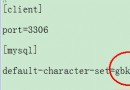
mysql中文亂碼是各種初學這類的常見問題,下面我來給各位同學詳細介紹關於在mysql中文亂碼時的一些解決方法,有需要了解的朋友不防參考。
原因是很多時候,為了安全,不允許mysql管理工具連接線上的正式環境,這樣的情況下,就不能依靠mysql管理工具來轉換編碼來解決中文亂碼的問題。
這樣的情況下只能通過putty或者secureCRT遠程連接mysql server,然後通過mysql命令界面來對mysql數據庫導出,再做其他的編碼轉換操作。我現在面臨的環境就是這樣。
現在,描述一下我的數據情況,我需要導出中文亂碼的數據表account.user:
代碼如下 復制代碼mysql> show create database account;
+———-+——————————————————————————————+
| Database | Create Database |
+———-+——————————————————————————————+
| account | CREATE DATABASE `account` /*!40100 DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci */ |
+———-+——————————————————————————————+
1 row in set (0.00 sec)
mysql> show create table user;
+———————+———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————–+
| Table | Create Table |
+———————+———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————–+
| user_agreement_info | CREATE TABLE `user` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uid` bigint(21) unsigned NOT NULL,
`realname` char(32) NOT NULL,
`id_type` smallint(11) unsigned NOT NULL,
`id_num` char(32) DEFAULT NULL,
`create_time` int(10) unsigned DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `uid` (`uid`)
) ENGINE=MyISAM AUTO_INCREMENT=129287 DEFAULT CHARSET=utf8 |
+———————+———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————–+
1 row in set (0.02 sec)
#查詢數據亂碼,看下面:
mysql> select * from user limit 10;
+—-+————+—————————+———+——————–+————-+
| id | uid | realname | id_type | id_num | create_time |
+—-+————+—————————+———+——————–+————-+
| 23 | 1000001229 | è€é™ˆ | 1 | 410101234567891234 | 1272619237 |
| 2 | 1000001207 | 王文鉴 | 1 | 320211198511261933 | 1272546559 |
| 3 | 1000001208 | 蒋家锋 | 1 | 513023198808294915 | 1272547009 |
| 4 | 1000001209 | zhaojing | 1 | 320822198704286120 | 1272550654 |
| 5 | 1000001210 | 阮å°æ¦ | 1 | 31020619840214283X | 1272562857 |
| 6 | 1000001211 | é»‘å¤œç²¾çµ | 1 | 412723798204103835 | 1272588671 |
| 7 | 1000001212 | 谢勇 | 1 | 330722198408168210 | 1272591799 |
| 8 | 1000001213 | 邵明芳 | 3 | 0621316 | 1272592840 |
| 9 | 1000001215 | 王维纪 | 1 | 330382198611030393 | 1272592959 |
| 10 | 1000001216 | è°ˆå® | 1 | 430721198309272802 | 1272595142 |
+—-+————+—————————+———+——————–+————-+
10 rows in set (0.00 sec)
#數據庫編碼設置情況:
mysql> show variables like ‘%char%’;
+————————–+—————————————-+
| Variable_name | Value |
+————————–+—————————————-+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+————————–+—————————————-+
8 rows in set (0.02 sec)
這是什麼問題呢?
首先我們來看下數據是什麼編碼:
代碼如下 復制代碼mysql> set names latin1;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from user_agreement_info limit 10;
+—-+————+————–+———+——————–+————-+
| id | uid | realname | id_type | id_num | create_time |
+—-+————+————–+———+——————–+————-+
| 23 | 1000001229 | 陳 | 1 | 410101234567891234 | 1272619237 |
| 2 | 1000001207 | 王嘉文 | 1 | 320211198511261933 | 1272546559 |
| 3 | 1000001208 | 網家鋒 | 1 | 513023198808294915 | 1272547009 |
| 4 | 1000001209 | zaojing | 1 | 320822198704286120 | 1272550654 |
| 5 | 1000001210 | 小林 | 1 | 31020619840214283X | 1272562857 |
| 6 | 1000001211 | 黑夜精靈 | 1 | 412723798204103835 | 1272588671 |
