如果你需要進行mysql分表了我們就證明你數據庫比較大了,就是把一張表分成N多個小表,分表後,單表的並發能力提高了,磁盤I/O性能也提高了。並發能力為什麼提高了 呢,因為查尋一次所花的時間變短了,如果出現高並發的話,總表可以根據不同的查詢,將並發壓力分到不同的小表裡面
什麼是分表,從表面意思上看呢,就是把一張表分成N多個小表
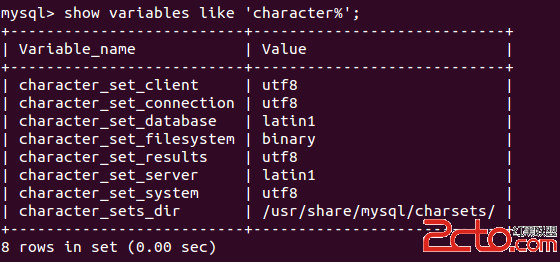
mysql的分表是真正的分表,一張表分成很多表後,每一個小表都是完正的一張表,都對應三個文件,一個.MYD數據文件,.MYI索引文件,.frm表結構文件。
1.[root@BlackGhost test]# ls |grep user
2.alluser.MRG
3.alluser.frm
4.user1.MYD
5.user1.MYI
6.user1.frm
7.user2.MYD
8.user2.MYI
9.user2.frm
1,做mysql集群,例如:利用mysql cluster ,mysql proxy,mysql replication,drdb等等
有人會問mysql集群,根分表有什麼關系嗎?雖然它不是實際意義上的分表,但是它啟到 了分表的作用,做集群的意義是什麼呢?為一個數據庫減輕負擔,說白了就是減少sql排隊隊列中的sql的數量,舉個例子:有10個sql請求,如果放在一 個數據庫服務器的排隊隊列中,他要等很長時間,如果把這10個sql請求,分配到5個數據庫服務器的排隊隊列中,一個數據庫服務器的隊列中只有2個,這樣 等待時間是不是大大的縮短了呢?這已經很明顯了。所以我把它列到了分表的范圍以內,我做過一些mysql的集群:
linux mysql proxy 的安裝,配置,以及讀寫分離
mysql replication 互為主從的安裝及配置,以及數據同步
優點:擴展性好,沒有多個分表後的復雜操作(php代碼)
缺點:單個表的數據量還是沒有變,一次操作所花的時間還是那麼多,硬件開銷大。
2,預先估計會出現大數據量並且訪問頻繁的表,將其分為若干個表
這種預估大差不差的,論壇裡面發表帖子的表,時間長了這張表肯定很大,幾十萬,幾百萬都 有可能。 聊天室裡面信息表,幾十個人在一起一聊一個晚上,時間長了,這張表的數據肯定很大。像這樣的情況很多。所以這種能預估出來的大數據量表,我們就事先分出個 N個表,這個N是多少,根據實際情況而定。以聊天信息表為例:
我事先建100個這樣的 表,message_00,message_01,message_02..........message_98,message_99.然後根據用戶 的ID來判斷這個用戶的聊天信息放到哪張表裡面,你可以用hash的方式來獲得,可以用求余的方式來獲得,方法很多,各人想各人的吧。下面用hash的方 法來獲得表名:
代碼如下 復制代碼<?php
function get_hash_table($table,$userid) {
$str = crc32($userid);
if($str<0){
$hash = "0".substr(abs($str), 0, 1);
}else{
$hash = substr($str, 0, 2);
}
return $table."_".$hash;
}
echo get_hash_table('message','user18991'); //結果為message_10
echo get_hash_table('message','user34523'); //結果為message_13
?>說明一下,上面的這個方法,告訴我們user18991這個用戶的消息都記錄在message_10這張表裡,user34523這個用戶的消息都記錄在message_13這張表裡,讀取的時候,只要從各自的表中讀取就行了。
優點:避免一張表出現幾百萬條數據,縮短了一條sql的執行時間
缺點:當一種規則確定時,打破這條規則會很麻煩,上面的例子中我用的hash算法是crc32,如果我現在不想用這個算法了,改用md5後,會使同一個用戶的消息被存儲到不同的表中,這樣數據亂套了。擴展性很差。
提高性能上
a),分表後,單表的並發能力提高了,磁盤I/O性能也提高了。並發能力為什麼提高了 呢,因為查尋一次所花的時間變短了,如果出現高並發的話,總表可以根據不同的查詢,將並發壓力分到不同的小表裡面。磁盤I/O性能怎麼搞高了呢,本來一個 非常大的.MYD文件現在也分攤到各個小表的.MYD中去了。