1、使用索引來更快地遍歷表。
缺省情況下建立的索引是非群集索引,但有時它並不是最佳的。在非群集索引下,數據在物理上隨機存放在數據頁上。
合理的索引設計要建立在對各種查詢的分析和預測上。一般來說:
a.有大量重復值、且經常有范圍查詢( > ,< ,> =,< =)和order by、group by發生的列,可考慮建立群集索引;
b.經常同時存取多列,且每列都含有重復值可考慮建立組合索引;
c.組合索引要盡量使關鍵查詢形成索引覆蓋,其前導列一定是使用最頻繁的列。索引雖有助於提高性能但不是索引
越多越好,恰好相反過多的索引會導致系統低效。用戶在表中每加進一個索引,維護索引集合就要做相應的更新工作。
2、在海量查詢時盡量少用格式轉換。
3、ORDER BY和GROPU BY使用ORDER BY和GROUP BY短語,任何一種索引都有助於SELECT的性能提高。
4、任何對列的操作都將導致表掃描,它包括數據庫函數、計算表達式等等,查詢時要盡可能將操作移至等號右邊。
5、IN、OR子句常會使用工作表,使索引失效。如果不產生大量重復值,可以考慮把子句拆開。拆開的子句中應該包含索引。
6、只要能滿足你的需求,應盡可能使用更小的數據類型:例如使用MEDIUMINT代替INT
7、盡量把所有的列設置為NOT NULL,如果你要保存NULL,手動去設置它,而不是把它設為默認值。
8、盡量少用VARCHAR、TEXT、BLOB類型
9、如果你的數據只有你所知的少量的幾個。最好使用ENUM類型
10、正如graymice所講的那樣,建立索引。
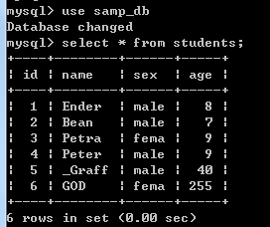
以下是我做的一個實驗,可以發現索引能極大地提高查詢的效率(我有一個會員信息表users,裡邊有37365條用戶記錄)
在不加索引的時候進行查詢:
sql語句A:
select * from users where username like '%許%';
在Mysql-Front中的8次查詢時長為:1.40,0.54,0.54,0.54,0.53,0.55,0.54 共找到960條記錄
sql語句B:
select * from users where username like '許%';
在Mysql-Front中的8次查詢時長為:0.53,0.53,0.53,0.54,0.53,0.53,0.54,0.54 共找到836條記錄
sql語句C:
select * from users where username like '%許';
在Mysql-Front中的8次查詢時長為:0.51,0.51,0.52,0.52,0.51,0.51,0.52,0.51 共找到7條記錄
為username列添加索引:
create index usernameindex on users(username(6));
再次查詢:
sql語句A:
select * from users where username like '%許%';
在Mysql-Front中的8次查詢時長為:0.35,0.34,0.34,0.35,0.34,0.34,0.35,0.34 共找到960條記錄
sql語句B:
select * from users where username like '許%';
在Mysql-Front中的8次查詢時長為:0.06,0.07,0.07,0.07,0.07,0.07,0.06,0.06 共找到836條記錄
sql語句C:
select * from users where username like '%許';
在Mysql-Front中的8次查詢時長為:0.32,0.31,0.31,0.32,0.31,0.32,0.31,0.31 共找到7條記錄
在實驗過程中,我沒有另開任何程序,以上的數據說明在單表查詢中,建立索引的可以極大地提高查詢速度。
另外要說的是如果建立了索引,對於like '許%'類型的查詢,速度提升是最明顯的。因此,我們在寫sql語句的
時候也盡量采用這種方式查詢。
對於多表查詢我們的優化原則是:
盡量將索引建立在:left join on/right join on ... +條件,的條件語句中所涉及的字段上。多表查詢比單表查
詢更能體現索引的優勢。
11、索引的建立原則:
如果一列的中數據的前綴重復值很少,我們最好就只索引這個前綴。Mysql支持這種索引。我在上面用到的索
引方法就是對username最左邊的6個字符進行索引。索引越短,占用的 磁盤空間越少,在檢索過程中花的時
間也越少。這方法可以對最多左255個字符進行索引。
在很多場合,我們可以給建立多列數據建立索引。
索引應該建立在查詢條件中進行比較的字段上,而不是建立在我們要找出來並且顯示的字段上
12、一往情深問到的問題
IN、OR子句常會使用工作表,使索引失效。如果不產生大量重復值,可以考慮把子句拆開。拆開的子句中應該包含索引。
這句話怎麼理解決,請舉個例子
如下:
如果在fields1和fields2上同時建立了索引,fields1為主索引
以下sql會用到索引
select * from tablename1 where fields1='value1' and fields2='value2'
以下sql不會用到索引
select * from tablename1 where fields1='value1' or fields2='value2'
13.索引帶來查詢上的速度的大大提升,但索引也占用了額外的硬盤空間(當然現在一般硬盤空間不成問題),
而且往表中插入新記錄時索引也要隨著更新這也需要一定時間.