| 7 | 1000001212 | 鳳舞 | 1 | 330722198408168210 | 1272591799 |
| 8 | 1000001213 | 邵明芳 | 3 | 0621316 | 1272592840 |
| 9 | 1000001215 | 王維紀 | 1 | 330382198611030393 | 1272592959 |
| 10 | 1000001216 | 談宏 | 1 | 430721198309272802 | 1272595142 |
+—-+————+————–+———+——————–+————-+
10 rows in set (0.01 sec)
現在可以確定了,這個表裡的數據時latin1編碼的。
我們知道如果要mysql中,中文正常顯示,必須要保持編碼一致,我們看到在數據庫裡執行set names latin1之後,中文就能正常顯示,那麼我們就按照這樣的方式導出數據。
代碼如下 復制代碼[root@sh-db1 tmp]# /usr/local/mysql/bin/mysqldump -uroot –opt –default-character-set=latin1 -p654321 account user >/tmp/user.sql
注意這裡的導出參數–default-character-set=latin1,也就是相當於我們在數據導出之前在數據庫裡執行set names latin1;
這樣數據就以sql腳本的方式存在於server上,使用vim查看文件/tmp/user.sql時發現還是亂碼,這是為什麼呢?下面就是原因:
[root@sh-db1 tmp]# locale
LANG=en_US.UTF-8
LC_CTYPE=”en_US.UTF-8″
LC_NUMERIC=”en_US.UTF-8″
LC_TIME=”en_US.UTF-8″
LC_COLLATE=”en_US.UTF-8″
LC_MONETARY=”en_US.UTF-8″
LC_MESSAGES=”en_US.UTF-8″
LC_PAPER=”en_US.UTF-8″
LC_NAME=”en_US.UTF-8″
LC_ADDRESS=”en_US.UTF-8″
LC_TELEPHONE=”en_US.UTF-8″
LC_MEASUREMENT=”en_US.UTF-8″
LC_IDENTIFICATION=”en_US.UTF-8″
LC_ALL=
還有跟你的連接工具的編碼有關系,去查看一下你的putty或者secureCRT連接使用的是什麼編碼,這些不同的編碼就是造成你使用vim查看中文顯示亂碼的原因。
沒有關系,我們使用sz命令把/tmp/user.sql下載到本地,也就是你的windows主機上。
然後使用emedtor或者uedtor,notepad++,vim都可以,打開,發現中文已經可以正常顯示,如果不正常顯示,那就往前看看是不是哪裡做錯了,修改user.sql裡面的內容,set names latin1;修改為set names utf8;然後另存為utf8的編碼形式。
再使用rz上傳到mysql server上,再次使用vim打開,發現中文正常顯示。
代碼如下 復制代碼[root@sh-db1 tmp]# /usr/local/mysql/bin/mysql -uroot -S /tmp/mysql3306.sock -p654321 account < user.sql
登錄mysql查看,中文顯示正常。
後來又總結出一個更簡單辦法
登陸mysql --->
進入相應數據庫--->
代碼如下 復制代碼輸入命令: show variables like '%char%';
得到:
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client utf8
| character_set_connection utf8
| character_set_database latin1
| character_set_filesystem binary
| character_set_results utf8
| character_set_server utf8
| character_set_system utf8
| character_sets_dir D:MySQLsharecharsets
+--------------------------+--------------------------+
如果出現上述情況則需要更改數據庫編碼: 兩種方法, 第一種是一次搞定, 第二種只對當前連接有效,斷開連接,恢復更改前狀態
方法1: alter database 數據庫名 charset utf8;
方法2: set character_set_database = utf8;
再用命令:
代碼如下 復制代碼show variables like '%char%';
+--------------------------+--------------------------+
| Variable_name | Value |
+--------------------------+--------------------------+
| character_set_client utf8
| character_set_connection utf8
| character_set_database utf8
| character_set_filesystem binary
| character_set_results utf8
| character_set_server utf8
| character_set_system utf8
| character_sets_dir D:MySQLsharecharsets
+--------------------------+--------------------------+
此時編碼已經一致, 但是,對數據庫中的表進行插入中文字符操作, 仍然會報 : ERROR 1366 (HY000)
代碼如下 復制代碼---> set character_set_client = gbk; 設置插入時接收的編碼為GBK, 這樣就可以插入中文了
此時中文字符已經可以插入, 但查詢結果卻還是亂碼, 再更改一處即可:
代碼如下 復制代碼---> set character_set_results = gbk; 設置輸出結果的編碼為GBK
注: 這樣的設置只對當前連接有關, 連接斷開, 這些設置恢復數據庫默認設置狀態,因此,如果需要,每次連接都得設置!
另外:ERROR 1366 (HY000)錯誤主要出現於控制台(cmd/黑窗口) 執行SQL語句插入中文時彈出,
用mysql-front 軟件插入時不會報字符問題, java通過JDBC連接數據庫執行executeUpdate("insert 語句") 中文也能成功插入數據且不會報錯!
PHP解決亂碼問題只需在連接後加入mysql_query("set names 'gbk'") 就OK!
如:
代碼如下 復制代碼 $conn = mysql_connect("localhost","root","");