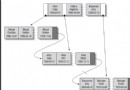
(join/left join/inner join等)時的mysql運算過程;
不要求每個人一定知道線上(現在或未來)哪張表數據量大,哪張表數據量小;
mysql客戶端(如SQLyog,如HeidiSQL)放在桌面上,
在實例講解之前,我們先回顧一下聯表查詢的基礎知識。
下面兩個查詢,它們只差了一個order by,效果卻迥然不同。
第一個查詢:
ads, city
desc
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- -------------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00 Using temporary; Using filesort
1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
第二個查詢:
city
ORDER BY desc
執行計劃裡沒有了using temporary:
id select_type table type possible_keys key key_len ref rows filtered Extra
------ ----------- ------ ------ -------------- ------- ------- -------------------- ------ -------- ---------------------------
1 SIMPLE city ref ads_id,city_id city_id 4 const 2838 100.00
Using where; Using filesort 1 SIMPLE ads eq_ref PRIMARY PRIMARY 4 city.ads_id 1 100.00 Using where
為什麼?
DBA告訴我們:
MySQL 表關聯的算法是 Nest Loop Join,是通過驅動表的結果集作為循環基礎數據,然後一條一條地通過該結果集中的數據作為過濾條件到下一個表中查詢數據,然後合並結果。
以上兩個查詢語句,驅動表都是 city,如上面的執行計劃所示!
對驅動表可以直接排序,
對非驅動表(的字段排序)需要對循環查詢的合並結果(臨時表)進行排序
因此,order by ads.id desc 時,就要先 using temporary 了!
wwh999 在 2006年總結說,當進行多表連接查詢時,
[驅動表] 的定義為:
1)指定了聯接條件時,
滿足查詢條件的記錄行數少的表為[驅動表];
2)行數少的表為[驅動表]
既然“未指定聯接條件時,
行數少的表為[驅動表]”了,
而且你也對自己寫出的復雜的 Nested Loop Join 不太有把握(如下面的實例所示),
就別指定誰 left/right join 誰了,
請交給 MySQL優化器 運行時決定吧。
如果您對自己特別有信心,可以像火丁一樣做優化。
de.cel 在2012年總結說,不管是你,還是 MySQL,
優化的目標是盡可能減少JOIN中Nested Loop的循環次數,
以此保證:
!
先了解一下 mb 表有 千萬級記錄,mbei 表要少得多。慢查實例如下:
LEFT JOIN mbei ON mb.id=mbei.mb_id u ON mb.uid=u.uid
夠復雜吧。Nested Loop Join 就是這樣,
以驅動表的結果集作為循環的基礎數據,然後將結果集中的數據作為過濾條件一條條地到下一個表中查詢數據,最後合並結果;此時還有第三個表,則將前兩個表的 Join 結果集作為循環基礎數據,再一次通過循環查詢條件到第三個表中查詢數據,如此反復。
這條語句的執行計劃如下:
id select_type table type possible_keys key key_len ref rows Extra
------ ----------- ------ ------ -------------- -------------- ------- ------------------- ------- --------------------------------------------
1 SIMPLE
index userid userid 4 (NULL)
Using index;
Using filesort
1 SIMPLE mbei eq_ref mb_id mb_id 4 mb.id 1
1 SIMPLE u eq_ref PRIMARY PRIMARY 4 mb.uid 1 Using index
由於動用了“LEFT JOIN”,所以攻城獅已經指定了驅動表,雖然這張驅動表的結果集記錄數達到百萬級!
.
.
如何優化?
.
.
干嘛要 left join 啊?直接 join!
立竿見影,驅動表立刻變為小表 mbei 了, Using temporary 消失了,影響行數少多了:
id select_type table type possible_keys key key_len ref rows Extra
------ ----------- ------ ------ -------------- ------- ------- ---------------------------- ------ --------------
1 SIMPLE
ALL mb_id (NULL) (NULL) (NULL)
1 SIMPLE mb eq_ref PRIMARY,userid PRIMARY 4 mbei.mb_id 1
1 SIMPLE u eq_ref PRIMARY PRIMARY 4 mb.uid 1 Using index
優化第一步之分支1:根據驅動表的字段排序,好嗎?
left join不變。干嘛要根據非驅動表的字段排序呢?我們前面說過“對驅動表可以直接排序,對非驅動表(的字段排序)需要對循環查詢的合並結果(臨時表)進行排序!”的。
DESC
也滿足業務場景,做到了rows最小:
id select_type table type possible_keys key key_len ref rows Extra
------ ----------- ------ ------ -------------- -------------- ------- ------------------- ------ -----------
1 SIMPLE mb index userid PRIMARY 4 (NULL)
1 SIMPLE mbei eq_ref mb_id mb_id 4 mb.id 1 Using index
1 SIMPLE u eq_ref PRIMARY PRIMARY 4 mb.uid 1 Using index
優化第二步:去除所有JOIN,讓MySQL自行決定!
寫這麼多密密麻麻的 left join/inner join 很開心嗎?
id select_type table type possible_keys key key_len ref rows Extra
------ ----------- ------ ------ -------------- ------- ------- ---------------------------- ------ --------------
1 SIMPLE ALL mb_id (NULL) (NULL) (NULL)
1 SIMPLE mb eq_ref PRIMARY,userid PRIMARY 4 mbei.mb_id 1
1 SIMPLE u eq_ref PRIMARY PRIMARY 4 mb.uid 1 Using index
最後的總結:
強調再強調:
記住,explain 是一種美德!
參考資源:
1)wwh999,2006,進行多表查時的排序問題,其多表查詢時的原理論證! ;
2)de.cel,2012,MySQL中的Join 原理及優化思路 ;
3)火丁,2013,MySQL優化的奇技淫巧之STRAIGHT_JOIN;
贈圖一枚: