使用索引提高查詢速度
1.前言
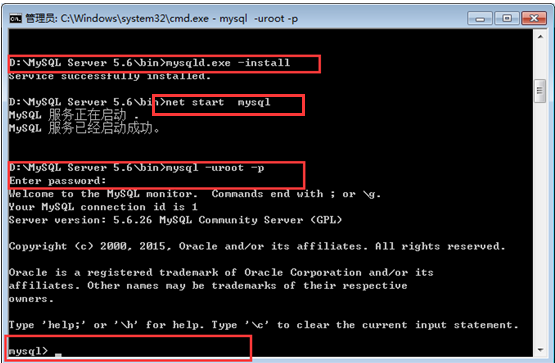
在web開發中,頁面模板,業務邏輯(包括緩存、連接池)和數據庫這三個部分,數據庫在其中負責執行SQL查詢並返回查詢結果,是影響網站速度最重要的性能瓶頸。本文主要針對MySql數據庫,雙十一的電商大戰,引發了淘寶技術熱議,而淘寶現在去IOE(I代表IBM的縮寫,即去IBM的存儲設備和小型機;O是代表Oracle的縮寫,也即去Oracle數據庫,采用MySQL和Hadoop替代的解決方案,;E是代表EMC2,即去EMC2的設備性,用PC Server替代EMC2),大量采用MySql集群!讓MySql再次成為耀眼的明星!而優化數據的重要一步就是索引的建立,對於mysql中出現的慢查詢,我們可以通過使用索引來提升查詢速度。索引用於快速找出在某個列中有一特定值的行。不使用索引,MySQL將進行全表掃描,從第1條記錄開始然後讀完整個表直到找出相關的行。
2.mysql索引類型及創建
常用的索引類型有
(1)主鍵索引
它是一種特殊的唯一索引,不允許有空值。一般是在建表的時候同時創建主鍵索引:
復制代碼 代碼如下:
CREATE TABLE user(
id int unsigned not null auto_increment,
name varchar(50) not null,
email varchar(40) not null,
primary key (id)
);
(2)普通索引
這是最基本的索引,它沒有任何限制。創建方式:
復制代碼 代碼如下:
create index idx_name on user(
name(20)
);
mysql支持前綴索引,一般姓名不會超過20個字符,所以我們這裡建立索引的時候限定了長度20,這樣可以節省索引文件大小
(3)唯一索引
它與前面的普通索引類似,不同的就是:索引列的值必須唯一,但允許有空值。如果是組合索引,則列值的組合必須唯一。創建方式:
復制代碼 代碼如下:
CREATE UNIQUE INDEX idx_email ON user(
email
);
(4)全文索引
MySQL支持全文索引和搜索功能。MySQL中的全文索引類型為FULLTEXT的索引。 FULLTEXT 索引僅可用於 MyISAM表;
復制代碼 代碼如下:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
);
mysql> SELECT * FROM articles WHERE MATCH (title,body) AGAINST ('database');
查詢結果:
+----+-------------------+------------------------------------------+
| id | title | body |
+----+-------------------+------------------------------------------+
| 5 | MySQL vs. YourSQL | In the following database comparison ... |
| 1 | MySQL Tutorial | DBMS stands for DataBase ... |
+----+-------------------+------------------------------------------+
2 rows in set (0.00 sec)
MATCH()函數對於一個字符串執行資料庫內的自然語言搜索。一個資料庫就是1套1個或2個包含在FULLTEXT內的列。搜索字符串作為對AGAINST()的參數而被給定。對於表中的每一行, MATCH() 返回一個相關值,即, 搜索字符串和 MATCH()表中指定列中該行文字之間的一個相似性度量。
(5)復合索引
復制代碼 代碼如下:
CREATE TABLE test (
id INT NOT NULL,
last_name CHAR(30) NOT NULL,
first_name CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (last_name,first_name)
);
