1> 查詢數據表除了前三條以外的數據。
起初我想到的是這條語句
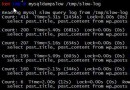
SELECT * FROM admin WHERE userid NOT IN (SELECT userid FROM admin ORDER BY userid LIMIT 3) ORDER BY userid DESC
但是運行的時候會報 This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery
這個的意思是表示子查詢的時候不支持limit ,還有一點我就是很二了 就是查詢的時候用not in 效率非常不高
最後的解決辦法是
CREATE VIEW view_top3_admin AS SELECT * FROM admin ORDER BY userid LIMIT 3;
先創建一個視圖 將子查詢條件放到視圖裡面
然後在用這條語句
SELECT * FROM admin a WHERE NOT EXISTS (SELECT 1 FROM view_top3_admin b WHERE b.userid=a.userid ) ORDER BY a.userid DESC
先來解釋下這條語句 SELECT 1 FROM view_top3_admin b WHERE b.userid=a.userid 表示查詢表裡面的值 只要有數據都顯示為 1,1表示不讀取數據
這樣的話就是提升了查詢的性能,當然也可以把 裡面的1 換成 null 性能是一致的。整條語句的意思是查詢admin表值, 判斷條件是值不在子查詢表裡的。
2 > union 和 union all 的使用
先來解釋下這兩個關鍵字在mysql數據庫中提供了UNION和UNION ALL關鍵字,這兩個關鍵字都是將結果集合並為一個,但這兩者從使用和效率上來說都有所不同
UNION在進行表鏈接後會篩選掉重復的記錄,所以在表鏈接後會對所產生的結果集進行排序運算,刪除重復的記錄再返回結果。
select * from table union select * from tabl
UNION ALL只是簡單的將兩個結果合並後就返回 如果返回的兩個結果集中有重復的數據,那麼返回的結果集就會包含重復的數據了
select * from table union all select * from tabl
從效率上說,UNION ALL 要比UNION快很多,所以,如果可以確認合並的兩個結果集中不包含重復的數據的話,那麼就使用UNION
這兩個關鍵字用做報表比較多