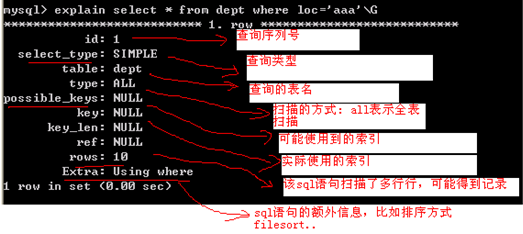
EXPLAIN 是mysql解釋select查詢的一個關鍵字,可以很方便的用於調試
語法格式如下
EXPLAIN tbl_name
或者:
EXPLAIN SELECT select_options
EXPLAIN 語句可以被當作 DESCRIBE 的同義詞來用,也可以用來獲取一個MySQL要執行的 SELECT 語句的相關信息。
EXPLAIN tbl_name 語法和 DESCRIBE tbl_name 或 SHOW COLUMNS FROM tbl_name 一樣。
當在一個 SELECT 語句前使用關鍵字 EXPLAIN 時,MYSQL會解釋了即將如何運行該 SELECT 語句,它顯示了表如何連接、連接的順序等信息。
以下信息為引用:
在explain我們所使用的sql的時候,經常會遇到using filesort這種情況,原以為是由於有相同列值的原因引起,結果昨天看到公司的一個sql,跟同事討論了下加上自己又做了一些測試,突然發現自己原來的想法是錯誤的。
首先,只有在order by 數據列的時候才可能會出現using filesort,而且如果你不對進行order by的這一列設置索引的話,無論列值是否有相同的都會出現using filesort。因此,只要用到order by 的這一列都應該為其建立一個索引。
其次,在這次測試中,使用了一個稍微有點復雜的例子來說明這個問題,下面詳細用這個例子說一下:
SELECT * FROM DB.TB WHERE ID=2222 AND FID IN (9,8,3,13,38,40) ORDER BY INVERSE_DATE LIMIT 0, 5
裡面建立的索引為一個三列的多列索引:IDX(ID,FID ,INVERSE_DATE) 。INVERSE_DATE這個是時間的反向索引。
對於這個sql我當時最開始認為應該是個優化好的狀態,應該沒有什麼纰漏了,結果一explain才發現竟然出現了:Using where; Using filesort。
為什麼呢,後來經過分析才得知,原來在多列索引在建立的時候是以B-樹結構建立的,因此建立索引的時候是先建立ID的按順序排的索引,在相同ID的情況下建立FID按 順序排的索引,最後在FID 相同的情況下建立按INVERSE_DATE順序排的索引,如果列數更多以此類推。有了這個理論依據我們可以看出在這個sql使用這個IDX索引的時候只是用在了order by之前,order by INVERSE_DATE 實際上是using filesort出來的。。汗死了。。因此如果我們要在優化一下這個sql就應該為它建立另一個索引IDX(ID,INVERSE_DATE),這樣就消除了using filesort速度也會快很多。問題終於解決了。