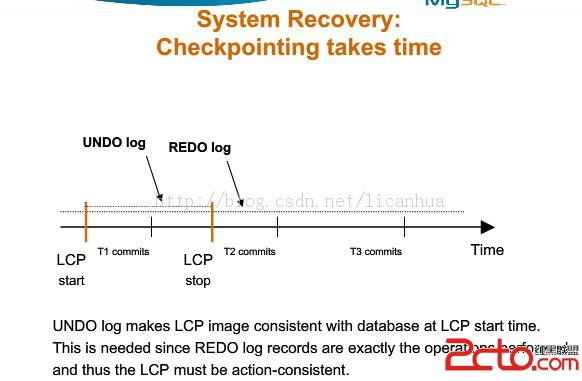
Local check需要時間,為了能夠恢復的時候LCP image與LCP開始時間完全一致,mysql cluster引入Undo log。
Global Checkpoints:
Mysql cluster是一個in-memory數據庫,為了性能的關系,事務都是先同步到內存,然後後面寫log。GlobalCheckpoints就是每隔一段時間TimeBetweenGlobalCheckpoints,我們把一組提交的事務寫到disk。Global Checkpoint就是定時將Redo log寫到disk。
Global Checkpoint是寫Redo log,Local Checkpoint是截Redo log的尾。
Local check需要時間,為了能夠恢復的時候LCP image與LCP開始時間完全一致,mysql cluster引入Undo log。
 System Recovery 系統恢復:
當恢復的時候,LCP image是LCP stop點的數據,我們執行undo log使系統回退到LCP start點。然後執行Redo log到Global checkpoint點。
System Recovery 系統恢復:
當恢復的時候,LCP image是LCP stop點的數據,我們執行undo log使系統回退到LCP start點。然後執行Redo log到Global checkpoint點。
 跨地域復制 — 跨地域復制使節點能鏡像到遠程數據中心以便進行災難恢復
限制
不支持磁盤上的持續提交。提交將被復制,但不保證在提交時會將日志寫入磁盤。
不能在線增加或捨棄節點(此時必須重啟簇)
跨地域復制 — 跨地域復制使節點能鏡像到遠程數據中心以便進行災難恢復
限制
不支持磁盤上的持續提交。提交將被復制,但不保證在提交時會將日志寫入磁盤。
不能在線增加或捨棄節點(此時必須重啟簇)