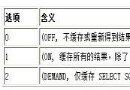
explain的語法如下:
explain [extended] select … from … where …
如果使用了extended,那麼在執行完explain語句後,可以使用show warnings語句查詢相應的優化信息。
比如我們執行 select uid from user where uname=’scofield’ order by uid 執行結果會有
+—-+————-+——-+——-+——————-+———+———+——-+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——-+——-+——————-+———+———+——-+——+——-+
依次是 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般情況,至少要達到 range 級別,最好是 ref 級別。否則可能會有性能問題。
possible_keys 是指可以應用到該表的索引,如果為NULL則沒有。
key 是指用到的索引。
key_len 是索引的長度,在不影響查詢精度的情況下,值越小越好。
ref 是指索引的那一列被使用了。一般會是個常數。
rows 是指有多少行。
extra 是指額外的信息。也是比較重要的。如果值為 distinct ,說明mysql教程 找到了域行聯合匹配的行,就不再查找了。
如果值為 not exits : mysql優化了 left join ,一旦找到了 left join 匹配的行,便不再進行搜索了。
如果值為 rang checked for each : 沒有找到理想的索引。
如果為 using filesort ,則需要改進sql了。這說明 mysql執行 需要 文件排序。這是比較影響效率的。
如果為 using temporary , 這是使用了 臨時表。 這種情況也比較影響效率,sql需要改進。或者從應用層進行改進。
如果為 where used 說明使用了where語句。如果 type為 all 或者 index ,一般會出現這樣的結果。這樣的問題,一般是查詢需要改進。
在一般稍大的系統中,基本盡可能的減少 join ,子查詢 等等。mysql就使用最簡單的查詢,這樣效率最高。至於 join 等,可以放在應用層去解決。
其中,
type=const表示通過索引一次就找到了,
key=primary的話,表示使用了主鍵
type=all,表示為全表掃描,
key=null表示沒用到索引;
type=ref,因為這時認為是多個匹配行,在聯合查詢中,一般為REF
2 MYSQL中的組合索引
假設表有id,key1,key2,key3,把三者形成一個組合索引,則
如:
where key1=....
where key1=1 and key2=2
where key1=3 and key3=3 and key2=2
根據最左原則,這些都是可以使用索引的哦
如
from test where key1=1 order by key3
用explain分析的話,只用到了normal_key索引,但只對where子句起作用,而後面的order by需要排序
3 使用慢查詢分析:
在my.ini中:
long_query_time=1
log-slow-queries=d:mysql5logsmysqlslow.log
把超過1秒的記錄在慢查詢日志中
可以用mysqlsla來分析之。也可以在mysqlreport中,有如
DMS 分別分析了select ,update,insert,delete,replace等所占的百份比
4 MYISAM和INNODB的鎖定
myisam中,注意是表鎖來的,比如在多個UPDATE操作後,再SELECT時,會發現SELECT操作被鎖定了,必須等所有UPDATE操作完畢後,再能SELECT
innodb的話則不同了,用的是行鎖,不存在上面問題。
5 MYSQL的事務配置項
innodb_flush_log_at_trx_commit=1
表示事務提交時立即把事務日志寫入磁盤,同時數據和索引也更新
innodb_flush_log_at_trx_commit=0
事務提交時,不立即把事務日志寫入磁盤,每隔1秒寫一次
innodb_flush_log_at_trx_commit=2
事務提交時,立即寫入磁盤文件(這裡只是寫入到內核緩沖區,但不立即刷新到磁盤,而是每隔1秒刷新到盤,同時更新數據和索引
explain用法
EXPLAIN tbl_name
或:
EXPLAIN [EXTENDED] SELECT select_options
前者可以得出一個表的字段結構等等,後者主要是給出相關的一些索引信息,而今天要講述的重點是後者。
舉例
mysql> explain select * from event;
+—-+————-+——-+——+—————+——+———+——+——+——-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+—-+————-+——-+——+—————+——+———+——+——+——-+
| 1 | SIMPLE | event | ALL | NULL | NULL | NULL | NULL | 13 | |
+—-+————-+——-+——+—————+——+———+——+——+——-+
1 row in set (0.00 sec)
各個屬性的含義
id
select查詢的序列號
select_type
select查詢的類型,主要是區別普通查詢和聯合查詢、子查詢之類的復雜查詢。
table
輸出的行所引用的表。
type
聯合查詢所使用的類型。
type顯示的是訪問類型,是較為重要的一個指標,結果值從好到壞依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般來說,得保證查詢至少達到range級別,最好能達到ref。
possible_keys
指出MySQL能使用哪個索引在該表中找到行。如果是空的,沒有相關的索引。這時要提高性能,可通過檢驗WHERE子句,看是否引用某些字段,或者檢查字段不是適合索引。
key
顯示MySQL實際決定使用的鍵。如果沒有索引被選擇,鍵是NULL。
key_len
顯示MySQL決定使用的鍵長度。如果鍵是NULL,長度就是NULL。文檔提示特別注意這個值可以得出一個多重主鍵裡mysql實際使用了哪一部分。
ref
顯示哪個字段或常數與key一起被使用。
rows
這個數表示mysql要遍歷多少數據才能找到,在innodb上是不准確的。
Extra
如果是Only index,這意味著信息只用索引樹中的信息檢索出的,這比掃描整個表要快。
如果是where used,就是使用上了where限制。
如果是impossible where 表示用不著where,一般就是沒查出來啥。
如果此信息顯示Using filesort或者Using temporary的話會很吃力,WHERE和ORDER BY的索引經常無法兼顧,如果按照WHERE來確定索引,那麼在ORDER BY時,就必然會引起Using filesort,這就要看是先過濾再排序劃算,還是先排序再過濾劃算。
常見的一些名詞解釋
Using filesort
MySQL需要額外的一次傳遞,以找出如何按排序順序檢索行。
Using index
從只使用索引樹中的信息而不需要進一步搜索讀取實際的行來檢索表中的列信息。
Using temporary
為了解決查詢,MySQL需要創建一個臨時表來容納結果。
ref
對於每個來自於前面的表的行組合,所有有匹配索引值的行將從這張表中讀取
ALL
完全沒有索引的情況,性能非常地差勁。
index
與ALL相同,除了只有索引樹被掃描。這通常比ALL快,因為索引文件通常比數據文件小。
SIMPLE
簡單SELECT(不使用UNION或子查詢)