name索引是一個對last_name和first_name的索引。索引可以用於為last_name,或者為last_name和first_name在已知范圍內指定值的查詢。因此,name索引用於下面的查詢:
SELECT * FROM test WHERE last_name='Widenius';
SELECT * FROM test WHERE last_name='Widenius' AND first_name='Michael';
但是不能用於SELECT * FROM test WHERE first_name='Michael';這是因為MySQL組合索引為“最左前綴”的結果,簡單的理解就是只從最左面的開始組合。
3.在什麼情況下使用索引
(1)為搜索字段建索引,如果在你的表中,某個字段你經常用來做搜索,那麼,請為其建立索引吧。一般來說,在WHERE和JOIN中出現的列需要建立索引以提高查詢速度。
例如從fps表(表中有name字段)中檢索姓名為"李武"的人,
下面用explain來解釋執行建立索引和未建立索引的區別:
a.未建立索引前
復制代碼 代碼如下:
explain select name from fps where name="李武";
[SQL] select name from fps where name="李武";
影響的數據欄: 0
create index idx_name on fps(
name
);
explain select name from fps where name="李武";
[SQL] select name from fps where name="李武";
影響的數據欄: 0
時間: 0.001ms
(2)下面我們就來看看這個EXPLAIN分析結果的含義。
table:這是表的名字。
type:連接操作的類型。下面是MySQL文檔關於ref連接類型的說明:
“對於每個來自於前面的表的行組合,所有有匹配索引值的行將從這張表中讀取。如果聯接只使用鍵的最左邊的前綴,或如果鍵不是
UNIQUE或PRIMARY KEY(換句話說,如果聯接不能基於關鍵字選擇單個行的話),則使用ref。如果使用的鍵僅僅匹配少量行,該聯接
類型是不錯的。” 在本例中,由於索引不是UNIQUE類型,ref是我們能夠得到的最好連接類型。 如果EXPLAIN顯示連接類型是“ALL”,而且你並不想從表裡面選擇出大多數記錄,那麼MySQL的操作效率將非常低,因為它要掃描整個表。你可以加入更多的索引來解決這個問題。預知更多信息,請參見MySQL的手冊說明。
possible_keys:
可能可以利用的索引的名字。這裡的索引名字是創建索引時指定的索引昵稱;如果索引沒有昵稱,則默認顯示的是索引中第一個列的名字
(在本例中,它是“idx_name”)。
Key:
它顯示了MySQL實際使用的索引的名字。如果它為空(或NULL),則MySQL不使用索引。
key_len:
索引中被使用部分的長度,以字節計。
ref:
它顯示的是列的名字(或單詞“const”),MySQL將根據這些列來選擇行。在本例中,MySQL根據三個常量選擇行。
rows:
MySQL所認為的它在找到正確的結果之前必須掃描的記錄數。顯然,這裡最理想的數字就是1。 本例中未索引前遍歷的記錄數為1041,而建立索引後為1
Extra:
這裡可能出現許多不同的選項,其中大多數將對查詢產生負面影響。在本例中,MySQL只是提醒我們它將用using where,using index子句限制搜索結果集。
4.最常用的存儲引擎:
(1)Myisam存儲引擎:每個Myisam在磁盤上存儲成三個文件。文件名都和表名相同,擴展名分別為.frm(存儲表定義)、.MYD(存儲數據)、.MYI(存儲索引)。數據文件和索引文件可以放置在不同目錄,平均分布io,獲得更快的速度。對存儲大小沒有限制,MySQL數據庫的最大有效表尺寸通常是由操作系統對文件大小的限制決定的,
(2)InnoDB存儲引擎:具有提交、回滾、奔潰恢復能力的事務安全。與Myisam相比,InnoDB的寫效率差一些並且會占用更多的磁盤空間以保留數據和索引。
(3)如何選擇合適的引擎
下面是常用存儲引擎適用的環境:
Myisam:它是在Web、數據倉儲和其他應用環境下最常使用的存儲引擎;
InnoDB:用於事務處理應用程序,具有更多特性,包括ACID事務特性。