有些表如果經常insert,而較少select,就不用加索引了.不然每次寫入數據都要重新改寫索引,花費時間; 這個視
實際情況而定,通常情況下索引是必需的.
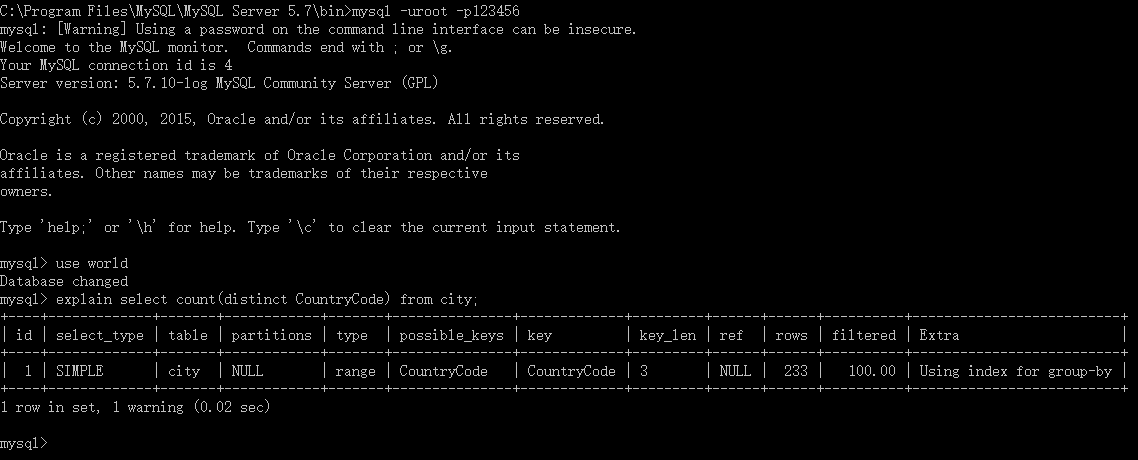
14.我在對查詢效率有懷疑的時候,一般是直接用Mysql的Explain來跟蹤查詢情況.
你用Mysql-Front是通過時長來比較,我覺得如果從查詢時掃描字段的次數來比較更精確一些.
1,創建索引
對於查詢占主要的應用來說,索引顯得尤為重要。很多時候性能問題很簡單的就是因為我們忘了添加索引而造成的,或者說沒有添加更為有效的索引導致。如果不加
索引的話,那麼查找任何哪怕只是一條特定的數據都會進行一次全表掃描,如果一張表的數據量很大而符合條件的結果又很少,那麼不加索引會引起致命的性能下
降。但是也不是什麼情況都非得建索引不可,比如性別可能就只有兩個值,建索引不僅沒什麼優勢,還會影響到更新速度,這被稱為過度索引。
2,復合索引
比如有一條語句是這樣的:select * from users where area=’beijing’ and age=22;
如果我們是在area和age上分別創建單個索引的話,由於mysql查詢每次只能使用一個索引,所以雖然這樣已經相對不做索引時全表掃描提高了很多效
率,但是如果在area、age兩列上創建復合索引的話將帶來更高的效率。如果我們創建了(area, age,
salary)的復合索引,那麼其實相當於創建了(area,age,salary)、(area,age)、(area)三個索引,這被稱為最佳左前綴
特性。因此我們在創建復合索引時應該將最常用作限制條件的列放在最左邊,依次遞減。
3,索引不會包含有NULL值的列
只要列中包含有NULL值都將不會被包含在索引中,復合索引中只要有一列含有NULL值,那麼這一列對於此復合索引就是無效的。所以我們在數據庫設計時不要讓字段的默認值為NULL。
4,使用短索引
對串列進行索引,如果可能應該指定一個前綴長度。例如,如果有一個CHAR(255)的 列,如果在前10 個或20 個字符內,多數值是惟一的,那麼就不要對整個列進行索引。短索引不僅可以提高查詢速度而且可以節省磁盤空間和I/O操作。
5,排序的索引問題
mysql查詢只使用一個索引,因此如果where子句中已經使用了索引的話,那麼order by中的列是不會使用索引的。因此數據庫默認排序可以符合要求的情況下不要使用排序操作;盡量不要包含多個列的排序,如果需要最好給這些列創建復合索引。
6,like語句操作
一般情況下不鼓勵使用like操作,如果非使用不可,如何使用也是一個問題。like “%aaa%” 不會使用索引而like “aaa%”可以使用索引。
7,不要在列上進行運算
select * from users where
YEAR(adddate)
8,不使用NOT IN和操作